
Week 4: The Data Science Landscape
[reveal]
Abstract:
This lecture will introduce us to the context of why we are doing data science. What is data science and how does it differ from classical statistics, machine learning and artificial intelligence. We will set the context by introducing the notion of embodiment factors. These factors allow us to characterize human and machine intelligence and highlight that in the modern data driven world a symbiotic relationship with the machine is emerging. Unfortunately, the high bandwidth capability of the machine means that it has at a disadvantage. Just as the field of mathematical statistics developed to mediate the relationship between humans and data, the field of data science is emerging to mediate the relationship between human machine and data. This background will give the context to what will follow in the rest of the course where you will gain practical skills and experience of developing the full data science pipeline.
Course Overview
Advanced Data Science is a four-week unit that will give you both a broad overview of the challenges of data science as well as a deep understanding of the stages involved in delivering a data science pipeline.
Welcome to this course!
Introduction
The course is lectured by Carl Henrik Ek and Christian Cabrera and Neil D. Lawrence
An Emerging Field
Data science is an emerging field, in this unit we’ll introduce you to the phenomena that are triggering it, and the challenges we face. It is not an activity that is currently done well. In some places it is done better than others, but there’s a particular onus on us as educators, and you as students, to realize that our understanding of the challenge is evolving. That evolving understanding requires us to adapt to the problems as they develop and maintain a wider contextual understanding of the effects we are having on society.
For that reason, the unit is not purely technical, it is at times philosophical and ethical. That is not to say we have a unique access to the philosophies and ethics that are required to undertake the challenges of data science, but to trigger your thinking because you are in the generation of computer scientists on whom the burden of responsibility is falling to address these challenges.
Your assessments are designed to develop these skills alongside your technical understanding. They are ambitious in their scope, but unless you see the entire data science pipeline you won’t be prepared to assimilate the challenges we’re facing. Our aim is to guide you through the challenges of the assessment through the lab sessions and practicals and to ensure that you develop your understanding of these challenges with our help.
The teaching is based not only on technical experience of the machine learning community, but real-world experience of deploying and/or assisting with deployments of data science solutions at Amazon, for pandemic policy advice and in the African context (particularly Uganda and Kenya).
Dates are as follows:
| Activity | Release Date (in Moodle) | Due Date (in Moodle) | Check Date (in the Lab) |
|---|---|---|---|
| Refresher 1 | 01/11/2024 12:00 | - | - |
| Practical 1 | 04/11/2024 17:00 | 07/11/2024 12:00 | 07/11/2024 15:00 |
| Practical 2 | 07/11/2024 15:00 | 12/11/2024 12:00 | 12/11/2024 15:00 |
| Refresher 2 | 12/11/2024 15:00 | - | - |
| Practical 3 | 12/11/2024 15:00 | 21/11/2024 12:00 | 21/11/2024 15:00 |
| Practical 4 (Assessment) | 21/11/2024 15:00 | 03/12/2024 12:00 | 03/12/2024 15:00 |
| Final Report | 21/11/2024 15:00 | 06/12/2024 12:00 | - |
Week 4
- The Data Science Landscape. Lecturer: Neil D. Lawrence 2024-11-01
- AI and Data Science. Lecturer: Neil D. Lawrence 2024-11-04
- Systems and Data Oriented Architecture. Lecturer: Christian Cabrera 2024-11-06
Lab Session One 2024-11-05 (Review and Refresher) Practical 1: 2024-11-07 Access
Week 5
- AI Deployment Challenges. Lecturer: Christian Cabrera 2024-11-08
- Assess. Lecturer: Neil D. Lawrence 2024-11-11
- Visualisation. Lecturer: Neil D. Lawrence 2024-11-13
Practical 2: 2024-11-12 Access and Assess (also hand in Practical 1 & Practical One Check)
Week 6
- Introduction to Statistical Learning: Neil D. Lawrence 2024-11-15
- Generalised Linear Models: Neil D. Lawrence 2024-11-18
Practical 3: 2024-11-19 Assess and Address (also hand in Practical 2 & Check) Practical 4: 2024-11-21 Address (also hand in Practical 3 & Check)
Week 7
- Summary and Assignment: 2024-11-24
Week 8
- Assignment hand in 2024-12-03
Assessment
Your assessment will be available in Moodle. The assessment is tightly integrated with the course lecturing, it is staged so that you should be able to make a start on the first question as soon as you’ve finished Lab Session One. Your assessment should progress alongside the course with different questions becoming easier to answer as you complete each of the labs.
Henry Ford’s Faster Horse


Figure: A 1925 Ford Model T built at Henry Ford’s Highland Park Plant in Dearborn, Michigan. This example now resides in Australia, owned by the founder of FordModelT.net. From https://commons.wikimedia.org/wiki/File:1925_Ford_Model_T_touring.jpg
It’s said that Henry Ford’s customers wanted a “a faster horse”. If Henry Ford was selling us artificial intelligence today, what would the customer call for, “a smarter human”? That’s certainly the picture of machine intelligence we find in science fiction narratives, but the reality of what we’ve developed is much more mundane.
Car engines produce prodigious power from petrol. Machine intelligences deliver decisions derived from data. In both cases the scale of consumption enables a speed of operation that is far beyond the capabilities of their natural counterparts. Unfettered energy consumption has consequences in the form of climate change. Does unbridled data consumption also have consequences for us?
If we devolve decision making to machines, we depend on those machines to accommodate our needs. If we don’t understand how those machines operate, we lose control over our destiny. Our mistake has been to see machine intelligence as a reflection of our intelligence. We cannot understand the smarter human without understanding the human. To understand the machine, we need to better understand ourselves.
The Atomic Human

{kind=link}
Lies and Damned Lies
There are three types of lies: lies, damned lies and statistics
Arthur Balfour 1848-1930
Arthur Balfour was quoting the lawyer James Munro1 when he said that there three types of lies: lies, damned lies and statistics in 1892. This is 20 years before the first academic department of applied statistics was founded at UCL.
If Balfour were alive today, it is likely that he’d rephrase his quote:
There are three types of lies, lies damned lies and big data.
Why? Because the challenges of understanding and interpreting big data today are similar to those that Balfour (who was a Conservative politician and statesman and would later become Prime Minister) faced in governing an empire through statistics in the latter part of the 19th century.
The quote lies, damned lies and statistics was also credited to Benjamin Disraeli by Mark Twain in Twain’s autobiography.2 It characterizes the idea that statistic can be made to prove anything. But Disraeli died in 1881 and Mark Twain died in 1910. The important breakthrough in overcoming our tendency to over-interpet data came with the formalization of the field through the development of mathematical statistics.
Data has an elusive quality, it promises so much but can deliver little, it can mislead and misrepresent. To harness it, it must be tamed. In Balfour and Disraeli’s time during the second half of the 19th century, numbers and data were being accumulated, the social sciences were being developed. There was a large-scale collection of data for the purposes of government.
The modern ‘big data era’ is on the verge of delivering the same sense of frustration that Balfour experienced, the early promise of big data as a panacea is evolving to demands for delivery. For me, personally, peak-hype coincided with an email I received inviting collaboration on a project to deploy “Big Data and Internet of Things in an Industry 4.0 environment”. Further questioning revealed that the actual project was optimization of the efficiency of a manufacturing production line, a far more tangible and realizable goal.
The antidote to this verbiage is found in increasing awareness. When dealing with data the first trap to avoid is the games of buzzword bingo that we are wont to play. The first goal is to quantify what challenges can be addressed and what techniques are required. Behind the hype fundamentals are changing. The phenomenon is about the increasing access we have to data. The way customers’ information is recorded and processes are codified and digitized with little overhead. Internet of things is about the increasing number of cheap sensors that can be easily interconnected through our modern network structures. But businesses are about making money, and these phenomena need to be recast in those terms before their value can be realized.
For more thoughts on the challenges that statistics brings see Chapter 8 of Lawrence (2024).
Mathematical Statistics
Karl Pearson (1857-1936), Ronald Fisher (1890-1962) and others considered the question of what conclusions can truly be drawn from data. Their mathematical studies act as a restraint on our tendency to over-interpret and see patterns where there are none. They introduced concepts such as randomized control trials that form a mainstay of our decision making today, from government, to clinicians to large scale A/B testing that determines the nature of the web interfaces we interact with on social media and shopping.

Figure: Karl Pearson (1857-1936), one of the founders of Mathematical Statistics.
Their movement did the most to put statistics to rights, to eradicate the ‘damned lies’. It was known as ‘mathematical statistics’. Today I believe we should look to the emerging field of data science to provide the same role. Data science is an amalgam of statistics, data mining, computer systems, databases, computation, machine learning and artificial intelligence. Spread across these fields are the tools we need to realize data’s potential. For many businesses this might be thought of as the challenge of ‘converting bits into atoms’. Bits: the data stored on computer, atoms: the physical manifestation of what we do; the transfer of goods, the delivery of service. From fungible to tangible. When solving a challenge through data there are a series of obstacles that need to be addressed.
Firstly, data awareness: what data you have and where its stored. Sometimes this includes changing your conception of what data is and how it can be obtained. From automated production lines to apps on employee smart phones. Often data is locked away: manual logbooks, confidential data, personal data. For increasing awareness an internal audit can help. The website data.gov.uk hosts data made available by the UK government. To create this website the government’s departments went through an audit of what data they each hold and what data they could make available. Similarly, within private businesses this type of audit could be useful for understanding their internal digital landscape: after all the key to any successful campaign is a good map.
Secondly, availability. How well are the data sources interconnected? How well curated are they? The curse of Disraeli was associated with unreliable data and unreliable statistics. The misrepresentations this leads to are worse than the absence of data as they give a false sense of confidence to decision making. Understanding how to avoid these pitfalls involves an improved sense of data and its value, one that needs to permeate the organization.
The final challenge is analysis, the accumulation of the necessary expertise to digest what the data tells us. Data requires interpretation, and interpretation requires experience. Analysis is providing a bottleneck due to a skill shortage, a skill shortage made more acute by the fact that, ideally, analysis should be carried out by individuals not only skilled in data science but also equipped with the domain knowledge to understand the implications in a given application, and to see opportunities for improvements in efficiency.
‘Mathematical Data Science’
As a term ‘big data’ promises much and delivers little, to get true value from data, it needs to be curated and evaluated. The three stages of awareness, availability and analysis provide a broad framework through which organizations should be assessing the potential in the data they hold. Hand waving about big data solutions will not do, it will only lead to self-deception. The castles we build on our data landscapes must be based on firm foundations, process and scientific analysis. If we do things right, those are the foundations that will be provided by the new field of data science.
Today the statement “There are three types of lies: lies, damned lies and ‘big data’” may be more apt. We are revisiting many of the mistakes made in interpreting data from the 19th century. Big data is laid down by happenstance, rather than actively collected with a particular question in mind. That means it needs to be treated with care when conclusions are being drawn. For data science to succeed it needs the same form of rigor that Pearson and Fisher brought to statistics, a “mathematical data science” is needed.
You can also check my blog post on Lies, Damned Lies and Big Data.
The Diving Bell and the Butterfly

Figure: The Diving Bell and the Buttefly is the autobiography of Jean Dominique Bauby.
The Diving Bell and the Butterfly is the autobiography of Jean Dominique Bauby. Jean Dominique, the editor of French Elle magazine, suffered a major stroke at the age of 43 in 1995. The stroke paralyzed him and rendered him speechless. He was only able to blink his left eyelid, he became a sufferer of locked in syndrome.
See Lawrence (2024) Le Scaphandre et le papillon (The Diving Bell and the Butterfly) p. 10–12.
O M D P C F B V
H G J Q Z Y X K W
Figure: The ordering of the letters that Bauby used for writing his autobiography.
How could he do that? Well, first, they set up a mechanism where he could scan across letters and blink at the letter he wanted to use. In this way, he was able to write each letter.
It took him 10 months of four hours a day to write the book. Each word took two minutes to write.
Imagine doing all that thinking, but so little speaking, having all those thoughts and so little ability to communicate.
One challenge for the atomic human is that we are all in that situation. While not as extreme as for Bauby, when we compare ourselves to the machine, we all have a locked-in intelligence.
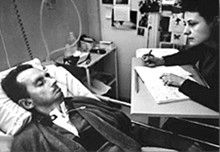
Figure: Jean Dominique Bauby was the Editor in Chief of the French Elle Magazine, he suffered a stroke that destroyed his brainstem, leaving him only capable of moving one eye. Jean Dominique became a victim of locked in syndrome.
Incredibly, Jean Dominique wrote his book after he became locked in. It took him 10 months of four hours a day to write the book. Each word took two minutes to write.
The idea behind embodiment factors is that we are all in that situation. While not as extreme as for Bauby, we all have somewhat of a locked in intelligence.
See Lawrence (2024) Bauby, Jean Dominique p. 9–11, 18, 90, 99-101, 133, 186, 212–218, 234, 240, 251–257, 318, 368–369.
Bauby and Shannon
|
|

|
Figure: Claude Shannon developed information theory which allows us to quantify how much Bauby can communicate. This allows us to compare how locked in he is to us.
See Lawrence (2024) Shannon, Claude p. 10, 30, 61, 74, 98, 126, 134, 140, 143, 149, 260, 264, 269, 277, 315, 358, 363.
Embodiment Factors
|
|
|||
| bits/min | billions | 2000 | 6 |
|
billion calculations/s |
~100 | a billion | a billion |
| embodiment | 20 minutes | 5 billion years | 15 trillion years |
Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Jean Dominique Bauby suffered from locked-in syndrome. The embodiment factors show that relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, whether locked in or not, it is a matter of many millions of years.
Let me explain what I mean. Claude Shannon introduced a mathematical concept of information for the purposes of understanding telephone exchanges.
Information has many meanings, but mathematically, Shannon defined a bit of information to be the amount of information you get from tossing a coin.
If I toss a coin, and look at it, I know the answer. You don’t. But if I now tell you the answer I communicate to you 1 bit of information. Shannon defined this as the fundamental unit of information.
If I toss the coin twice, and tell you the result of both tosses, I give you two bits of information. Information is additive.
Shannon also estimated the average information associated with the English language. He estimated that the average information in any word is 12 bits, equivalent to twelve coin tosses.
So every two minutes Bauby was able to communicate 12 bits, or six bits per minute.
This is the information transfer rate he was limited to, the rate at which he could communicate.
Compare this to me, talking now. The average speaker for TEDX speaks around 160 words per minute. That’s 320 times faster than Bauby or around a 2000 bits per minute. 2000 coin tosses per minute.
But, just think how much thought Bauby was putting into every sentence. Imagine how carefully chosen each of his words was. Because he was communication constrained he could put more thought into each of his words. Into thinking about his audience.
So, his intelligence became locked in. He thinks as fast as any of us, but can communicate slower. Like the tree falling in the woods with no one there to hear it, his intelligence is embedded inside him.
Two thousand coin tosses per minute sounds pretty impressive, but this talk is not just about us, it’s about our computers, and the type of intelligence we are creating within them.
So how does two thousand compare to our digital companions? When computers talk to each other, they do so with billions of coin tosses per minute.
Let’s imagine for a moment, that instead of talking about communication of information, we are actually talking about money. Bauby would have 6 dollars. I would have 2000 dollars, and my computer has billions of dollars.
The internet has interconnected computers and equipped them with extremely high transfer rates.
However, by our very best estimates, computers actually think slower than us.
How can that be? You might ask, computers calculate much faster than me. That’s true, but underlying your conscious thoughts there are a lot of calculations going on.
Each thought involves many thousands, millions or billions of calculations. How many exactly, we don’t know yet, because we don’t know how the brain turns calculations into thoughts.
Our best estimates suggest that to simulate your brain a computer would have to be as large as the UK Met Office machine here in Exeter. That’s a 250 million pound machine, the fastest in the UK. It can do 16 billion billon calculations per second.
It simulates the weather across the word every day, that’s how much power we think we need to simulate our brains.
So, in terms of our computational power we are extraordinary, but in terms of our ability to explain ourselves, just like Bauby, we are locked in.
For a typical computer, to communicate everything it computes in one second, it would only take it a couple of minutes. For us to do the same would take 15 billion years.
If intelligence is fundamentally about processing and sharing of information. This gives us a fundamental constraint on human intelligence that dictates its nature.
I call this ratio between the time it takes to compute something, and the time it takes to say it, the embodiment factor (Lawrence, 2017a). Because it reflects how embodied our cognition is.
If it takes you two minutes to say the thing you have thought in a second, then you are a computer. If it takes you 15 billion years, then you are a human.
Bandwidth Constrained Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Embodiment factors imply that, in our communication between humans, what is not said is, perhaps, more important than what is said. To communicate with each other we need to have a model of who each of us are.
To aid this, in society, we are required to perform roles. Whether as a parent, a teacher, an employee or a boss. Each of these roles requires that we conform to certain standards of behaviour to facilitate communication between ourselves.
Control of self is vitally important to these communications.
The high availability of data available to humans undermines human-to-human communication channels by providing new routes to undermining our control of self.
The consequences between this mismatch of power and delivery are to be seen all around us. Because, just as driving an F1 car with bicycle wheels would be a fine art, so is the process of communication between humans.
If I have a thought and I wish to communicate it, I first need to have a model of what you think. I should think before I speak. When I speak, you may react. You have a model of who I am and what I was trying to say, and why I chose to say what I said. Now we begin this dance, where we are each trying to better understand each other and what we are saying. When it works, it is beautiful, but when mis-deployed, just like a badly driven F1 car, there is a horrible crash, an argument.
Heider and Simmel (1944)
Figure: Fritz Heider and Marianne Simmel’s video of shapes from Heider and Simmel (1944).
Fritz Heider and Marianne Simmel’s experiments with animated shapes from 1944 (Heider and Simmel, 1944). Our interpretation of these objects as showing motives and even emotion is a combination of our desire for narrative, a need for understanding of each other, and our ability to empathize. At one level, these are crudely drawn objects, but in another way, the animator has communicated a story through simple facets such as their relative motions, their sizes and their actions. We apply our psychological representations to these faceless shapes to interpret their actions [Heider-interpersonal58].
See also a recent review paper on Human Cooperation by Henrich and Muthukrishna (2021). See Lawrence (2024) psychological representation p. 326–329, 344–345, 353, 361, 367.
Computer Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Similarly, we find it difficult to comprehend how computers are making decisions. Because they do so with more data than we can possibly imagine.
In many respects, this is not a problem, it’s a good thing. Computers and us are good at different things. But when we interact with a computer, when it acts in a different way to us, we need to remember why.
Just as the first step to getting along with other humans is understanding other humans, so it needs to be with getting along with our computers.
Embodiment factors explain why, at the same time, computers are so impressive in simulating our weather, but so poor at predicting our moods. Our complexity is greater than that of our weather, and each of us is tuned to read and respond to one another.
Their intelligence is different. It is based on very large quantities of data that we cannot absorb. Our computers don’t have a complex internal model of who we are. They don’t understand the human condition. They are not tuned to respond to us as we are to each other.
Embodiment factors encapsulate a profound thing about the nature of humans. Our locked in intelligence means that we are striving to communicate, so we put a lot of thought into what we’re communicating with. And if we’re communicating with something complex, we naturally anthropomorphize them.
We give our dogs, our cats, and our cars human motivations. We do the same with our computers. We anthropomorphize them. We assume that they have the same objectives as us and the same constraints. They don’t.
This means, that when we worry about artificial intelligence, we worry about the wrong things. We fear computers that behave like more powerful versions of ourselves that will struggle to outcompete us.
In reality, the challenge is that our computers cannot be human enough. They cannot understand us with the depth we understand one another. They drop below our cognitive radar and operate outside our mental models.
The real danger is that computers don’t anthropomorphize. They’ll make decisions in isolation from us without our supervision because they can’t communicate truly and deeply with us.
Evolved Relationship with Information
The high bandwidth of computers has resulted in a close relationship between the computer and data. Large amounts of information can flow between the two. The degree to which the computer is mediating our relationship with data means that we should consider it an intermediary.
Originally our low bandwidth relationship with data was affected by two characteristics. Firstly, our tendency to over-interpret driven by our need to extract as much knowledge from our low bandwidth information channel as possible. Secondly, by our improved understanding of the domain of mathematical statistics and how our cognitive biases can mislead us.
With this new set up there is a potential for assimilating far more information via the computer, but the computer can present this to us in various ways. If its motives are not aligned with ours then it can misrepresent the information. This needn’t be nefarious it can be simply because of the computer pursuing a different objective from us. For example, if the computer is aiming to maximize our interaction time that may be a different objective from ours which may be to summarize information in a representative manner in the shortest possible length of time.
For example, for me, it was a common experience to pick up my telephone with the intention of checking when my next appointment was, but to soon find myself distracted by another application on the phone and end up reading something on the internet. By the time I’d finished reading, I would often have forgotten the reason I picked up my phone in the first place.
There are great benefits to be had from the huge amount of information we can unlock from this evolved relationship between us and data. In biology, large scale data sharing has been driven by a revolution in genomic, transcriptomic and epigenomic measurement. The improved inferences that can be drawn through summarizing data by computer have fundamentally changed the nature of biological science, now this phenomenon is also influencing us in our daily lives as data measured by happenstance is increasingly used to characterize us.
Better mediation of this flow requires a better understanding of human-computer interaction. This in turn involves understanding our own intelligence better, what its cognitive biases are and how these might mislead us.
For further thoughts see Guardian article on marketing in the internet era from 2015.
You can also check my blog post on System Zero. This was also written in 2015.
New Flow of Information
Classically the field of statistics focused on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
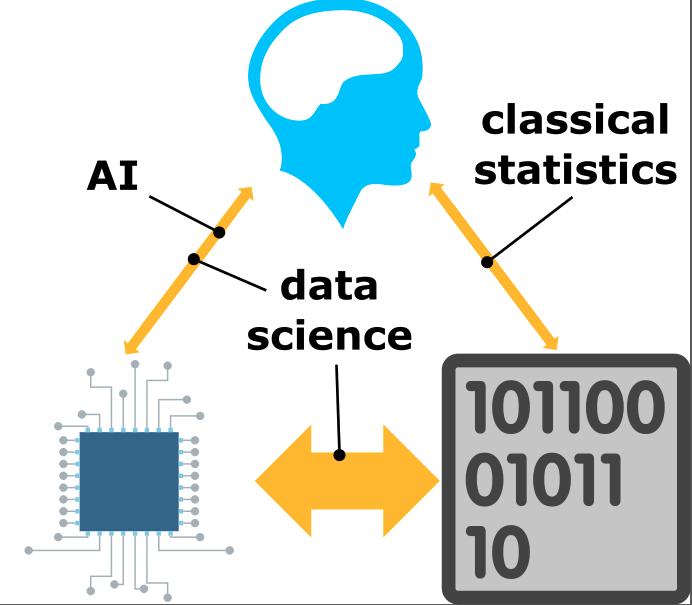
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarize what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data but must also deal with the possibility that the machine has either inadvertently or maliciously misrepresented the underlying data.
With new capabilities becoming available through very large generational AI models, we can imagine different interfaces with that information, but the potential for manipulation is if anything even greater.
Figure: New capabilities in language generation offer the tantalising possibility for a better interface between the machine and it’s understanding of data but characterising that communication channel remains a major challenge.
Data Science as Debugging
One challenge for existing information technology professionals is realizing the extent to which a software ecosystem based on data differs from a classical ecosystem. In particular, by ingesting data we bring unknowns/uncontrollables into our decision-making system. This presents opportunity for adversarial exploitation and unforeseen operation.
blog post on Data Science as Debugging.
Starting with the analysis of a data set, the nature of data science is somewhat difference from classical software engineering.
One analogy I find helpful for understanding the depth of change we need is the following. Imagine as a software engineer, you find a USB stick on the ground. And for some reason you know that on that USB stick is a particular API call that will enable you to make a significant positive difference on a business problem. You don’t know which of the many library functions on the USB stick are the ones that will help. And it could be that some of those library functions will hinder, perhaps because they are just inappropriate or perhaps because they have been placed there maliciously. The most secure thing to do would be to not introduce this code into your production system at all. But what if your manager told you to do so, how would you go about incorporating this code base?
The answer is very carefully. You would have to engage in a process more akin to debugging than regular software engineering. As you understood the code base, for your work to be reproducible, you should be documenting it, not just what you discovered, but how you discovered it. In the end, you typically find a single API call that is the one that most benefits your system. But more thought has been placed into this line of code than any line of code you have written before.
An enormous amount of debugging would be required. As the nature of the code base is understood, software tests to verify it also need to be constructed. At the end of all your work, the lines of software you write to interact with the software on the USB stick are likely to be minimal. But more thought would be put into those lines than perhaps any other lines of code in the system.
Even then, when your API code is introduced into your production system, it needs to be deployed in an environment that monitors it. We cannot rely on an individual’s decision making to ensure the quality of all our systems. We need to create an environment that includes quality controls, checks, and bounds, tests, all designed to ensure that assumptions made about this foreign code base are remaining valid.
This situation is akin to what we are doing when we incorporate data in our production systems. When we are consuming data from others, we cannot assume that it has been produced in alignment with our goals for our own systems. Worst case, it may have been adversarially produced. A further challenge is that data is dynamic. So, in effect, the code on the USB stick is evolving over time.
It might see that this process is easy to formalize now, we simply need to check what the formal software engineering process is for debugging, because that is the current software engineering activity that data science is closest to. But when we look for a formalization of debugging, we find that there is none. Indeed, modern software engineering mainly focusses on ensuring that code is written without bugs in the first place.
Lessons
When you begin a data analysis approach it with the mindset of a debugger: write test code continuously as you go through your analysis, ensure that the tests are documented and accessible to those who need to review or build upon your work.
Take time to thouroughly understand the context of your data before diving in. Expore multiple approaches and continually revisit your initial assumptions. Maintain a healtky skepticism about your results through the process and proactively explore potential issues or inconsistencies in the data.
Leverage the best tools available and develop a deep understanding of how they work. Don’t just treat the tools as black boxes, develop your understanding of tehri strengths, limmitations and appropriate use. Share challenges you are facing and progress you are making with colleagues. Seek regular views from business stakholders, software engineers, fellow data scientists and managers. Bringing in their different perspectives can help identify potential issues early.
Don’t rush to implementing your end-solution. Just as you wouldn’t immediately write an API call for unknown code you’ve found on a discarded USB code, you shouldn’t jump straght into running complex classsification algorithms before gaining an intuition for your data through some basic visualisation and ohter tests. The documentation of the analysis process should be such that if issues do arise in production the documentation can be used to support tracing back to where the problems have originated and rapidly rectifying them.
Always remember that the data science process differs fundamentally from standard software development, so traditional agile development pipelines may not be appropriate. You have to adapt your processes to handle inherrent uncertainty and accomidate the iterative and recursive nature of data science work. Think carefully about how you will handle not just individual bugs but systematic issues that may emerge from your data.
Don’t work in isolation, the complexity of data work means that close collaboration with domain experts, software engineers and other data scientists is essention. The collaboration serves multiple purposes: it provides you with the necessary technical support, helps maintain realistic expectations among stakeholders in terms of both outcome and delivery time lines. And it ensures that the solutions developed actually address the underlying business problem.
Recommendation: Anecdotally, resolving a machine learning challenge requires 80% of the resource to be focused on the data and perhaps 20% to be focused on the model. But many companies are too keen to employ machine learning engineers who focus on the models, not the data. We should change our hiring priorities and training. Universities cannot provide the understanding of how to data-wrangle. Companies must fill this gap.
The Fynesse Framework
Here we present a new framework for thinking about data science. The Fynesse framework splits the activities of the data scientist into three aspects, each aspect is represented by a one of three words that highlight different activities that occur within a data science project: we call them access, assess and address.
Before going deeper into the framework, we will contextualize by looking at some other formalizations of the data analysis pipeline.
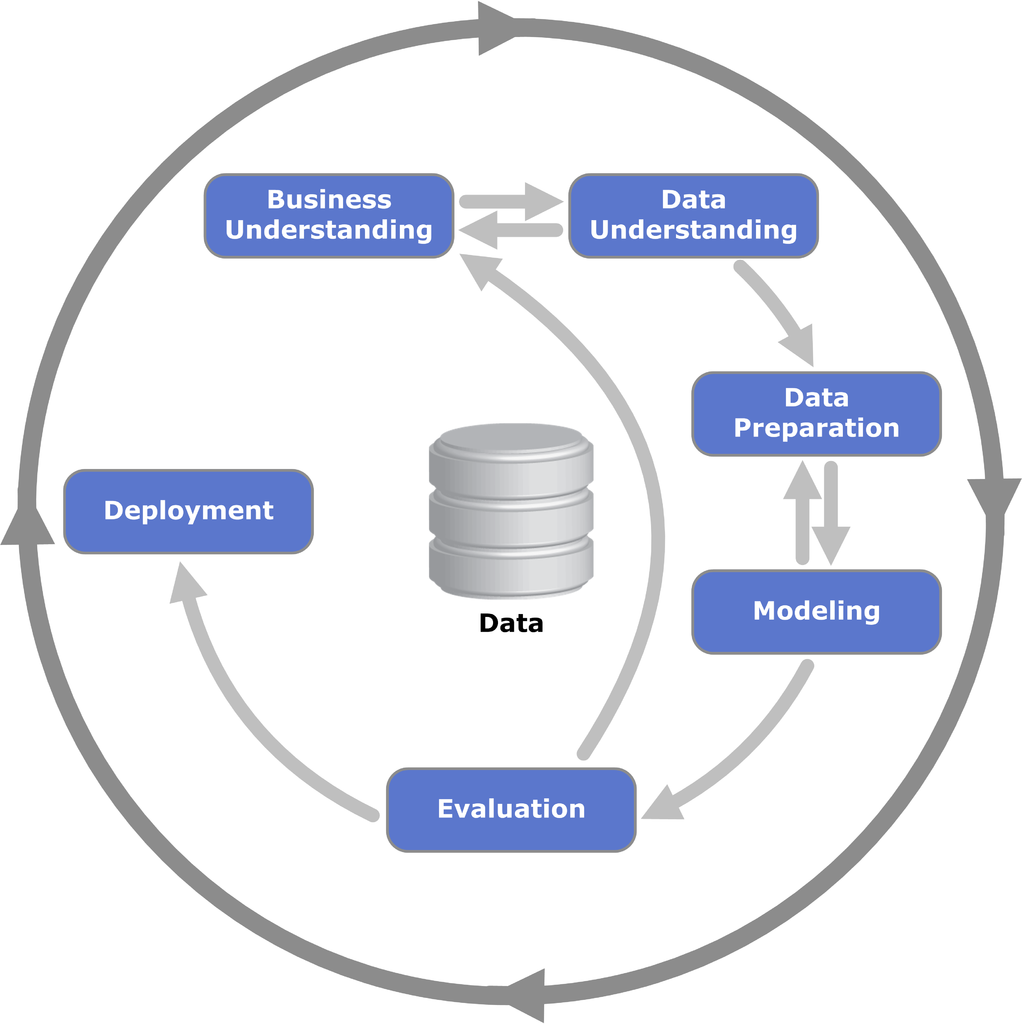
Figure: The CRISP Data Mining Process diagram: it stands for cross industry standard process for data mining. The process was defined in 2000 (Chapman et al. (2000)), well before the modern service-oriented architecture approach to software engineering emerged.
There are formal processes designed for, e.g., data mining, but they are not always appropriate for operational science or continuous deployment. One is the CRISP-DM Chapman et al. (2000) process, which does a nice job of capturing the cyclic nature of these processes but fails to capture the need to build resources that answer questions in real time that occurs in operational science and continuous deployment.
Google Trends
%pip install pytrendsFigure: A Google trends search for ‘data mining’, ‘data science’ as different technological terms give us insight into their popularity over time.
Google trends gives us insight into the interest for different terms over time.
We note that the term data mining is falling somewhat out of favour, and the CRISP-DM data mining process also feels somewhat dated. In particular software engineering has moved on a great deal since it was defined, with modern software engineering more focused on service-oriented architectures. Software design has a pervasive effect on our ability to do data science.
When thinking about the data science process it is important to consider the software architectures that are used in large-scale decision-making systems and understand what it is that they are bring to help solve these problems.
A more modern view from the O’Reilly book Doing Data Science frames the problem as shown in Figure \(\ref{data-science-process-oneil}\).
More generally, a data scientist is someone who knows how to extract meaning from and interpret data, which requires both tools and methods from statistics and machine learning, as well as being human. She spends a lot of time in the process of collecting, cleaning, and munging data, because data is never clean. This process requires persistence, statistics, and software engineering skills—skills that are also necessary for understanding biases in the data, and for debugging logging output from code.
Cathy O’Neil and Rachel Strutt from O’Neill and Schutt (2013)
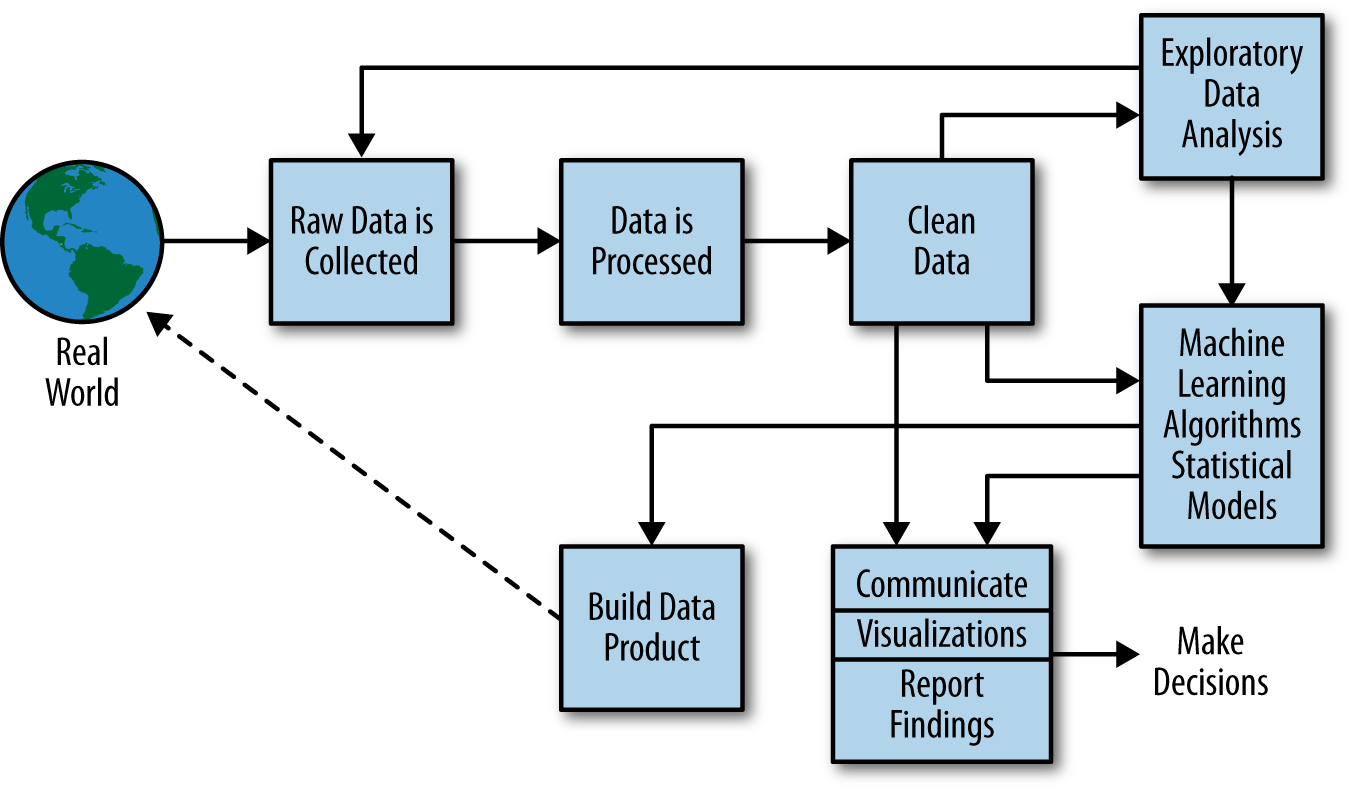
Figure: Another perspective on the data science process, this one from O’Neill and Schutt (2013).
One thing about working in an industrial environment, is the way that short-term thinking actions become important. For example, in Formula One, the teams are working on a two-week cycle to digest information from the previous week’s race and incorporate updates to the car or their strategy.
However, businesses must also think about more medium-term horizons. For example, in Formula 1 you need to worry about next year’s car. So, while you’re working on updating this year’s car, you also need to think about what will happen for next year and prioritize these conflicting needs appropriately.
In the Amazon supply chain, there are equivalent demands. If we accept that an artificial intelligence is just an automated decision-making system. And if we measure in terms of money automatically spent, or goods automatically moved, then Amazon’s buying system is perhaps the world’s largest AI.
Those decisions are being made on short time schedules; purchases are made by the system on weekly cycles. But just as in Formula 1, there is also a need to think about what needs to be done next month, next quarter and next year. Planning meetings are held not only on a weekly basis (known as weekly business reviews), but monthly, quarterly, and then yearly meetings for planning spends and investments.
Amazon is known for being longer term thinking than many companies, and a lot of this is coming from the CEO. One quote from Jeff Bezos that stuck with me was the following.
“I very frequently get the question: ‘What’s going to change in the next 10 years?’ And that is a very interesting question; it’s a very common one. I almost never get the question: ‘What’s not going to change in the next 10 years?’ And I submit to you that that second question is actually the more important of the two – because you can build a business strategy around the things that are stable in time. … [I]n our retail business, we know that customers want low prices, and I know that’s going to be true 10 years from now. They want fast delivery; they want vast selection. It’s impossible to imagine a future 10 years from now where a customer comes up and says, ‘Jeff I love Amazon; I just wish the prices were a little higher,’ [or] ‘I love Amazon; I just wish you’d deliver a little more slowly.’ Impossible. And so the effort we put into those things, spinning those things up, we know the energy we put into it today will still be paying off dividends for our customers 10 years from now. When you have something that you know is true, even over the long term, you can afford to put a lot of energy into it.”
This quote is incredibly important for long term thinking. Indeed, it’s a failure of many of our simulations that they focus on what is going to happen, not what will not happen. In Amazon, this meant that there was constant focus on these three areas, keeping costs low, making delivery fast and improving selection. For example, shortly before I left Amazon moved its entire US network from two-day delivery to one-day delivery. This involves changing the way the entire buying system operates. Or, more recently, the company has had to radically change the portfolio of products it buys in the face of Covid19.
Figure: Experiment, analyze and design is a flywheel of knowledge that is the dual of the model, data and compute. By running through this spiral, we refine our hypothesis/model and develop new experiments which can be analyzed to further refine our hypothesis.
From the perspective of the team that we had in the supply chain, we looked at what we most needed to focus on. Amazon moves very quickly, but we could also take a leaf out of Jeff’s book, and instead of worrying about what was going to change, remember what wasn’t going to change.
We don’t know what science we’ll want to do in five years’ time, but we won’t want slower experiments, we won’t want more expensive experiments and we won’t want a narrower selection of experiments.
As a result, our focus was on how to speed up the process of experiments, increase the diversity of experiments that we can do, and keep the experiments price as low as possible.
The faster the innovation flywheel can be iterated, then the quicker we can ask about different parts of the supply chain, and the better we can tailor systems to answering those questions.
We need faster, cheaper and more diverse experiments which implies we need better ecosystems for experimentation. This has led us to focus on the software frameworks we’re using to develop machine learning systems including data oriented architectures (Cabrera et al. (2023),Paleyes et al. (2022b),Paleyes et al. (2022a),Borchert (2020);Lawrence (2019);Vorhemus and Schikuta (2017);Joshi (2007)), data maturity assessments (Lawrence et al. (2020)) and data readiness levels (See this blog post on Data Readiness Levels. and Lawrence (2017b);The DELVE Initiative (2020))
One challenge for data science and data science processes is that they do not always accommodate the real-time and evolving nature of data science advice as required, for example in pandemic response or in managing an international supply chain.
Figure: Data science processes do not always accommodate the real-time and evolving nature of data science advice as required, for example, for policy advice as described in this presentation.
Ride Sharing: Service Oriented to Data Oriented
The modern approach to software systems design is known as a service-oriented architectures (SOA). The idea is that software engineers are responsible for the availability and reliability of the API that accesses the service they own. Quality of service is maintained by rigorous standards around testing of software systems.
In data driven decision-making systems, the quality of decision-making is determined by the quality of the data. We need to extend the notion of service-oriented architecture to data-oriented architecture (DOA).
The focus in SOA is eliminating hard failures. Hard failures can occur due to bugs or systems overload. This notion needs to be extended in ML systems to capture soft failures associated with declining data quality, incorrect modeling assumptions and inappropriate re-deployments of models. We need to focus on data quality assessments. In data-oriented architectures engineering teams are responsible for the quality of their output data streams in addition to the availability of the service they support (Lawrence, 2017b). Quality here is not just accuracy, but fairness and explainability. This important cultural change would be capable of addressing both the challenge of technical debt (Sculley et al., 2015) and the social responsibility of ML systems.
Software development proceeds with a test-oriented culture. One where tests are written before software, and software is not incorporated in the wider system until all tests pass. We must apply the same standards of care to our ML systems, although for ML we need statistical tests for quality, fairness, and consistency within the environment. Fortunately, the main burden of this testing need not fall to the engineers themselves: through leveraging classical statistics and emulation we will automate the creation and redeployment of these tests across the software ecosystem, we call this ML hypervision.
Modern AI can be based on ML models with many millions of parameters, trained on very large data sets. In ML, strong emphasis is placed on predictive accuracy whereas sister-fields such as statistics have a strong emphasis on interpretability. ML models are said to be ‘black boxes’ which make decisions that are not explainable.3
For the ride sharing system, we start to see a common issue with a more complex algorithmic decision-making system. Several decisions are being made multiple times. Let’s look at the decisions we need along with some design criteria.
- Driver Availability: Estimate time to arrival for Anne’s ride using Anne’s location and local available car locations. Latency 50 milliseconds
- Cost Estimate: Estimate cost for journey using Anne’s destination, location and local available car current destinations and availability. Latency 50 milliseconds
- Driver Allocation: Allocate car to minimize transport cost to destination. Latency 2 seconds.
So we need:
- a hypothetical to estimate availability. It is constrained by lacking destination information and a low latency requirement.
- a hypothetical to estimate cost. It is constrained by low latency requirement and
Simultaneously, drivers in this data ecosystem have an app which notifies them about new jobs and recommends them where to go.
Further advantages. Strategies for data retention (when to snapshot) can be set globally.
A few decisions need to be made in this system. First of all, when the user opens the app, the estimate of the time to the nearest ride may need to be computed quickly, to avoid latency in the service.
This may require a quick estimate of the ride availability.
The Fynesse paradigm is inspired by experience in operational data science working with Data Science Africa, deploying in the Amazon supply chain and in the UK Covid-19 pandemic response.
Figure: The challenges of operational data science are closer to the challenges of deploying software and machine learning solutions than a classical analysis. The AutoAI project at Cambridge is focussed on maintaining and explaining AI solutions.
Arguably the challenges for automated data science and deploying complex machine learning solutions are similar. The AutoAI project at Cambridge is focussed on maintaining and explaining machine learning systems. The assumption is that such systems are generally made up of interacting components that make decisions in a composite manner. They have interfaces to the real world where that data is collected, but they also generate data within themselves. The challenge of collecting data is sometimes less the challenge of pacing the streets and more the challenge of extracting it from existing systems.
The Fynesse Framework
The Fynesse paradigm considers three aspects to data analysis: Access, Assess, Address. In this way it builds on many two stage processes that consider data collection and data wrangling to be two separate stages. There are two key differences to the Fynesse process. Firstly, the attempt to separate data wrangling tasks into (a) those that can be done without knowing the downstream task (Assess) and (b) those that can only be done with knowing the downstream task (Address). Naturally, this won’t turn out to be a clean separation. But the ethos is to ensure that any reusable tasks that is done in the process of data wrangling is labelled as such and pushed back into the data ecosystem. Secondly, our use of the term aspects instead of stages acknowledges the fact that although there is a natural ordering to the aspects, we find that in practice the data scientist is often moving quickly across the different aspects, so that the mind set of “stages” can be unhelpful.
Access
The first aspect we’ll consider is accessing the data. Depending on domain, the skills needed to address this challenge will vary greatly. For example, Michael T. Smith was leading a project in collaboration with the Kampala police force to collate accident data.
The access aspect is associated with data readiness level C (Lawrence (2017b)).
Crash Map Kampala
The Crash Map Kampala project is a good example of a data science project where a major challenge was access.
Figure: Crash Map Kampala was an initiative by Michael T. Smith and Bagonza Jimmy Owa Kinyonyi to map the location, date and severity of vehicle accidents across the city of Kampala. Original storage location for the data was in police logbooks.
The project is work from Bagonza Jimmy Owa Kinyony when he was an MSc student and Michael T. Smith when he was based at Makerere University AI-LAB.
The project was inspired by the observation that road traffic accidents are a leading cause of death for the young in many contexts, but the scale of the cause is difficult to compare directly because the number of deaths and serious injuries are difficult to access.
In Kampala this data is stored in logbooks at local police stations. Jimmy was in the Kampala police at the time, so the project focus was transcribing this information into a digital format where it could be mapped.
Due to the scale of the task, the approach of crowd sourcing the work was considered. This approach was also what launched the AI revolution through the ImageNet challenge, where data was labelled through Mechanical Turk (Russakovsky et al. (2015)).
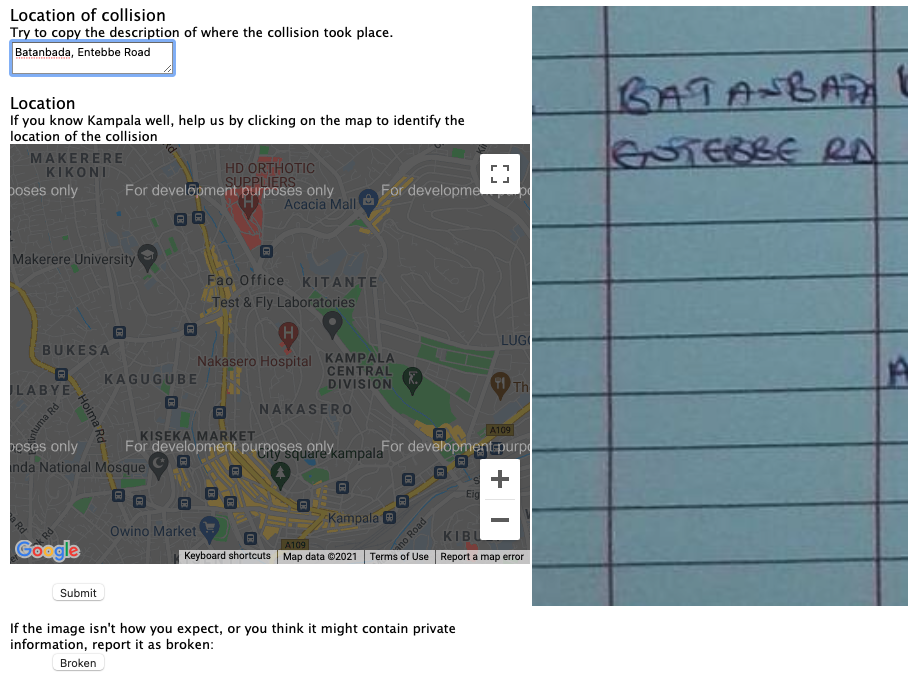
Figure:
But there are additional challenges with this data. The logbooks are typically accessed only by members of Kampala’s police force, in their recording of the accidents. So, permission from the police force was important. Additionally, personal information about those involved in the accidents might have been revealed in the process of crowdsourcing the work.

Figure: Alongside the location, the date and time of the crash gives more information that can be used to map crashes over time.
Much of the work here was therefore in the access of the data. Photographing the logbooks, obtaining legal permission from the Kampala police, ensuring that personal information was unlikely to be divulged.

Figure: The severity of the crash is helpful in understanding how people are being affected by road accidents.
As well as software design and build, the work has legal and ethical issues. An important aspect in gaining progress was that Jimmy worked for the Kampala police. Indeed, the work eventually stalled when Jimmy was moved to a different police location.

Figure: Understanding which vehicles are involved in accidents could also help with interventions that may be necessary.
The possibility of leaking personal information was reduced, by presenting only a portion of each logbook page to users for analysis. So we can see in Figure \(\ref{crash-map-kampala-location}\) the interface for obtaining the location from the logbook. But the date and time (Figure \(\ref{crash-map-kampala-date-time}\)) the severity of the accident (Figure \(\ref{crash-map-kampala-severity}\)) and the vehicles involved (Figure \(\ref{crash-map-kampala-vehicles}\)) are all dealt with in separate parts of the interface.

Figure:
It seems a great challenge to automate all the different aspects of the process of data access, but this challenge is underway already through the process of what is commonly called digital transformation. The process of digital transformation takes data away from physical logbooks and into digital devices. But that transformation process itself comes with challenges. For example, the Kampala police force is not currently equipped to store this data in purely digital form. It would require not only devices (which many officers will have access to) but a system of backup and storage that is beyond the capabilities of many organisations.
Legal complications around data are still a major barrier though. In the EU and the US database schema and indices are subject to copyright law. Companies making data available often require license fees. As many data sources are combined, the composite effect of the different license agreements often makes the legal challenges insurmountable. This was a common challenge in the pandemic, where academics who could deal with complex data predictions were excluded from data access due to challenges around licensing. A nice counter example was the work led by Nuria Oliver in Spain who after a call to arms in a national newspaper (Oliver (2020)) was able to bring the ecosystem together around mobility data.
However, even when organisation is fully digital, and license issues are overcome, there are issues around how the data is managed stored, accessed. The discoverability of the data and the recording of its provenance are too often neglected in the process of digital transformation. Further, once an organisation has gone through digital transformation, they begin making predictions around the data. These predictions are data themselves, and their presence in the data ecosystem needs recording. Automating this portion requires structured thinking around our data ecosystems.
Assess
Data that is accessible can be imported (via APIs or database calls or reading a CSV) into the machine and work can be done understanding the nature of the data. The important thing to say about the assess aspect is that it only includes things you can do without the question in mind. This runs counter to many ideas about how we do data analytics. The history of statistics was that we think of the question before we collect data. But that was because data was expensive, and it needed to be explicitly collected. The same mantra is true today of surveillance data. But the new challenge is around happenstance data, data that is cheaply available but may be of poor quality. The nature of the data needs to be understood before its integrated into analysis. Unfortunately, because the work is conflated with other aspects, decisions are sometimes made during assessment (for example approaches to imputing missing values) which may be useful in one context, but are useless in others. So the aim in assess is to only do work that is repeatable, and make that work available to others who may also want to use the data.
The assess aspect renders the Fynesse framework quite different form other data science frameworks that split the process into data wrangling and data modelling. It acknowledges that there is a component to both wrangling and modelling that is specific to the task (this occurs in the address aspect) and a component that is useful across tasks (the assess aspect). This is important in the wider system because any reusable work can be shared. By keeping this uppermost in the mind through the assess aspect, then the wider data ecosystem benefits.
The assess aspect is associated with data readiness level B (Lawrence (2017b)).
Case Study: Text Mining for Misinformation
We consider a case study from Joyce Nabende, Head of the Makerere AI Lab. This case study is based on a presentation given by Joyce to the DSA Research Grants, “Project Progress” session on 20th August 2021.
The aim of the case study is to map some of the approaches used by Joyce onto the Access, Assess, Address paradigm.
The aim of the project is to develop tools for automated misinformation detection. Web, mobile based social media platforms. Social media posts are invalid, inaccurate, potentially harmful. This is set within the context of the Covid-19 pandemic within Uganda.

In common with many applications of data science, and in line with traditional statistics, the question here comes first, at the beginning of the data collection. But the access of the data is made easier by the fact that the data exists in the digital space already. There are APIs for collecting data from Facebook and Twitter.
The focus here will be trying to understand which parts of this data collection process might be reusable for others. The aim is to separate those reusable parts from aspects that are specific to the question.
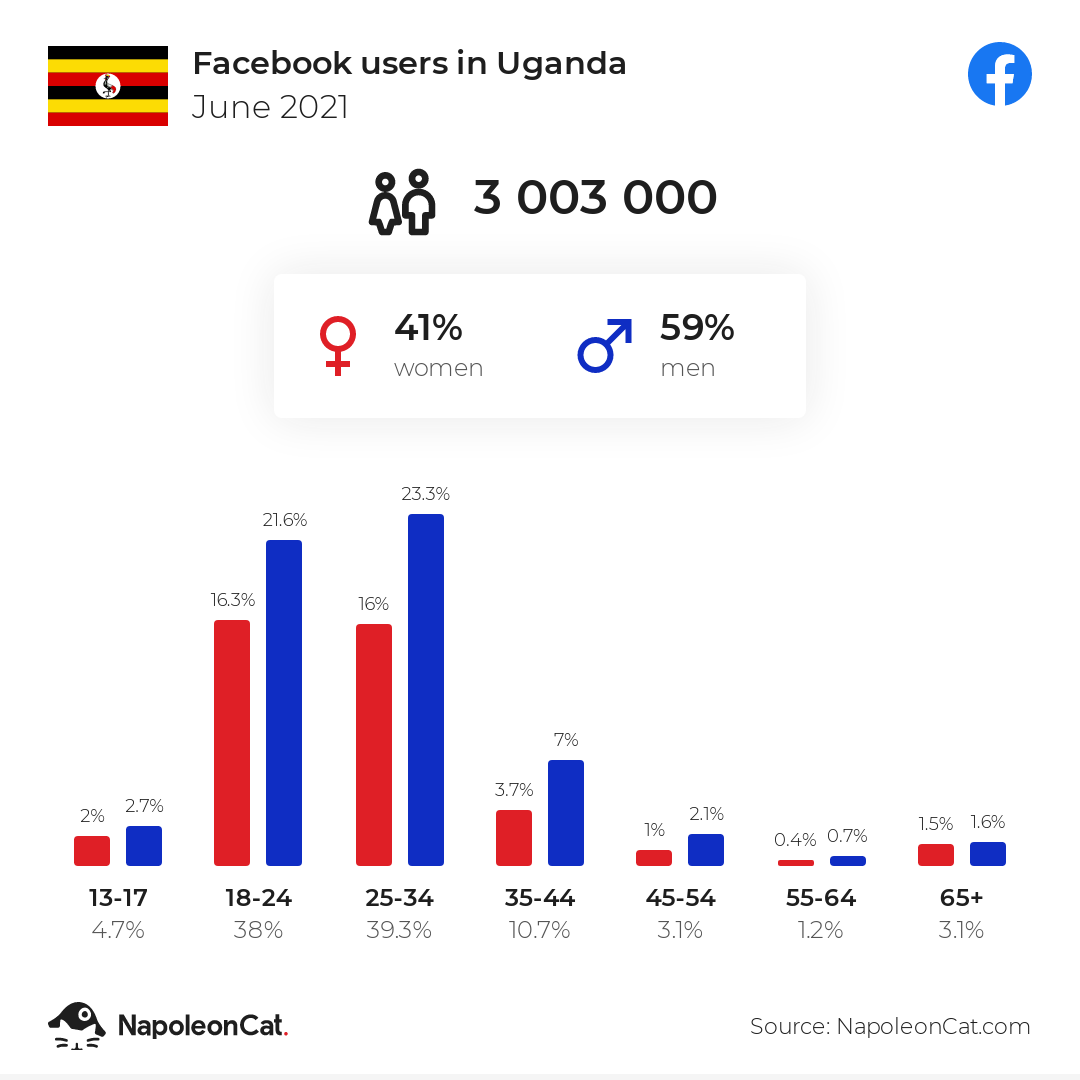
As with any data science problem, it’s vital that domain knowledge is included in the analysis of the problem. To set context, we see in Figure \(\ref{napoleoncat-social-media-statistics-facebook-users-in-uganda_2021_06}\) how widespread use of social media is in Uganda for different age groups. The total population of Uganda is around 47 million.

Figure: The objective of the project is to track misinformation and understandperceptions of Ugandan Government’s COVID-19 transmission mitigation strategies.
One challenge for this project is dealing with a data set with multiple languages. In Uganda, people don’t just communicate in English, but they will code-switch or communicate purely in, e.g. Luganda. Tools and resources for dealing with code-switching or the Lugandan language in NLP are much less common than tools for dealing with high resource languages (e.g. German, English, French, Spanish, Mandarin). See Magueresse et al. (2020) for a review of NLP in low resource languages, multilingual data sets bring their own problems Aman Ullah et al. (2020).
The Luganda language is the most widely spoken indigenous language in Uganda with more than seven million speakers. By definition, a low resourced language has less capabilities for data annotation and augmentation, e.g. part of speech taggers.
Data Access
The social media data was collected from a set of pages (media institutions, ministry of health, media personalities, top twitter/facebook users from Uganda. All data was then filtered using keywords, ‘ssenyiga’, ‘kolona’, ‘corona’ ,‘virus’ ,‘obulwadde’, ‘corona’, ‘covid’, ‘abalwadde’, ‘ekirwadde’, ‘akawuka’, ‘staysafeug’, ‘stayhome’, ‘tonsemberera’, ‘tokwatakudereva’, ‘vaccine’ to select with Covid-19 related tweets. Very short Facebook posts were also removed. Data was collected in two phases, from March 2020 - March 2021 and then from June 2021 - August 2021. Raw data points 15,354 posts from twitter and 430,075 from Facebook.
Note that in this case, knowledge of the question has been used in accessing the data. The context of the data is Uganda and the focus is Covid-19. That focus is driven by the pandemic. However, as we see when we get to data assessment, there is still an amount of reusable work that could/should be automated.
Data Assessment
After collecting data, the initial assessment was formed to understand the data, uncover patterns and gain insights. Here various visualisations can be used to find any unexpected factors in the data.
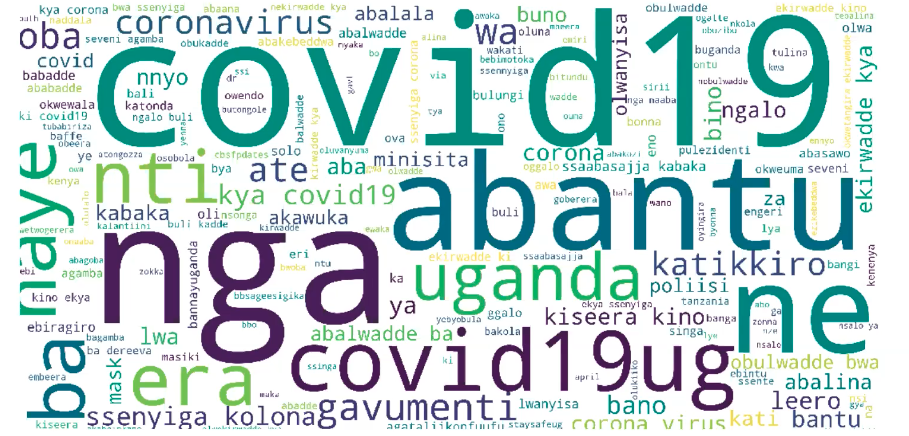
Figure: Word cloud from the Twitter data collected through the filtering.
In the case of the Uganda data set, Joyce found that mixed in with the Covid-19 data were topics focussed on popular Ugandan TV shows and the Ugandan election.

Figure: Word cloud from the Facebook data collected through the filtering.
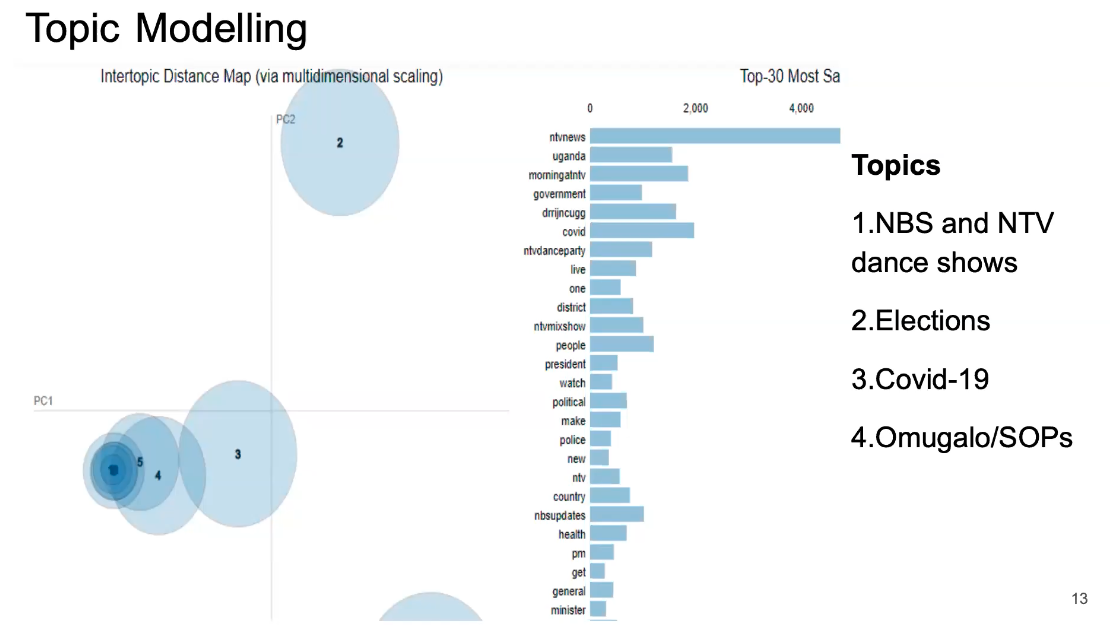
Figure: LDA topics and topic distance maps. Interspersed with the Covid-19 topics are topics associated with television dance shows, elections, and the president showing the importance of having domain knowledge.
Topic modeling highlights the different subjects present in the data, and how they interrelate.
- Annotation attributes:
- Data source [Facebook, Twitter]
- Language [English, Luganda, and codemixed]
- Aspect [truck drivers, hospitals, vaccine, cases, SOPs, NPIs, Testing, Border, Covid19_Impact, Presidential address, death, elections and Covid19]
- Sentiment [positive, negative and neutral]
- Misinformation [Not Fake, Fake, Partially Fake, and Others]
- As part of quality assurance, the data was reviewed by an independent team to ensure that the annotation guidelines were followed.}
Annotation carried out by seven annotators who could understand both English and Luganda. The data was labeled with the Doccano text annotation tool. Annotations included the data source, the language, the label, the sentiment, and the misinformation status.
Quality assurance performed by reviewing data with an independent team for ensuring annotation guidelines were followed.
Table: Portion of data that was annotated.
Initial dataset | 15,354 | 430,075 |
Dataset after Annotation | 3,527 | 4,479 |
Cohen’s kappa inter-annotation used to measure annotator agreement.
Table: Cohen’s kappa agreement scores for the data.
Aspect | 0.69 |
Sentiment | 0.73 |
Misinformation | 0.74 |
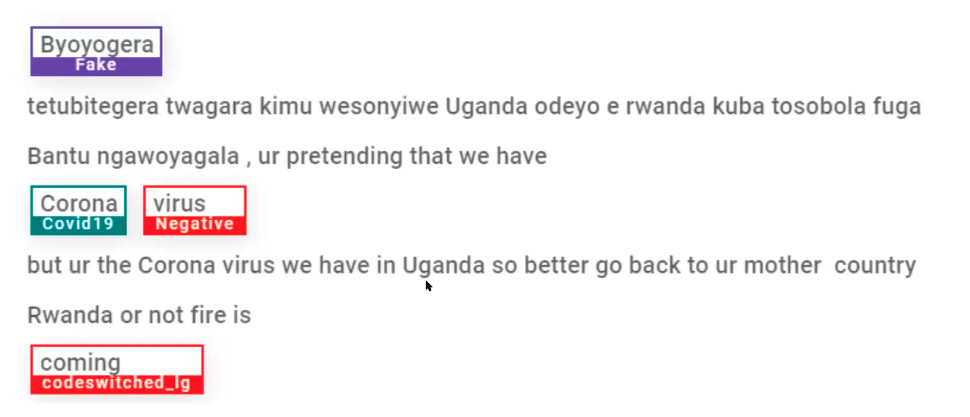
Figure: Example of data annotation for sentiment and misinformation from the data set.
The idea of the analysis is to bring this information together for sentiment and misinformation analysis in a dashboard for Covid-19 in Uganda.
Automating Assess
There are lots of interesting projects around automating the assessment of the data, for example one can consider automation of schema and data type detection (Valera and Ghahramani (2017)) or the AI for Data Analytics Project (see Nazábal et al. (2020) for an overview of issues and case studies and the video in Figure \(\ref{ai-for-data-analytics}\) for details on the project). We may even view projects like the automatic statistician as automating of assessment (James Robert Lloyd and Ghahramani. (2014)), although arguably one could suggest that the choice of data set used in those projects itself is reflective of the question or context. This highlights the difficulty in separating the aspects. The key quesiton to ask in any given context is whether the augmentation you are performing for the data set is going to be helpful or a hindrance to those that may wish to reuse your data.
Figure: The AI for Data Analytics project is an attempt to automate some of the challenges of automated data assessment.
Address
The final aspect of the process is to address the question. We’ll spend the least time on this aspect here, because it’s the one that is most widely formally taught and the one that most researchers are familiar with. In statistics, this might involve some confirmatory data analysis. In machine learning it may involve designing a predictive model. In many domains it will involve figuring out how best to visualise the data to present it to those who need to make the decisions. That could involve a dashboard, a plot or even summarisation in an Excel spreadsheet.
The address aspect is associated with data readiness level A (Lawrence (2017b)).
Automating Address
Perhaps the most widespread approach to automating the address aspect is known as AutoML (see video in Figure \(\ref{frank-hutter-automl}\)). This is an automatic approach to creating ML prediction models. The automatic statistician we mentioned in assess also has some of these goals in mind for automating confirmatory data analysis. But there are clearly other aspects we may wish to automate, particularly around visualization.
Figure: Here Frank Hutter gives a tutorial on AutoML, one of the approaches to automating address.
Fynesse Template

Figure: The Fynesse Template gives you a starting point for building your data science library. You can fork the template, and then create a new repository from the template. You can use that repository for your analysis.
To help you think about the aspects of the Fynesse data science framework, we’ve created a small GitHub template that’s available here. We suggest the following approach to using the template. Firstly: fork the template to your own GitHub account. Then you can base your analysis software on the template. If there are aspects to the template that you think need updating (including things you don’t like!), then you can update those and submit a pull request so that others can benefit.
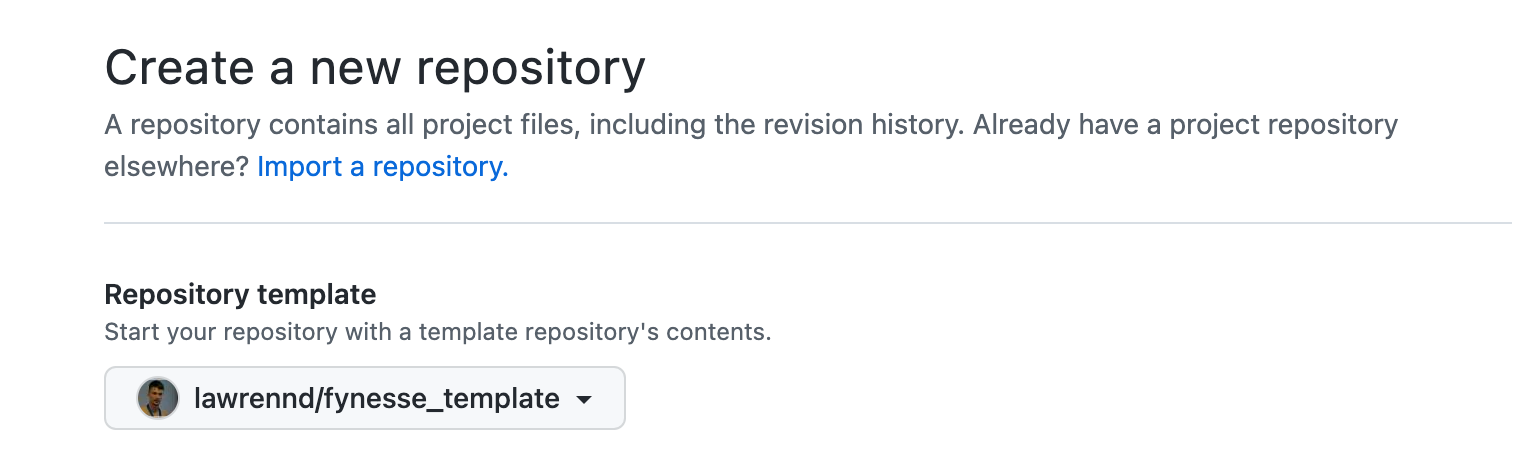
Figure: Setting up a new repository in github from a template. By basing your repository on the fynesse template, you will have a starting point for your analysis framework.
GitHub makes it easy to create a new repository from this framework. Although you should feel free to use your own tools for source code control if you find them more convenient.
Human Analogue Machine
Recent breakthroughs in generative models, particularly large language models, have enabled machines that, for the first time, can converse plausibly with other humans.
The Apollo guidance computer provided Armstrong with an analogy when he landed it on the Moon. He controlled it through a stick which provided him with an analogy. The analogy is based in the experience that Amelia Earhart had when she flew her plane. Armstrong’s control exploited his experience as a test pilot flying planes that had control columns which were directly connected to their control surfaces.
Figure: The human analogue machine is the new interface that large language models have enabled the human to present. It has the capabilities of the computer in terms of communication, but it appears to present a “human face” to the user in terms of its ability to communicate on our terms. (Image quite obviously not drawn by generative AI!)
The generative systems we have produced do not provide us with the “AI” of science fiction. Because their intelligence is based on emulating human knowledge. Through being forced to reproduce our literature and our art they have developed aspects which are analogous to the cultural proxy truths we use to describe our world.
These machines are to humans what the MONIAC was the British economy. Not a replacement, but an analogue computer that captures some aspects of humanity while providing advantages of high bandwidth of the machine.
HAM
The Human-Analogue Machine or HAM therefore provides a route through which we could better understand our world through improving the way we interact with machines.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
The HAM can provide an interface between the digital computer and the human allowing humans to work closely with computers regardless of their understandin gf the more technical parts of software engineering.
Figure: The HAM now sits between us and the traditional digital computer.
Of course this route provides new routes for manipulation, new ways in which the machine can undermine our autonomy or exploit our cognitive foibles. The major challenge we face is steering between these worlds where we gain the advantage of the computer’s bandwidth without undermining our culture and individual autonomy.
See Lawrence (2024) human-analogue machine (HAMs) p. 343-347, 359-359, 365-368.
What Next?
As a refresher, we’ve provided a notebook to remind yourselves about probability and correlation, https://mlatcl.github.io/advds/practicals/01-review-and-refresher.html. We recommend that you go through exercises of this notebook as soon as possible.
You can also make a start on the first practical, https://mlatcl.github.io/ads/practicals/ which covers AWS and SQL.
Further Reading
Chapter 5 of Lawrence (2024)
Chapter 1 of Lawrence (2024)
Chapter 1 of Lawrence (2024)
Chapter 8 of Lawrence (2024)
Thanks!
For more information on these subjects and more you might want to check the following resources.
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com