

Week 4: Deep Architectures
[jupyter][google colab][reveal]
Neil Lawrence
Abstract:
This lecture will explore what happens when we compose layers of basis functions together to form deep neural networks.
ML Foundations Course Notebook Setup
We install some bespoke codes for creating and saving plots as well as loading data sets.
%%capture
%pip install notutils
%pip install pods
%pip install mlaiimport notutils
import pods
import mlai
import mlai.plot as plotNeural Networks
Shallow and Deep Learning
So far, we have been talking about linear models or shallow learning as we might think of it. Let’s pause for a moment and consider a fully connected deep neural network model to relate the two ideas.
From Basis Functions to Neural Networks (JAX)
So far we have been using numpy for building our models. In this session we are going to make use of JAX.
import jax
import jax.numpy as jnp
from jax import random, grad, jit, value_and_grad
from functools import partial
## Linear Models as Basis + Weights
The generalised linear models we work with allow us to create a model that is non-linear in inputs, but linear in the parameters,
$$
\mappingFunction(\inputVector_i) = \mappingVector^\top \basisFunctionVector(\inputVector_i).
$$
We defined a basis, such as the quadratic basis.
```{.python}
import jax.numpy as jnpdef jax_quadratic(x, **kwargs):
"""Take in a vector of input values and return the design matrix associated with quadratic basis functions."""
return jnp.hstack([jnp.ones((x.shape[0], 1)), x, x**2])Here we’ve defined the function almost identically to the numpy version, only we imported jax.numpy instead of numpy.

Figure: A neural network. Input nodes are shown at the bottom. The hidden layer is the result of applying an affine transformation to the input layer and placing through an activation function.
We can plot the basis just like before.
## Parametric Basis Functions
We define parametric basis layers: affine transforms and non-linear activations. These combine to form neural networks.
## Multi-Layer Perceptron as Stacked Bases
## Loss and Training (JAX grad/jit)
We use squared error and train with gradient descent. JAX allows JIT compilation and automatic differentiation.
```{.python}
def mse_loss(params, x, y, apply_fn):
y_pred = apply_fn(params, x)
return jnp.mean((y_pred - y)**2)@jit
def update(params, x, y, lr, apply_fn):
loss, grads = value_and_grad(mse_loss)(params, x, y, apply_fn)
# Params is a list of dicts; apply tree map-style update
new_params = []
for p, g in zip(params, grads):
new_params.append({k: p[k] - lr * g[k] for k in p})
return new_params, lossDemo: Olympics Data with a Neural Network
Discussion
Deep Neural Network
%pip install daftFigure: A deep neural network. Input nodes are shown at the bottom. Each hidden layer is the result of applying an affine transformation to the previous layer and placing through an activation function.
Mathematically, each layer of a neural network is given through computing the activation function, \(\phi(\cdot)\), contingent on the previous layer, or the inputs. In this way the activation functions, are composed to generate more complex interactions than would be possible with any single layer. \[ \begin{align*} \mathbf{ h}_{1} &= \phi\left(\mathbf{W}_1 \mathbf{ x}\right)\\ \mathbf{ h}_{2} &= \phi\left(\mathbf{W}_2\mathbf{ h}_{1}\right)\\ \mathbf{ h}_{3} &= \phi\left(\mathbf{W}_3 \mathbf{ h}_{2}\right)\\ f&= \mathbf{ w}_4 ^\top\mathbf{ h}_{3} \end{align*} \]
Under our basis function perspective, we can see that our deep neural network is mathematical composition of basis function models. Each layer contains a separate basis function set, so \[ f(\mathbf{ x}; \mathbf{W}) = \mathbf{ w}_4 ^\top\phi\left(\mathbf{W}_3 \phi\left(\mathbf{W}_2\phi\left(\mathbf{W}_1 \mathbf{ x}\right)\right)\right). \]
In this course there are two reasons for looking at the shallow model. Firstly, it is easier to introduce the concepts of regularisation in the linear model regime. Secondly, the matrix forms we see, e.g., expressions like \(\boldsymbol{ \Phi}^\top \boldsymbol{ \Phi}\), appear in both models.
For deep learning, we can no longer optimise the parameters of the model through solving a linear system1. Instead, we need to turn to non-linear optimisation algorithms. For deep learning, that’s typically stochastic gradient descent.
While it’s possible to compute the Hessian in a neural network, Bishop (1992), we also find that it varies across the parameter space and will not normally be positive definite. In practice, the number of parameters is normally so large that storing the Hessian is impossible (it has quadratic cost in the number of weights/parameters) due to memory constraints.
This means that while the theory of minima in optimisation is well understood, empirical experiments with large neural networks are hard and the lessons of small models do not all translate to the very large systems.
We can stay within the framework of linear models but take a step closer to neural network models by introducing functions that are non-linear in the inputs, \(\mathbf{ x}\), known as basis functions.
Overparameterised Systems
If we could examine the Hessian of a neural network at its minimum, we can speculate about what we would find. In particular, we would find that it would have very many low (or negative) eigenvalues in many directions. This is indicative of the parameters being badly determined because of the neural network model being heavily overparameterised. So how does it generalise?
Simply put, there is not enough regularisation encoded in the objective function of the neural network models we are using to explain the generalisation performance. There must be something in the algorithms we are using that causes these highly overparameterised models to generalise well.
Generalization and Overfitting
Once a supervised learning system is trained it can be placed in a sequential pipeline to automate a process that used to be done manually.
Supervised learning is one of the dominant approaches to learning. But the cost and time associated with labeling data is a major bottleneck for deploying machine learning systems. The process for creating training data requires significant human intervention. For example, internationalization of a speech recognition system would require large speech corpora in new languages.
An important distinction in machine learning is the separation between training data and test data (or production data). Training data is the data that was used to find the model parameters. Test data (or production data) is the data that is used with the live system. The ability of a machine learning system to predict well on production systems given only its training data is known as its generalization ability. This is the system’s ability to predict in areas where it hasn’t previously seen data.
Olympic Marathon Data
|

|
.jpg){kind=link}
The Olympic Marathon data is a standard dataset for regression modelling. The data consists of the pace of Olympic Gold Medal Marathon winners for the Olympics from 1896 to present. Let’s load in the data and plot.
%pip install podsimport numpy as np
import podsdata = pods.datasets.olympic_marathon_men()
x = data['X']
y = data['Y']
offset = y.mean()
scale = np.sqrt(y.var())
yhat = (y - offset)/scaleFigure: Olympic marathon pace times since 1896.
Things to notice about the data include the outlier in 1904, in that year the Olympics was in St Louis, USA. Organizational problems and challenges with dust kicked up by the cars following the race meant that participants got lost, and only very few participants completed. More recent years see more consistently quick marathons.
Hold Out Validation on Olympic Marathon Data
Figure: Olympic marathon data with validation error for extrapolation.
Extrapolation
Interpolation
Figure: Olympic marathon data with validation error for interpolation.
Choice of Validation Set
Hold Out Data
You have a conclusion as to which model fits best under the training error, but how do the two models perform in terms of validation? In this section we consider hold out validation. In hold out validation we remove a portion of the training data for validating the model on. The remaining data is used for fitting the model (training). Because this is a time series prediction, it makes sense for us to hold out data at the end of the time series. This means that we are validating on future predictions. We will hold out data from after 1980 and fit the model to the data before 1980.
# select indices of data to 'hold out'
indices_hold_out = np.flatnonzero(x>1980)
# Create a training set
x_train = np.delete(x, indices_hold_out, axis=0)
y_train = np.delete(y, indices_hold_out, axis=0)
# Create a hold out set
x_valid = np.take(x, indices_hold_out, axis=0)
y_valid = np.take(y, indices_hold_out, axis=0)Exercise 1
For both the linear and quadratic models, fit the model to the data up until 1980 and then compute the error on the held out data (from 1980 onwards). Which model performs better on the validation data?
Richer Basis Set
Now we have an approach for deciding which model to retain, we can consider the entire family of polynomial bases, with arbitrary degrees.
Exercise 2
Now we are going to build a more sophisticated form of basis function, one that can accept arguments to its inputs (similar to those we used in this lab). Here we will start with a polynomial basis.
def polynomial(x, degree, loc, scale):
degrees =np.arange(degree+1)
return ((x-loc)/scale)**degreesThe basis as we’ve defined it has three arguments as well as the input. The degree of the polynomial, the scale of the polynomial and the offset. These arguments need to be passed to the basis functions whenever they are called. Modify your code to pass these additional arguments to the python function for creating the basis. Do this for each of your functions predict, fit and objective. You will find *args (or **kwargs) useful.
Write code that tries to fit different models to the data with polynomial basis. Use a maximum degree for your basis from 0 to 17. For each polynomial store the hold out validation error and the training error. When you have finished the computation plot the hold out error for your models and the training error for your p. When computing your polynomial basis use offset=1956. and scale=120. to ensure that the data is mapped (roughly) to the -1, 1 range.
Which polynomial has the minimum training error? Which polynomial has the minimum validation error?
Bias Variance Decomposition
One of Breiman’s ideas for improving predictive performance is known as bagging (Breiman, 1996). The idea is to train a number of models on the data such that they overfit (high variance). Then average the predictions of these models. The models are trained on different bootstrap samples (Efron, 1979) and their predictions are aggregated giving us the acronym, Bagging. By combining decision trees with bagging, we recover random forests (Breiman, 2001).
Bias and variance can also be estimated through Efron’s bootstrap (Efron, 1979), and the traditional view has been that there’s a form of Goldilocks effect, where the best predictions are given by the model that is ‘just right’ for the amount of data available. Not to simple, not too complex. The idea is that bias decreases with increasing model complexity and variance increases with increasing model complexity. Typically plots begin with the Mummy bear on the left (too much bias) end with the Daddy bear on the right (too much variance) and show a dip in the middle where the Baby bear (just) right finds themselves.
The Daddy bear is typically positioned at the point where the model can exactly interpolate the data. For a generalized linear model (McCullagh and Nelder, 1989), this is the point at which the number of parameters is equal to the number of data2.
The bias-variance decomposition (Geman et al., 1992) considers the expected test error for different variations of the training data sampled from, \(\mathbb{P}(\mathbf{ x}, y)\) \[\begin{align*} R(\mathbf{ w}) = & \int \left(y- f^*(\mathbf{ x})\right)^2 \mathbb{P}(y, \mathbf{ x}) \text{d}y\text{d}\mathbf{ x}\\ & \triangleq \mathbb{E}\left[ \left(y- f^*(\mathbf{ x})\right)^2 \right]. \end{align*}\]
This can be decomposed into two parts, \[ \begin{align*} \mathbb{E}\left[ \left(y- f(\mathbf{ x})\right)^2 \right] = & \text{bias}\left[f^*(\mathbf{ x})\right]^2 + \text{variance}\left[f^*(\mathbf{ x})\right] +\sigma^2, \end{align*} \] where the bias is given by \[ \text{bias}\left[f^*(\mathbf{ x})\right] = \mathbb{E}\left[f^*(\mathbf{ x})\right] - f(\mathbf{ x}) \] and it summarizes error that arises from the model’s inability to represent the underlying complexity of the data. For example, if we were to model the marathon pace of the winning runner from the Olympics by computing the average pace across time, then that model would exhibit bias error because the reality of Olympic marathon pace is it is changing (typically getting faster).
The variance term is given by \[ \text{variance}\left[f^*(\mathbf{ x})\right] = \mathbb{E}\left[\left(f^*(\mathbf{ x}) - \mathbb{E}\left[f^*(\mathbf{ x})\right]\right)^2\right]. \] The variance term is often described as arising from a model that is too complex, but we must be careful with this idea. Is the model really too complex relative to the real world that generates the data? The real world is a complex place, and it is rare that we are constructing mathematical models that are more complex than the world around us. Rather, the ‘too complex’ refers to ability to estimate the parameters of the model given the data we have. Slight variations in the training set cause changes in prediction.
Models that exhibit high variance are sometimes said to ‘overfit’ the data whereas models that exhibit high bias are sometimes described as ‘underfitting’ the data.
Bias vs Variance Error Plots
Helper function for sampling data from two different classes.
import numpy as npHelper function for plotting the decision boundary of the SVM.
import urllib.requesturllib.request.urlretrieve('https://raw.githubusercontent.com/lawrennd/talks/gh-pages/mlai.py','mlai.py')import matplotlib
font = {'family' : 'sans',
'weight' : 'bold',
'size' : 22}
matplotlib.rc('font', **font)
import matplotlib.pyplot as pltfrom sklearn import svm# Create an instance of SVM and fit the data.
C = 100.0 # SVM regularization parameter
gammas = [0.001, 0.01, 0.1, 1]
per_class=30
num_samps = 20
# Set-up 2x2 grid for plotting.
fig, ax = plt.subplots(1, 4, figsize=(10,3))
xlim=None
ylim=None
for samp in range(num_samps):
X, y=create_data(per_class)
models = []
titles = []
for gamma in gammas:
models.append(svm.SVC(kernel='rbf', gamma=gamma, C=C))
titles.append('$\gamma={}$'.format(gamma))
models = (cl.fit(X, y) for cl in models)
xlim, ylim = decision_boundary_plot(models, X, y,
axs=ax,
filename='bias-variance{samp:0>3}.svg'.format(samp=samp),
directory='./ml'
titles=titles,
xlim=xlim,
ylim=ylim)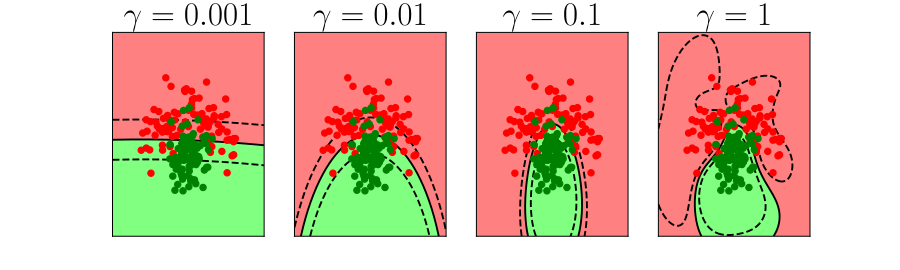
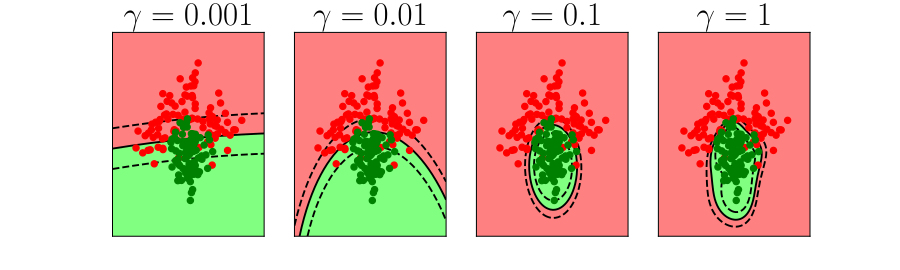
Figure: In each figure the simpler model is on the left, and the more complex model is on the right. Each fit is done to a different version of the data set. The simpler model is more consistent in its errors (bias error), whereas the more complex model is varying in its errors (variance error).
Overfitting
Figure: Alex Ihler discusses polynomials and overfitting.
We can easily develop a simple prediction function that reconstructs the training data exactly, you can just use a look up table. But how would the lookup table predict between the training data, where examples haven’t been seen before? The choice of the class of prediction functions is critical in ensuring that the model generalizes well.
The generalization error is normally estimated by applying the objective function to a set of data that the model wasn’t trained on, the test data. To ensure good performance we normally want a model that gives us a low generalization error. If we weren’t sure of the right prediction function to use, then we could try 1,000 different prediction functions. Then we could use the one that gives us the lowest error on the test data. But you have to be careful. Selecting a model in this way is like a further stage of training where you are using the test data in the training.3 So when this is done, the data used for this is not known as test data, it is known as validation data. And the associated error is the validation error. Using the validation error for model selection is a standard machine learning technique, but it can be misleading about the final generalization error. Almost all machine learning practitioners know not to use the test data in your training procedure, but sometimes people forget that when validation data is used for model selection that validation error cannot be used as an unbiased estimate of the generalization performance.
From Shallow to Deep
A fully-connected deep network composes linear transforms and elementwise non-linearities. Under the basis-function perspective, each layer provides a new basis evaluated on the transformed inputs, then linearly combined and fed forward.
\[ f(\mathbf{ x}; \mathbf{W}) = \mathbf{ w}_4 ^\top\phi\left(\mathbf{W}_3 \phi\left(\mathbf{W}_2\phi\left(\mathbf{W}_1 \mathbf{ x}\right)\right)\right). \]
Gradient-based optimization
\[ \mathscr{L}(\theta) = \sum_{n=1}^N \ell(y_n, f(x_n, \theta)) \]
\[ \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}(\theta) \]
Basic Multilayer Perceptron
\[ \small f_L(x) = \boldsymbol{ \phi}\left(b_L + W_L \boldsymbol{ \phi}\left(b_{L-1} + W_{L-1} \boldsymbol{ \phi}\left( \cdots \boldsymbol{ \phi}\left(b_1 + W_1 x\right) \cdots \right)\right)\right) \]
Recursive MLP Definition
Rectified Linear Unit
Placeholder figure: basic ReLU shape (zero for negative inputs, identity for positive).
Other activation functions that are used include hyperbolic tangent, sigmoid, ELU, leaky ReLU. Although ReLU is often preferred for simplicity and fast gradient computation.
Shallow ReLU Networks
A single layer ReLU network is functionally equivalent to a generalised linear model with a ReLU basis. The difference is that we optimise over the basis function inputs.
Each hidden unit acts as a basis function with its own kink location and slope.
Depth vs Width: Representation Power
ReLU networks implement piecewise-linear functions; width increases the number of linear pieces roughly linearly, depth increases them exponentially.
Sawtooth Construction
Illustrative 1D construction showing exponential growth of segments with depth.
In higher dimensions, these become polyhedral regions with constant gradients inside each region.
Placeholder mini-figures: depth \(0,1,2,3,4,5\) outputs of the sawtooth network showing doubling segments at each step.
Higher-dimensional Geometry
In 2D, ReLU networks partition input space into many polygonal regions. Within each region the mapping is linear, yet globally the function is continuous because adjacent regions meet with consistent boundary values. Depth increases the number and intricacy of these regions across layers.
Placeholder figure: 2D piecewise-linear tiling (e.g., Hanin and Rolnick, 2019) with coloured regions indicating distinct linear pieces.
Suggested visual: reuse figures showing partitioned 2D input space with coloured linear regions. If needed, include links or embed static images used in prior notes.
Generalisation in Deep Networks
Neural nets are heavily overparameterised. Classical generalisation bounds based purely on hypothesis class complexity are pessimistic. Empirically, training algorithms exhibit an inductive bias toward solutions that generalise.
In the overparameterised regime there is not a single training optimum but a of zero-training-loss solutions (an interpolation manifold). Gradient-based optimisation tends to prefer certain members of this set that generalise better (“nice interpolants”). This preference is an of the algorithm.
Additional reading placeholders: Hanin and Rolnick (2019) on typical linear-region counts; Pérez et al. (2019) on parameter-to-function bias toward simplicity; Arora et al. (2019) on deep linear models and implicit biases from parametrisation and initialisation.
Double Descent
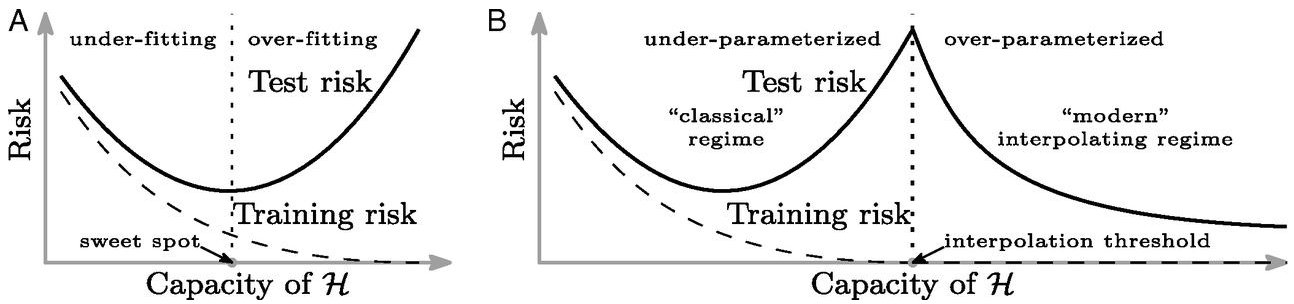
Figure: Left traditional perspective on generalization. There is a sweet spot of operation where the training error is still non-zero. Overfitting occurs when the variance increases. Right The double descent phenomenon, the modern models operate in an interpolation regime where they reconstruct the training data fully but are well regularized in their interpolations for test data. Figure from Belkin et al. (2019).
But the modern empirical finding is that when we move beyond Daddy bear, into the dark forest of the massively overparameterized model we can achieve good generalization. Indeed, recent work is showing that large language models are even memorizing data (Carlini et al., 2020) like non-parametric models do.
As Zhang et al. (2017) starkly illustrated with their random labels experiment, within the dark forest there are some terrible places, big bad wolves of overfitting that will gobble up your model. But as empirical evidence shows there is also a safe and hospitable Grandma’s house where these highly overparameterized models are safely consumed. Fundamentally, it must be about the route you take through the forest, and the precautions you take to ensure the wolf doesn’t see where you’re going and beat you to the door.
There are two implications of this empirical result. Firstly, that there is a great deal of new theory that needs to be developed. Secondly, that theory is now obliged to conflate two aspects to modelling that we generally like to keep separate: the model and the algorithm.
Classical statistical theory around predictive generalization focusses specifically on the class of models that is being used for data fitting. Historically, whether that theory follows a Fisher-aligned estimation approach (see e.g., Vapnik (1998)) or model-based Bayesian approach (see e.g., Ghahramani (2015)), neither is fully equipped to deal with these new circumstances because, to continue our rather tortured analogy, these theories provide us with a characterization of the destination of the algorithm, and seek to ensure that we reach that destination. Modern machine learning requires theories of the journey and what our route through the forest should be.
Crucially, the destination is always associated with 100% accuracy on the training set. An objective that is always achievable for the overparameterized model.
Intuitively, it seems that a highly overparameterized model places Grandma’s house on the edge of the dark forest. Making it easily and quickly accessible to the algorithm. The larger the model, the more exposed Grandma’s house becomes. Perhaps this is due to some form of blessing of dimensionality brings Grandma’s house closer to the edge of the forest in a high dimensional setting. Really, we should think of Grandma’s house as a low dimensional manifold of destinations that are safe. A path through the forest where the wolf of overfitting doesn’t venture. In the GLM case, we know already that when the number of parameters matches the number of data there is precisely one location in parameter space where accuracy on the training data is 100%. Our previous misunderstanding of generalization stemmed from the fact that (seemingly) it is highly unlikely that this single point is a good place to be from the perspective of generalization. Additionally, it is often difficult to find. Finding the precise polynomial coefficients in a least squares regression to exactly fit the basis to a small data set such as the Olympic marathon data requires careful consideration of the numerical properties and an orthogonalization of the design matrix (Lawson and Hanson, 1995).
It seems that with a highly overparameterized model, these locations become easier to find and they provide good generalization properties. In machine learning this is known as the “double descent phenomenon” (see e.g., Belkin et al. (2019)).
Diagram from (Nakkiran-deepdouble19?)
See also this talk by Misha Belkin: http://www.ipam.ucla.edu/abstract/?tid=15552&pcode=GLWS4 and these related papers https://www.pnas.org/content/116/32/15849.short, https://www.pnas.org/content/117/20/10625
Neural Tangent Kernel
Another approach to analysis exploits the fact that optimization is occurring in a very high dimensional parameter space. By considering initializations that involve small random weights (known as the NTK initialization) and noting that small updates in the learning mean that the model doesn’t move far from this initialization (Jacot et al., 2018).
For very wide neural networks, when these conditions are fulfilled, the network can be approximately represented by a kernel known as the neural tangent kernel. A kernel is a regularizer that operates in function space rather than feature space.
Regularization in Optimization
Another interesting theoretical direction is to study the path that neural network algorithms take when finding the optima. For certain simple linear systems, you can analytically study the ‘gradient flow.’
Neural networks are normally trained by (stochastic) gradient descent. This is a discrete optimization algorithm where at each point, a step in the direction of the (approximate) gradient is taken.
Gradient flow replaces this discrete update with a differential equation, where the step at any point is an exact gradient update. As a result, the path of the optimization can be studied as a differential equation.
By making assumptions about the initialization, the optimum that gradient flow will find can be characterised. For a highly overparameterized linear model, Gunasekar et al. (2017) show in matrix factorization, that for particular initializations, the optimum will be a global optimum of the objective that minimizes the L2-norm.
By reparameterizing the linear model so that each \(w_i = u_i^2 - v_i^2\) and optimising in the space defined by \(\mathbf{u}\) and \(\mathbf{v}\) Woodworth et al. (2020) show that the L1 norm is found.
Other papers have looked at deep linear models (Arora et al., 2019) where \[ f(\mathbf{ x}; \mathbf{W}) = \mathbf{W}_4 \mathbf{W}_3 \mathbf{W}_2 \mathbf{W}_1 \mathbf{ x}. \] In these models, a gradient flow analysis shows that the model finds solutions where the linear mapping, \[ \mathbf{W}= \mathbf{W}_4 \mathbf{W}_3 \mathbf{W}_2 \mathbf{W}_1 \] is very low rank. This is highly suggestive of another type of regularization that could be occurring in deep neural networks. Low rank parameter matrices mean that the effective capacity of the neural network is reduced. Indeed, empirical observations of the rank of deep nets trained on data suggest that they may be finding such solutions.
Chain Rule and Back Propgation
When Rosenblatt built his Perceptron model in 1957, he used multiple layers of units, that he called association units, to take advantage of the deep structure he gave these units random weights. In modern deep learning we adjust these weights to minimise the error.
From the basis function perspective, we have parameters in our basis function vectors, \(\boldsymbol{ \phi}(\mathbf{ x}; \mathbf{V})\) that can be adjusted. They are non-linearly related to the output so that makes these models non-linear both in terms of the dependence on inputs and the dependence on parameters.
To compute derivatives we now need to compute the derivation of the system with respect to the basis functions. \[ f(\mathbf{ x}_i) = \mathbf{ w}^\top \boldsymbol{ \phi}(\mathbf{ x}_i; \mathbf{V}). \] We already have the gradient with respect to \(\mathbf{ w}\), which is simply. \[ \frac{\text{d}f_i}{\text{d}\mathbf{ w}} = \boldsymbol{ \phi}(\mathbf{ x}_i; \mathbf{V}), \] we now need the gradient with respect to \(\mathbf{ v}\). This can be computed by the chain rule as, \[ \frac{\text{d}f^L_i}{\text{d}\mathbf{V}} = \frac{\text{d}f_i}{\text{d}\boldsymbol{ \phi}_i}\frac{\text{d}\boldsymbol{ \phi}_i}{\text{d} \mathbf{V}}. \] But we have to be acareful here. This is the chain rule, but it contains a new challenge, \(\frac{\text{d}\boldsymbol{ \phi}_i}{\text{d} \mathbf{V}}\) is the derivative of a vector with respect to a matrix. How do we deal with this?
Matrix Vector Chain Rule
There are several standards for how to perform the chain rule with multivariate calculus. My favourite is from Mike Brookes. The details are given by Brookes (2005).
How do we write the derivative of a vector with respect to a matrix or a matrix with a respect to a matrix? In Brookes’s approach the first rule is that you never compute these directly. Instead you form an intermediate stacking operation.
Matrix Stacking
A stacking operation takes a matrix, \(\mathbf{A}\), and rewrites it as a vector where each column of \(\mathbf{A}\) is stacked on top of one another to give a new vector \(\mathbf{a}\), \[ \mathbf{a} = \begin{bmatrix} \mathbf{a}_{:, 1}\\ \mathbf{a}_{:, 2}\\ \vdots\\ \mathbf{a}_{:, q} \end{bmatrix} \]
Next we consider the derivative of one vector with respect to another as \[ \frac{\text{d} \mathbf{a}}{\text{d} \mathbf{b}} \in \Re^{m \times n} \] if \(\mathbf{a} \in \Re^{m \times 1}\) and \(\mathbf{b} \in \Re^{n \times 1}\).
This now means that to obtain matrix-matrix derivatives we make use of \(\mathbf{C}:\): to indicate a vector formed from the matrix \(\mathbf{C}\) by stacking the columns of \(\mathbf{C}\) to form a \(\Re^{m n \times 1}\) vector if \(\mathbf{C} \in \Re^{m \times n}\).
Under this notation we can write the derivative of a matrix \(\mathbf{E} \in \Re^{p \times q}\) with respect to \(\mathbf{C}\) as \(\frac{\text{d} \mathbf{E}}{\text{d} \mathbf{C}} \in \Re^{p q \times m n}\). This notation makes it easier to apply the chain rule while maintaining matrix notation.
This entails the use of Kronecker products, we denote the Kronecker product of \(\mathbf{F}\) and \(\mathbf{G}\) as \(\mathbf{F} \otimes \mathbf{G}\).
Kronecker Products
{In most cases Kronecker products they arise below they are later removed using this relationship \[ (\mathbf{E}:)^{\top} \mathbf{F} \otimes \mathbf{G}=\left(\left(\mathbf{G}^{\top} \mathbf{E F}\right):\right)^{\top} \] this form typically arises whenever the chain rule is applied, \[ \frac{\text{d} E}{\text{d} \mathbf{H}:} \frac{\text{d} \mathbf{H}:}{\text{d} \mathbf{J}:}=\frac{\text{d} E}{\text{d} \mathbf{J}:}, \]
as we normally find that \(\frac{\text{d} \mathbf{H}}{\text{d} \mathbf{J}}\) has the form of a Kronecker product, \(\frac{\text{d} \mathbf{H}}{\text{d} \mathbf{J}}=\mathbf{F} \otimes \mathbf{G}\) and we expect the result of \(\frac{\text{d} E}{\text{d} \mathbf{H}}\) and \(\frac{\text{d} E}{\text{d} \mathbf{J}}\) to be in the form \((\mathbf{E}:)^{\mathbf{T}}\). The following two identities for Kronecker products will also prove useful. \[ \mathbf{F}^{\top} \otimes \mathbf{G}^{\top}=(\mathbf{F} \otimes \mathbf{G})^{\top} \] and \[ (\mathbf{E} \otimes \mathbf{G})(\mathbf{F} \otimes \mathbf{H})=\mathbf{E F} \otimes \mathbf{G H} \] Generally we will use two ways of writing the derivative of a scalar with respect to a matrix, \(\frac{\text{d} E}{\text{d} \mathbf{J}}\) and \(\frac{\text{d} E}{\text{d} \mathbf{J}}\), the first being a row vector and the second is a matrix of the same dimension of \(\mathbf{J}\). The second representation is more convenient for summarising the result, the first is easier to wield when computing the result. The equivalence of the representations is given by \[ \frac{\text{d} E}{\text{d} \mathbf{J}:}=\left(\left(\frac{\text{d} E}{\text{d} \mathbf{J}}\right):\right)^{\top}. \]
Any other results used for matrix differentiation and not explicitly given here may be found in Brookes [2005].
Useful Multivariate Derivatives
By defining our multivariate derivatives through vectors, we can now write down the results for some more useful multivariate derivatives. Let’s start with \(\mathbf{b} = \mathbf{A}\mathbf{x}\) and assume we want the gradient of \(\mathbf{b}\) with respect to \(\mathbf{A}\). We assume that \(\mathbf{A} \in \Re^{m\times n}\). To derive the gradient we’ll get there slightly indirectly and consider the gradient of \(\mathbf{b}\) first, \[ \frac{\text{d}}{\text{d} \mathbf{a^\prime}} \mathbf{A} \mathbf{x} \] which must be a matrix of size \(m \times mn\). Here we’ve taken the unusual step of defining \(\mathbf{a^\prime} = \left(\mathbf{A}^\top\right):\). We construct this form because it means that we are forming \(\mathbf{a}^\prime\) by stacking the columns of \(\mathbf{A}^\top\), which are the rows of \(\mathbf{A}\).
This makes the derivation straightforward by inspection because the vector \(\mathbf{b} = \mathbf{A}\mathbf{x}\) is a vector formed of inner products of the different rows of \(\mathbf{A}\), \[ \mathbf{A}\mathbf{x} = \begin{bmatrix} \mathbf{a}_{1, :}^\top \mathbf{x} \\ \mathbf{a}_{2, :}^\top \mathbf{x} \\ \vdots \\ \mathbf{a}_{m, :}^\top \mathbf{x} \end{bmatrix}. \] Recall that the gradient \[ \frac{\text{d}\mathbf{a}_{i,:}^\top \mathbf{x}}{\text{d}\mathbf{a}_{i,:}} = \mathbf{x}, \] where \(\mathbf{a}_{i, :}\) is a vector formed from the \(i\)th column of \(\mathbf{A}\). So this means means that we should expect our result to consist only of repeated versions of \(\mathbf{x}\). From our definition of vector derivatives, we know we are looking for a result with \(m\) rows and \(nm\) columns. This is where the Kronecker product comes in. We note that \(\mathbf{I}\otimes \mathbf{x}^\top\) provides a tiling of \(\mathbf{x}\) of the form, \[ \mathbf{I}_m \otimes \mathbf{x}^\top = \begin{bmatrix} \mathbf{x}^\top & \mathbf{0}& \cdots & \mathbf{0}\\ \mathbf{0}& \mathbf{x}^\top & \cdots & \mathbf{0}\\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{0}& \mathbf{0}& \cdots& \mathbf{x}^\top \end{bmatrix}. \] where \(\mathbf{I}_m\) is the \(m\) dimensional identity matrix. So this means we can write, \[ \frac{\text{d}}{\text{d} \mathbf{a^\prime}} \mathbf{A} \mathbf{x} = \mathbf{I}_{m} \otimes \mathbf{x}^\top \] because we can see that each row of this matrix contains the derivative of \(b_i = \mathbf{a}_{i, :}^\top \mathbf{x}\) with respect to \(\mathbf{a}^\prime\), wherewe constructed \(\mathbf{a}^\prime\) to be the stacking of the rows of \(\mathbf{A}\). The elements are zero apart from those associated with \(\mathbf{a}_{i, :}\) where the elements are \(\mathbf{x}\).
Now, to get the gradient with respect to \(\mathbf{a} = \mathbf{A}:\) instead of with respect to \(\mathbf{a}^\prime\) we reverse the order of the Kronecker product \[ \frac{\text{d}}{\text{d} \mathbf{a^\prime}} \mathbf{A} \mathbf{x} = \mathbf{x}^\top \otimes \mathbf{I}_{m} \] which disperses the elements of \(\mathbf{x}\) across the matrix, \[ \mathbf{x}^\top \otimes \mathbf{I}_{m} = \begin{bmatrix} x_1 \mathbf{I}_m & x_2 \mathbf{I}_m & \cdot & x_n \mathbf{I}_m \end{bmatrix} \] and is the correct for when we are stacking the columns of $.
Chain Rule for Neural Networks
We’re now in a position to write down the chain rule for neural networks.
To make our derivations general, we will split up the neural network in the following way. First we describe the activations at layer \(\ell\), \(\mathbf{ f}_\ell\) given the basis functions from the previous layer, \(\boldsymbol{ \phi}_{\ell-1}\) in terms of the weight matrix, \(\mathbf{W}_\ell\). \[ \mathbf{ f}_\ell= \mathbf{W}_\ell\boldsymbol{ \phi}_{\ell-1} \] where the basis vector at any given layer \(\ell\) is given by applying the basis functions to the activations, \[ \boldsymbol{ \phi}_{\ell} = \boldsymbol{ \phi}_{\ell}(\mathbf{ f}_{\ell}), \] where \(\mathbf{ f}_{\ell}(\cdot)\) represents the form of the basis functions at the \(\ell\)th layer. These two equations give us everything we need apart from the first layer and final layers where we have \[ f_1 = \mathbf{W}_1 \mathbf{ x} \] for the first layer. Here we are not showing the index on the data point \(i\) to avoid cluttering the notation. In the final layer we have the output of the network given by the inverse link function, \[ \mathbf{h} = \mathbf{h}(\mathbf{ f}_L). \] so we can assume dummy-basis functions for the output layer and take \(\mathbf{h} = \boldsymbol{ \phi}_L\).
This formalism isn’t fully general as it doesn’t capture the possibility of skip connections where a weight matrix connects e.g. basis functions from layer \(\ell-2\) to the activations of layer \(\ell\). But it’s sufficient to capture the main aspects of deep neural network gradients.
These fundamental operations now allow us to use our matrix derivative rules to compute the gradients of the neural network with respect to any layer of weights. To do this we need three fundamental gradients. First the activation gradient, \(\tfrac{\text{d}\mathbf{ f}_\ell}{\text{d}\mathbf{ w}_\ell}\) where we have defined \(\mathbf{ f}_\ell= (\mathbf{ f}_\ell)\!:\). This gradient is between a \(d_\ell\) dimensional vector, \(\mathbf{ f}_\ell\), and a \((d_{\ell-1})d\times 1\) dimensional vector, so it produces a matrix that is \(d_\ell\times (d_{\ell-1} d)\), \[ \frac{\text{d}\mathbf{ f}_\ell}{\text{d}\mathbf{ w}_\ell} = \boldsymbol{ \phi}_{\ell-1}^\top \otimes \mathbf{I}_{d_\ell}. \]
We represent the gradient \[ \frac{\text{d}\boldsymbol{ \phi}_{\ell}}{\text{d} \mathbf{ f}_{\ell}} = \boldsymbol{ \Phi}^\prime \] which is a \(d_\ell\times d_\ell\) sized matrix whose elements are given by \[ \frac{\text{d}\phi_i^{(\ell)}(\mathbf{ f}_{\ell})}{\text{d} f_j^{(\ell)}} \] where \(\phi_i^{(\ell)}(\mathbf{ f}_{\ell})\) is the \(i\)th basis function from the \(\ell\)th layer and \(f_j^{(\ell)}\) is the \(j\)th activation from the same layer. If \(\phi_i^{(\ell)}(\mathbf{ f}_{\ell}) = \phi_i^{(\ell)}(f^{(\ell)}_i)\) then this matrix is diagonal.
Then we have the across layer gradients \[ \frac{\text{d}\mathbf{ f}_\ell}{\text{d}\boldsymbol{ \phi}_{\ell-1}} = \mathbf{W}_\ell, \] which should be a \(d_\ell\times d_{\ell-1}\) size matrix, which matches the shape of \(\mathbf{W}_\ell\).
This now gives us the ability to compute the gradient of any \(\mathbf{W}_\ell\) in the model, \[ \frac{\text{d} \mathbf{ f}_\ell}{\text{d}\mathbf{ w}_{\ell-k}} = \left[\prod_{i=0}^{k-1} \frac{\text{d} \mathbf{ f}_{\ell - i}}{\text{d} \boldsymbol{ \phi}_{\ell - i -1}}\frac{\text{d} \boldsymbol{ \phi}_{\ell - i -1}}{\text{d} \mathbf{ f}_{\ell - i -1}}\right] \frac{\text{d} \mathbf{ f}_{\ell-k}}{\text{d} \mathbf{ w}_{\ell - k}} \]
Evaluating Derivatives
See also the presentation by Ferenc Huszár on the Deep Neural Network course at the University of Cambridge. Ferenc’s original slides are here and his notes on approximating with ReLU are here. His notes on automatic differentiation are here. His Google colab notebook is here. He also recommended a review paper from JMLR Baydin et al. (2018) (See Figure 2).
The chain of matrix multiplications gives us a choice about how we evaluate this system. \[ \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ w}} = \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ f}_{L-1}} \frac{\text{d} \mathbf{ f}_{L-1}}{\text{d} \mathbf{ f}_{L-2}} \frac{\text{d} \mathbf{ f}_{L-2}}{\text{d} \mathbf{ f}_{L-3}} \cdots \frac{\text{d} \mathbf{ f}_3}{\text{d} \mathbf{ f}_{2}} \frac{\text{d} \mathbf{ f}_2}{\text{d} \mathbf{ f}_{1}} \frac{\text{d} \mathbf{ f}_1}{\text{d} \mathbf{ w}} \]
\[ \small \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ w}} = \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ f}_{L-1}} \left( \frac{\text{d} \mathbf{ f}_{L-1}}{\text{d} \mathbf{ f}_{L-2}} \left( \frac{\text{d} \mathbf{ f}_{L-2}}{\text{d} \mathbf{ f}_{L-3}} \cdots \left( \frac{\text{d} \mathbf{ f}_3}{\text{d} \mathbf{ f}_{2}} \left( \frac{\text{d} \mathbf{ f}_2}{\text{d} \mathbf{ f}_{1}} \frac{\text{d} \mathbf{ f}_1}{\text{d} \mathbf{ w}} \right) \right) \cdots \right) \right) \]
Or like this?
\[ \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ w}} = \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ f}_{L-1}} \frac{\text{d} \mathbf{ f}_{L-1}}{\text{d} \mathbf{ f}_{L-2}} \frac{\text{d} \mathbf{ f}_{L-2}}{\text{d} \mathbf{ f}_{L-3}} \cdots \frac{\text{d} \mathbf{ f}_3}{\text{d} \mathbf{ f}_{2}} \frac{\text{d} \mathbf{ f}_2}{\text{d} \mathbf{ f}_{1}} \frac{\text{d} \mathbf{ f}_1}{\text{d} \mathbf{ w}} \]
\[ \small \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ w}} = \left( \left( \cdots \left( \left( \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ f}_{L-1}} \frac{\text{d} \mathbf{ f}_{L-1}}{\text{d} \mathbf{ f}_{L-2}} \right) \frac{\text{d} \mathbf{ f}_{L-2}}{\text{d} \mathbf{ f}_{L-3}} \right) \cdots \frac{\text{d} \mathbf{ f}_3}{\text{d} \mathbf{ f}_{2}} \right) \frac{\text{d} \mathbf{ f}_2}{\text{d} \mathbf{ f}_{1}} \right) \frac{\text{d} \mathbf{ f}_1}{\text{d} \mathbf{ w}} \]
Or in a funky way?
\[ \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ w}} = \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ f}_{L-1}} \frac{\text{d} \mathbf{ f}_{L-1}}{\text{d} \mathbf{ f}_{L-2}} \frac{\text{d} \mathbf{ f}_{L-2}}{\text{d} \mathbf{ f}_{L-3}} \cdots \frac{\text{d} \mathbf{ f}_3}{\text{d} \mathbf{ f}_{2}} \frac{\text{d} \mathbf{ f}_2}{\text{d} \mathbf{ f}_{1}} \frac{\text{d} \mathbf{ f}_1}{\text{d} \mathbf{ w}} \]
\[ \small \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ w}} = \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ f}_{L-1}} \left( \left( \left( \frac{\text{d} \mathbf{ f}_{L-1}}{\text{d} \mathbf{ f}_{L-2}} \right) \frac{\text{d} \mathbf{ f}_{L-2}}{\text{d} \mathbf{ f}_{L-3}} \right) \left( \left( \cdots \frac{\text{d} \mathbf{ f}_3}{\text{d} \mathbf{ f}_{2}} \right) \frac{\text{d} \mathbf{ f}_2}{\text{d} \mathbf{ f}_{1}} \right) \right)\frac{\text{d} \mathbf{ f}_1}{\text{d} \mathbf{ w}} \]
Automatic differentiation
Forward-mode
\[ \small \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ w}} = \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ f}_{L-1}} \left( \frac{\text{d} \mathbf{ f}_{L-1}}{\text{d} \mathbf{ f}_{L-2}} \left( \frac{\text{d} \mathbf{ f}_{L-2}}{\text{d} \mathbf{ f}_{L-3}} \cdots \left( \frac{\text{d} \mathbf{ f}_3}{\text{d} \mathbf{ f}_{2}} \left( \frac{\text{d} \mathbf{ f}_2}{\text{d} \mathbf{ f}_{1}} \frac{\text{d} \mathbf{ f}_1}{\text{d} \mathbf{ w}} \right) \right) \cdots \right) \right) \]
Cost: \[ \small d_0 d_1 d_2 + d_0 d_2 d_3 + \ldots + d_0 d_{L-1} d_L= d_0 \sum_{\ell=2}^{L} d_\ell d_{\ell-1} \]
Reverse-mode
\[ \small \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ w}} = \left( \left( \cdots \left( \left( \frac{\text{d} \mathbf{ f}_L}{\text{d} \mathbf{ f}_{L-1}} \frac{\text{d} \mathbf{ f}_{L-1}}{\text{d} \mathbf{ f}_{L-2}} \right) \frac{\text{d} \mathbf{ f}_{L-2}}{\text{d} \mathbf{ f}_{L-3}} \right) \cdots \frac{\text{d} \mathbf{ f}_3}{\text{d} \mathbf{ f}_{2}} \right) \frac{\text{d} \mathbf{ f}_2}{\text{d} \mathbf{ f}_{1}} \right) \frac{\text{d} \mathbf{ f}_1}{\text{d} \mathbf{ w}} \]
Cost: \[ \small d_Ld_{L-1}d_{L-2} + d_{L}d_{L-2} d_{L-3} + \ldots + d_Ld_{1} d_0 = d_L\sum_{\ell=0}^{L-2}d_\ell d_{\ell+1} \]
Memory cost of autodiff
Let \(d_l\) denote the output dimensionality at layer \(l\). Jacobians are evaluated at intermediate activations \(\mathbf{ f}_l\).
Forward-mode
Placeholder figure: forward-mode memory footprint (streaming through layers).
Reverse-mode
Placeholder figure: reverse-mode memory footprint (cached activations reused in backward).
Automatic differentiation
- in deep learning we’re most interested in scalar objectives
- \(d_L=1\), consequently, backward mode is always optimal
- in the context of neural networks this is backpropagation.
- backprop has higher memory cost than forwardprop
Backprop in deep networks
For gradients of scalar objectives (\(d_L=1\)), reverse-mode is computationally optimal and standard. Memory can be reduced via checkpointing/rematerialisation at extra compute cost.
Computational Graphs and PyTorch Autodiff
Modern frameworks build a dynamic computational graph as you compute, then traverse it in reverse to accumulate gradients.
Minimal PyTorch example (CPU/GPU agnostic):
import torch as th
x = th.tensor(4.0, requires_grad=True)
y = th.tensor(2.0)
f = (x + x*y)*2
f.backward()
x.grad # == 2*(x + x*y)*(1 + y) = 8.0PyTorch attaches grad_fn to results, constructs the graph dynamically during forward, and supports GPU execution via .cuda(). These conveniences, together with autodiff, enable fast deep learning experimentation.
Practical Optimisation Notes
Timing Guidance (for 2 hours)
15 min recap; 30 min depth/width and representation; 25 min generalisation phenomena; 30 min autodiff/backprop with small live demos; 15 min practical optimisation; 5 min Q&A.
Further Reading
Example: calculating a Hessian
\[ H(\mathbb{w}) = \frac{\partial^2}{\partial\mathbf{w}\partial\mathbf{w}^\top} L(\mathbf{w}) := \frac{\partial}{\partial\mathbf{w}} \mathbf{g}(\mathbf{w}) \]
Efficient strategy: compute \(\mathbf{g}(\mathbf{w})\) with reverse-mode, then apply forward-mode to obtain Hessian columns or HVPs (reverse-over-forward). Framework helpers: JAX jax.jacfwd(jax.jacrev(f)), PyTorch autograd.functional.hessian (memory heavy for large models).
Example: Hessian-vector product
\[ \mathbf{v}^\top H(\mathbf{w}) = \frac{\partial}{\partial\mathbf{w}} \left( \mathbf{v}^\top \mathbf{g}(\mathbf{w}) \right) \]
Live-coding HVP in PyTorch (mixed-mode via backward-over-backward or autograd.functional). Using a quadratic ensures a non-zero Hessian (2I):
import torch as th
def f(w):
return (w**2).sum() # toy scalar loss; Hessian = 2I
w = th.randn(5, requires_grad=True)
g, = th.autograd.grad(f(w), w, create_graph=True) # gradient with graph
v = th.randn_like(w)
hv, = th.autograd.grad(g, w, grad_outputs=v) # Hessian-vector product = 2*v
hvLearning Objectives
Agenda
David Hogg’s lecture https://speakerdeck.com/dwhgg/linear-regression-with-huge-numbers-of-parameters
The Deep Bootstrap https://twitter.com/PreetumNakkiran/status/1318007088321335297?s=20
Aki Vehtari on Leave One Out Uncertainty: https://arxiv.org/abs/2008.10296 (check for his references).
{ ## Approximation
Basic Multilayer Perceptron
\[\begin{align} f_l(x) &= \phi(W_l f_{l-1}(x) + b_l)\\ f_0(x) &= x \end{align}\]
Basic Multilayer Perceptron
\[ \small f_L(x) = \phi\left(b_L + W_L \phi\left(b_{L-1} + W_{L-1} \phi\left( \cdots \phi\left(b_1 + W_1 x\right) \cdots \right)\right)\right) \]
Rectified Linear Unit
\[ \phi(x) = \left\{\matrix{0&\text{when }x\leq 0\\x&\text{when }x>0}\right. \]

What can these networks represent?
\[ \operatorname{ReLU}(\mathbf{w}_1x - \mathbf{b}_1) \]

What can these networks represent?
\[ f(x) = \mathbf{w}^T_2 \operatorname{ReLU}(\mathbf{w}_1x - \mathbf{b}_1) \]

Single hidden layer
number of kinks \(\approx O(\) width of network \()\)
Example: “sawtooth” network
\[\begin{align} f_l(x) &= 2\vert f_{l-1}(x)\vert - 2 \\ f_0(x) &= x \end{align}\]
Sawtooth network
\[\begin{align} f_l(x) &= 2 \operatorname{ReLU}(f_{l-1}(x)) + 2 \operatorname{ReLU}(-f_{l-1}(x)) - 2\\ f_0(x) &= x \end{align}\]
\(0\)-layer network

\(1\)-layer network

\(2\)-layer network

\(3\)-layer network

\(4\)-layer network

\(5\)-layer network

Deep ReLU networks
number of kinks \(\approx O(2^\text{depth of network})\)
In higher dimensions

In higher dimensions

Approximation: summary
- depth increases model complexity more than width
- model clas defined by deep networks is VERY LARGE
- both an advantage, but and cause for concern
- “complex models don’t generalize”
Generalization
Generalization

Generalization

Generalization

Generalization: deep nets

Generalization: deep nets

Generalization: summary
- classical view: generalization is property of model class and loss function
- new view: it is also a property of the optimization algorithm
Generalization
- optimization is core to deep learning
- new tools and insights:
- infinite width neural networks
- neural tangent kernel (Jacot et al, 2018)
- deep linear models (e.g. Arora et al, 2019)
- importance of initialization
- effect of gradient noise
Further Reading
- Chapter 8 of Bishop-deeplearning24
Thanks!
For more information on these subjects and more you might want to check the following resources.
- company: Trent AI
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com
References
Apart from the last layer of parmeters in models with quadratic loss functions.↩︎
Assuming we are ignoring parameters in the link function and the distribution function.↩︎
Using the test data in your training procedure is a major error in any machine learning procedure. It is extremely dangerous as it gives a misleading assessment of the model performance. The Baidu ImageNet scandal was an example of a team competing in the ImageNet challenge which did this. The team had announced via the publication pre-print server Arxiv that they had a world-leading performance on the ImageNet challenge. This was reported in the mainstream media. Two weeks later the challenge organizers revealed that the team had created multiple accounts for checking their test performance more times than was permitted by the challenge rules. This was then reported as “AI’s first doping scandal.” The team lead was fired by Baidu.↩︎