

Week 1: Probability and an Introduction to Jupyter, Python and Pandas
[Powerpoint][jupyter][google colab][reveal]
Abstract:
In this first session we will introduce machine learning, review probability and begin familiarization with the Jupyter notebook, python and pandas.
Course Texts
A First Course in Machine Learning


Figure: The main course text is “A First Course in Machine Learning” by Rogers and Girolami (2011).
Pattern Recognition and Machine Learning

Figure: For additional reading we will regularly refer to “Pattern Recognition and Machine Learning” by Bishop (2006)
Welcome to the Machine Learning and Adaptive Intelligence course. In this course we will introduce the basic concepts of machine learning and data science. In particular we will look at tools and techniques that describe how to model. An integrated part of that is how we approach data with the computer. We are choosing to do that with the tool you see in front of you: the Jupyter Notebook.
The notebook provides us with a way of interacting with the data that allows us to give the computer instructions and explore the nature of a data set. It is different to normal coding, but it is related. In this course you will, through intensive practical sessions and labs, develop your understanding of the interaction between data and computers. The first thing we are going to do is ask you to forget a bit about what you think about normal programming, or ‘classical software engineering’. Classical software engineering demands a large amount of design and testing. In data analysis, testing remains very important, but the design is often evolving. The design evolves through a process known as exploratory data analysis. You will learn some of the techniques of exploratory data analysis in this course.
A particular difference between classical software engineering and data analysis is the way in which programs are run. Classically we spend a deal of time working with a text editor, writing code. Compilations are done on a regular basis and aspects of the code are tested (perhaps with unit tests).
Data analysis is more like coding in a debugger. In a debugger (particularly a visual debugger) you interact with the data stored in the memory of the computer to try and understand what is happening in the computer, you need to understand exactly what your bug is: you often have a fixed idea of what the program is trying to do, you are just struggling to find out why it isn’t doing it.
Naturally, debugging is an important part of data analysis also, but in some sense it can be seen as its entire premise. You load in a data set into a computer that you don’t understand, your entire objective is to understand the data. This is best done by interogating the data to visualise it or summarize it, just like in a power visual debugger. However, for data science the requirements for visualization and summarization are far greater than in a regular program. When the data is well understood, the actual number of lines of your program may well be very few (particularly if you disregard commands that load in the data and commands which plot your results). If a powerful data science library is available, you may be able to summarize your code with just two or three lines, but the amount of intellectual energy that is expended on writing those three lines is far greater than in standard code.
Assumed Knowledge
Linear Algebra, Probability and Differential Calculus
We will be assuming that you have good background in maths. In particular we will be making use of linear algrebra (matrix operations including inverse, inner products, determinant etc), probability (sum rule of probability, product rule of probability), and the calculus of variation, e.g. differentiation and integration. A new concept for the course is multivariate differentiation and integration. This combines linear algebra and differential calculus. These techniques are vital in understanding probability distributions over high dimensional distributions.
Choice of Language
In this course we will be using Python for our programming language. A prerequisite of attending this course is that you have learnt at least one programming language in the past. It is not our objective to teach you python. At Level 4 and Masters we expect our students to be able pick up a language as they go. If you have not experienced python before it may be worth your while spending some time understanding the language. There are resources available for you to do this here that are based on the standard console. An introduction to the Jupyter notebook (formerly known as the IPython notebook) is available here.
Exercise 1
Who invented python and why? What was the language designed to do? What is the origin of the name “python”? Is the language a compiled language? Is it an object orientated language?
Choice of Environment
We are working in the Jupyter notebook (formerly known as the IPython notebook). It provides an environment for interacting with data in a natural way which is reproducible. We will be learning how to make use of the notebook throughout the course. The notebook allows us to combine code with descriptions, interactive visualizations, plots etc. In fact it allows us to do many of the things we need for data science. Notebooks can also be easily shared through the internet for ease of communication of ideas. The box this text is written in is a markdown box. Below we have a code box.
print("This is the Jupyter notebook")
print("It provides a platform for:")
words = ['Open', 'Data', 'Science']
from random import shuffle
for i in range(3):
shuffle(words)
print(' '.join(words))Have a play with the code in the above box. Think about the following
questions: what is the difference between CTRL-enter and
SHIFT-enter in running the code? What does the command
shuffle do? Can you find out by typing
shuffle? in a code box? Once you’ve had a play with the
code we can load in some data using the pandas library for
data analysis.
Exercise 2
What is jupyter and why was it invented? Give some examples of functionality it gives over standard python. What is the jupyter project? Name two languages involved in the Jupyter project other than python.
Setup
notutils
This small package is a helper package for various notebook utilities used below.
The software can be installed using
%pip install notutilsfrom the command prompt where you can access your python installation.
The code is also available on GitHub: https://github.com/lawrennd/notutils
Once notutils is installed, it can be imported in the
usual manner.
import notutilspods
In Sheffield we created a suite of software tools for ‘Open Data Science’. Open data science is an approach to sharing code, models and data that should make it easier for companies, health professionals and scientists to gain access to data science techniques.
You can also check this blog post on Open Data Science.
The software can be installed using
%pip install podsfrom the command prompt where you can access your python installation.
The code is also available on GitHub: https://github.com/lawrennd/ods
Once pods is installed, it can be imported in the usual
manner.
import podsmlai
The mlai software is a suite of helper functions for
teaching and demonstrating machine learning algorithms. It was first
used in the Machine Learning and Adaptive Intelligence course in
Sheffield in 2013.
The software can be installed using
%pip install mlaifrom the command prompt where you can access your python installation.
The code is also available on GitHub: https://github.com/lawrennd/mlai
Once mlai is installed, it can be imported in the usual
manner.
import mlaiWhat is Machine Learning?
What is machine learning? At its most basic level machine learning is a combination of
\[\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} \text{prediction}\]
where data is our observations. They can be actively or passively acquired (meta-data). The model contains our assumptions, based on previous experience. That experience can be other data, it can come from transfer learning, or it can merely be our beliefs about the regularities of the universe. In humans our models include our inductive biases. The prediction is an action to be taken or a categorization or a quality score. The reason that machine learning has become a mainstay of artificial intelligence is the importance of predictions in artificial intelligence. The data and the model are combined through computation.
In practice we normally perform machine learning using two functions. To combine data with a model we typically make use of:
a prediction function it is used to make the predictions. It includes our beliefs about the regularities of the universe, our assumptions about how the world works, e.g., smoothness, spatial similarities, temporal similarities.
an objective function it defines the ‘cost’ of misprediction. Typically, it includes knowledge about the world’s generating processes (probabilistic objectives) or the costs we pay for mispredictions (empirical risk minimization).
The combination of data and model through the prediction function and the objective function leads to a learning algorithm. The class of prediction functions and objective functions we can make use of is restricted by the algorithms they lead to. If the prediction function or the objective function are too complex, then it can be difficult to find an appropriate learning algorithm. Much of the academic field of machine learning is the quest for new learning algorithms that allow us to bring different types of models and data together.
A useful reference for state of the art in machine learning is the UK Royal Society Report, Machine Learning: Power and Promise of Computers that Learn by Example.
You can also check my post blog post on What is Machine Learning?.
Overdetermined System
The challenge with a linear model is that it has two unknowns, \(m\), and \(c\). Observing data allows us to write down a system of simultaneous linear equations. So, for example if we observe two data points, the first with the input value, \(x_1 = 1\) and the output value, \(y_1 =3\) and a second data point, \(x= 3\), \(y=1\), then we can write two simultaneous linear equations of the form.
point 1: \(x= 1\), \(y=3\) \[ 3 = m + c \] point 2: \(x= 3\), \(y=1\) \[ 1 = 3m + c \]
The solution to these two simultaneous equations can be represented graphically as
Figure: The solution of two linear equations represented as the fit of a straight line through two data
The challenge comes when a third data point is observed, and it doesn’t fit on the straight line.
point 3: \(x= 2\), \(y=2.5\) \[ 2.5 = 2m + c \]
Figure: A third observation of data is inconsistent with the solution dictated by the first two observations
Now there are three candidate lines, each consistent with our data.
Figure: Three solutions to the problem, each consistent with two points of the three observations
This is known as an overdetermined system because there are more data than we need to determine our parameters. The problem arises because the model is a simplification of the real world, and the data we observe is therefore inconsistent with our model.
Pierre-Simon Laplace
The solution was proposed by Pierre-Simon Laplace. His idea was to accept that the model was an incomplete representation of the real world, and the way it was incomplete is unknown. His idea was that such unknowns could be dealt with through probability.
Pierre-Simon Laplace

Figure: Pierre-Simon Laplace 1749-1827.
Famously, Laplace considered the idea of a deterministic Universe, one in which the model is known, or as the below translation refers to it, “an intelligence which could comprehend all the forces by which nature is animated”. He speculates on an “intelligence” that can submit this vast data to analysis and propsoses that such an entity would be able to predict the future.
Given for one instant an intelligence which could comprehend all the forces by which nature is animated and the respective situation of the beings who compose it—an intelligence sufficiently vast to submit these data to analysis—it would embrace in the same formulate the movements of the greatest bodies of the universe and those of the lightest atom; for it, nothing would be uncertain and the future, as the past, would be present in its eyes.
This notion is known as Laplace’s demon or Laplace’s superman.

Figure: Laplace’s determinsim in English translation.
Laplace’s Gremlin
Unfortunately, most analyses of his ideas stop at that point, whereas his real point is that such a notion is unreachable. Not so much superman as strawman. Just three pages later in the “Philosophical Essay on Probabilities” (Laplace:essai14?), Laplace goes on to observe:
The curve described by a simple molecule of air or vapor is regulated in a manner just as certain as the planetary orbits; the only difference between them is that which comes from our ignorance.
Probability is relative, in part to this ignorance, in part to our knowledge.

Figure: To Laplace, determinism is a strawman. Ignorance of mechanism and data leads to uncertainty which should be dealt with through probability.
In other words, we can never make use of the idealistic deterministic Universe due to our ignorance about the world, Laplace’s suggestion, and focus in this essay is that we turn to probability to deal with this uncertainty. This is also our inspiration for using probability in machine learning. This is the true message of Laplace’s essay, not determinism, but the gremlin of uncertainty that emerges from our ignorance.
The “forces by which nature is animated” is our model, the “situation of beings that compose it” is our data and the “intelligence sufficiently vast enough to submit these data to analysis” is our compute. The fly in the ointment is our ignorance about these aspects. And probability is the tool we use to incorporate this ignorance leading to uncertainty or doubt in our predictions.
Latent Variables
Laplace’s concept was that the reason that the data doesn’t match up to the model is because of unconsidered factors, and that these might be well represented through probability densities. He tackles the challenge of the unknown factors by adding a variable, \(\epsilon\), that represents the unknown. In modern parlance we would call this a latent variable. But in the context Laplace uses it, the variable is so common that it has other names such as a “slack” variable or the noise in the system.
point 1: \(x= 1\), \(y=3\) \[ 3 = m + c + \epsilon_1 \] point 2: \(x= 3\), \(y=1\) \[ 1 = 3m + c + \epsilon_2 \] point 3: \(x= 2\), \(y=2.5\) \[ 2.5 = 2m + c + \epsilon_3 \]
Laplace’s trick has converted the overdetermined system into an underdetermined system. He has now added three variables, \(\{\epsilon_i\}_{i=1}^3\), which represent the unknown corruptions of the real world. Laplace’s idea is that we should represent that unknown corruption with a probability distribution.
A Probabilistic Process
However, it was left to an admirer of Laplace to develop a practical probability density for that purpose. It was Carl Friedrich Gauss who suggested that the Gaussian density (which at the time was unnamed!) should be used to represent this error.
The result is a noisy function, a function which has a deterministic part, and a stochastic part. This type of function is sometimes known as a probabilistic or stochastic process, to distinguish it from a deterministic process.
Nigeria NMIS Data
As an example data set we will use Nigerian Millennium Development Goals Information System Health Facility (The Office of the Senior Special Assistant to the President on the Millennium Development Goals (OSSAP-MDGs) and Columbia University, 2014). It can be found here https://energydata.info/dataset/nigeria-nmis-education-facility-data-2014.
Taking from the information on the site,
The Nigeria MDG (Millennium Development Goals) Information System – NMIS health facility data is collected by the Office of the Senior Special Assistant to the President on the Millennium Development Goals (OSSAP-MDGs) in partner with the Sustainable Engineering Lab at Columbia University. A rigorous, geo-referenced baseline facility inventory across Nigeria is created spanning from 2009 to 2011 with an additional survey effort to increase coverage in 2014, to build Nigeria’s first nation-wide inventory of health facility. The database includes 34,139 health facilities info in Nigeria.
The goal of this database is to make the data collected available to planners, government officials, and the public, to be used to make strategic decisions for planning relevant interventions.
For data inquiry, please contact Ms. Funlola Osinupebi, Performance Monitoring & Communications, Advisory Power Team, Office of the Vice President at funlola.osinupebi@aptovp.org
To learn more, please visit http://csd.columbia.edu/2014/03/10/the-nigeria-mdg-information-system-nmis-takes-open-data-further/
Suggested citation: Nigeria NMIS facility database (2014), the Office of the Senior Special Assistant to the President on the Millennium Development Goals (OSSAP-MDGs) & Columbia University
For ease of use we’ve packaged this data set in the pods
library
data = pods.datasets.nigeria_nmis()['Y']
data.head()Alternatively, you can access the data directly with the following commands.
import urllib.request
urllib.request.urlretrieve('https://energydata.info/dataset/f85d1796-e7f2-4630-be84-79420174e3bd/resource/6e640a13-cab4-457b-b9e6-0336051bac27/download/healthmopupandbaselinenmisfacility.csv', 'healthmopupandbaselinenmisfacility.csv')
import pandas as pd
data = pd.read_csv('healthmopupandbaselinenmisfacility.csv')Once it is loaded in the data can be summarized using the
describe method in pandas.
data.describe()We can also find out the dimensions of the dataset using the
shape property.
data.shapeDataframes have different functions that you can use to explore and
understand your data. In python and the Jupyter notebook it is possible
to see a list of all possible functions and attributes by typing the
name of the object followed by .<Tab> for example in
the above case if we type data.<Tab> it show the
columns available (these are attributes in pandas dataframes) such as
num_nurses_fulltime, and also functions, such as
.describe().
For functions we can also see the documentation about the function by following the name with a question mark. This will open a box with documentation at the bottom which can be closed with the x button.
data.describe?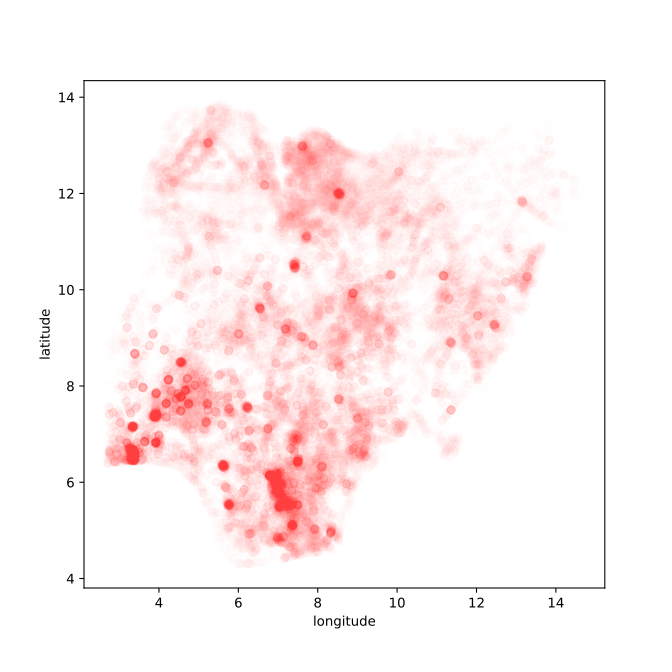
Figure: Location of the over thirty-four thousand health facilities registered in the NMIS data across Nigeria. Each facility plotted according to its latitude and longitude.
Probabilities
We are now going to do some simple review of probabilities and use this review to explore some aspects of our data.
A probability distribution expresses uncertainty about the outcome of an event. We often encode this uncertainty in a variable. So if we are considering the outcome of an event, \(Y\), to be a coin toss, then we might consider \(Y=1\) to be heads and \(Y=0\) to be tails. We represent the probability of a given outcome with the notation: \[ P(Y=1) = 0.5 \] The first rule of probability is that the probability must normalize. The sum of the probability of all events must equal 1. So if the probability of heads (\(Y=1\)) is 0.5, then the probability of tails (the only other possible outcome) is given by \[ P(Y=0) = 1-P(Y=1) = 0.5 \]
Probabilities are often defined as the limit of the ratio between the number of positive outcomes (e.g. heads) given the number of trials. If the number of positive outcomes for event \(y\) is denoted by \(n\) and the number of trials is denoted by \(N\) then this gives the ratio \[ P(Y=y) = \lim_{N\rightarrow \infty}\frac{n_y}{N}. \] In practice we never get to observe an event infinite times, so rather than considering this we often use the following estimate \[ P(Y=y) \approx \frac{n_y}{N}. \]
Exploring the NMIS Data
The NMIS facility data is stored in an object known as a ‘data
frame’. Data frames come from the statistical family of programming
languages based on S, the most widely used of which is R.
The data frame gives us a convenient object for manipulating data. The
describe method summarizes which columns there are in the data frame and
gives us counts, means, standard deviations and percentiles for the
values in those columns. To access a column directly we can write
print(data['num_doctors_fulltime'])
#print(data['num_nurses_fulltime'])This shows the number of doctors per facility, number of nurses and number of community health workers (CHEWS). We can plot the number of doctors against the number of nurses as follows.
import matplotlib.pyplot as plt # this imports the plotting library in python_ = plt.plot(data['num_doctors_fulltime'], data['num_nurses_fulltime'], 'rx')You may be curious what the arguments we give to
plt.plot are for, now is the perfect time to look at the
documentation
plt.plot?We immediately note that some facilities have a lot of nurses, which prevent’s us seeing the detail of the main number of facilities. First lets identify the facilities with the most nurses.
data[data['num_nurses_fulltime']>100]Here we are using the command
data['num_nurses_fulltime']>100 to index the facilities
in the pandas data frame which have over 100 nurses. To sort them in
order we can also use the sort command. The result of this
command on its own is a data Series of True
and False values. However, when it is passed to the
data data frame it returns a new data frame which contains
only those values for which the data series is True. We can
also sort the result. To sort the result by the values in the
num_nurses_fulltime column in descending order we
use the following command.
data[data['num_nurses_fulltime']>100].sort_values(by='num_nurses_fulltime', ascending=False)We now see that the ‘University of Calabar Teaching Hospital’ is a large outlier with 513 nurses. We can try and determine how much of an outlier by histograming the data.
Plotting the Data
data['num_nurses_fulltime'].hist(bins=20) # histogram the data with 20 bins.
plt.title('Histogram of Number of Nurses')We can’t see very much here. Two things are happening. There are so many facilities with zero or one nurse that we don’t see the histogram for hospitals with many nurses. We can try more bins and using a log scale on the \(y\)-axis.
data['num_nurses_fulltime'].hist(bins=100) # histogram the data with 20 bins.
plt.title('Histogram of Number of Nurses')
ax = plt.gca()
ax.set_yscale('log')Let’s try and see how the number of nurses relates to the number of doctors.
fig, ax = plt.subplots(figsize=(10, 7))
ax.plot(data['num_doctors_fulltime'], data['num_nurses_fulltime'], 'rx')
ax.set_xscale('log') # use a logarithmic x scale
ax.set_yscale('log') # use a logarithmic Y scale
# give the plot some titles and labels
plt.title('Number of Nurses against Number of Doctors')
plt.ylabel('number of nurses')
plt.xlabel('number of doctors')Note a few things. We are interacting with our data. In particular, we are replotting the data according to what we have learned so far. We are using the progamming language as a scripting language to give the computer one command or another, and then the next command we enter is dependent on the result of the previous. This is a very different paradigm to classical software engineering. In classical software engineering we normally write many lines of code (entire object classes or functions) before compiling the code and running it. Our approach is more similar to the approach we take whilst debugging. Historically, researchers interacted with data using a console. A command line window which allowed command entry. The notebook format we are using is slightly different. Each of the code entry boxes acts like a separate console window. We can move up and down the notebook and run each part in a different order. The state of the program is always as we left it after running the previous part.
Probability and the NMIS Data
Let’s use the sum rule to compute the estimate the probability that a facility has more than two nurses.
large = (data.num_nurses_fulltime>2).sum() # number of positive outcomes (in sum True counts as 1, False counts as 0)
total_facilities = data.num_nurses_fulltime.count()
prob_large = float(large)/float(total_facilities)
print("Probability of number of nurses being greather than 2 is:", prob_large)Conditioning
When predicting whether a coin turns up head or tails, we might think that this event is independent of the year or time of day. If we include an observation such as time, then in a probability this is known as condtioning. We use this notation, \(P(Y=y|X=x)\), to condition the outcome on a second variable (in this case the number of doctors). Or, often, for a shorthand we use \(P(y|x)\) to represent this distribution (the \(Y=\) and \(X=\) being implicit). If two variables are independent then we find that \[ P(y|x) = p(y). \] However, we might believe that the number of nurses is dependent on the number of doctors. For this we can try estimating \(P(Y>2 | X>1)\) and compare the result, for example to \(P(Y>2|X\leq 1)\) using our empirical estimate of the probability.
large = ((data.num_nurses_fulltime>2) & (data.num_doctors_fulltime>1)).sum()
total_large_doctors = (data.num_doctors_fulltime>1).sum()
prob_both_large = large/total_large_doctors
print("Probability of number of nurses being greater than 2 given number of doctors is greater than 1 is:", prob_both_large)Exercise 3
Write code that prints out the probability of nurses being greater than 2 for different numbers of doctors.
Make sure the plot is included in this notebook file (the
Jupyter magic command %matplotlib inline we ran above will
do that for you, it only needs to be run once per file).
| Terminology | Mathematical notation | Description |
|---|---|---|
| joint | \(P(X=x, Y=y)\) | prob. that X=x and Y=y |
| marginal | \(P(X=x)\) | prob. that X=x regardless of Y |
| conditional | \(P(X=x\vert Y=y)\) | prob. that X=x given that Y=y |
A Pictorial Definition of Probability
Figure: Diagram representing the different probabilities, joint, marginal and conditional. This diagram was inspired by lectures given by Christopher Bishop.
Definition of probability distributions
| Terminology | Definition | Probability Notation |
|---|---|---|
| Joint Probability | \(\lim_{N\rightarrow\infty}\frac{n_{X=3,Y=4}}{N}\) | \(P\left(X=3,Y=4\right)\) |
| Marginal Probability | \(\lim_{N\rightarrow\infty}\frac{n_{X=5}}{N}\) | \(P\left(X=5\right)\) |
| Conditional Probability | \(\lim_{N\rightarrow\infty}\frac{n_{X=3,Y=4}}{n_{Y=4}}\) | \(P\left(X=3\vert Y=4\right)\) |
Notational Details
Typically we should write out \(P\left(X=x,Y=y\right)\), but in practice we often shorten this to \(P\left(x,y\right)\). This looks very much like we might write a multivariate function, e.g. \[ f\left(x,y\right)=\frac{x}{y}, \] but for a multivariate function \[ f\left(x,y\right)\neq f\left(y,x\right). \] However, \[ P\left(x,y\right)=P\left(y,x\right) \] because \[ P\left(X=x,Y=y\right)=P\left(Y=y,X=x\right). \] Sometimes I think of this as akin to the way in Python we can write ‘keyword arguments’ in functions. If we use keyword arguments, the ordering of arguments doesn’t matter.
We’ve now introduced conditioning and independence to the notion of probability and computed some conditional probabilities on a practical example The scatter plot of deaths vs year that we created above can be seen as a joint probability distribution. We represent a joint probability using the notation \(P(Y=y, X=x)\) or \(P(y, x)\) for short. Computing a joint probability is equivalent to answering the simultaneous questions, what’s the probability that the number of nurses was over 2 and the number of doctors was 1? Or any other question that may occur to us. Again we can easily use pandas to ask such questions.
num_doctors = 1
large = (data.num_nurses_fulltime[data.num_doctors_fulltime==num_doctors]>2).sum()
total_facilities = data.num_nurses_fulltime.count() # this is total number of films
prob_large = float(large)/float(total_facilities)
print("Probability of nurses being greater than 2 and number of doctors being", num_doctors, "is:", prob_large)The Product Rule
This number is the joint probability, \(P(Y, X)\) which is much smaller than the conditional probability. The number can never be bigger than the conditional probabililty because it is computed using the product rule. \[ p(Y=y, X=x) = p(Y=y|X=x)p(X=x) \] and \[p(X=x)\] is a probability distribution, which is equal or less than 1, ensuring the joint distribution is typically smaller than the conditional distribution.
The product rule is a fundamental rule of probability, and you must remember it! It gives the relationship between the two questions: 1) What’s the probability that a facility has over two nurses and one doctor? and 2) What’s the probability that a facility has over two nurses given that it has one doctor?
In our shorter notation we can write the product rule as \[ p(y, x) = p(y|x)p(x) \] We can see the relation working in practice for our data above by computing the different values for \(x=1\).
num_doctors=1
num_nurses=2
p_x = float((data.num_doctors_fulltime==num_doctors).sum())/float(data.num_doctors_fulltime.count())
p_y_given_x = float((data.num_nurses_fulltime[data.num_doctors_fulltime==num_doctors]>num_nurses).sum())/float((data.num_doctors_fulltime==num_doctors).sum())
p_y_and_x = float((data.num_nurses_fulltime[data.num_doctors_fulltime==num_doctors]>num_nurses).sum())/float(data.num_nurses_fulltime.count())
print("P(x) is", p_x)
print("P(y|x) is", p_y_given_x)
print("P(y,x) is", p_y_and_x)The Sum Rule
The other fundamental rule of probability is the sum rule this tells us how to get a marginal distribution from the joint distribution. Simply put it says that we need to sum across the value we’d like to remove. \[ P(Y=y) = \sum_{x} P(Y=y, X=x) \] Or in our shortened notation \[ P(y) = \sum_{x} P(y, x) \]
Exercise 4
Write code that computes \(P(y)\) by adding \(P(y, x)\) for all values of \(x\).
Bayes’ Rule
Bayes’ rule is a very simple rule, it’s hardly worth the name of a rule at all. It follows directly from the product rule of probability. Because \(P(y, x) = P(y|x)P(x)\) and by symmetry \(P(y,x)=P(x,y)=P(x|y)P(y)\) then by equating these two equations and dividing through by \(P(y)\) we have \[ P(x|y) = \frac{P(y|x)P(x)}{P(y)} \] which is known as Bayes’ rule (or Bayes’s rule, it depends how you choose to pronounce it). It’s not difficult to derive, and its importance is more to do with the semantic operation that it enables. Each of these probability distributions represents the answer to a question we have about the world. Bayes rule (via the product rule) tells us how to invert the probability.
Further Reading
- Probability distributions: page 12–17 (Section 1.2) of Bishop (2006)
Exercises
- Exercise 1.3 of Bishop (2006)
Probabilities for Extracting Information from Data
What use is all this probability in data science? Let’s think about how we might use the probabilities to do some decision making. Let’s look at the information data.
data.columnsExercise 5
Now we see we have several additional features. Let’s assume we want
to predict maternal_health_delivery_services. How would we
go about doing it?
Using what you’ve learnt about joint, conditional and marginal probabilities, as well as the sum and product rule, how would you formulate the question you want to answer in terms of probabilities? Should you be using a joint or a conditional distribution? If it’s conditional, what should the distribution be over, and what should it be conditioned on?
Figure: MLAI Lecture 2 from 2012.
See probability review at end of slides for reminders.
For other material in Bishop read:
If you are unfamiliar with probabilities you should complete the following exercises:
Thanks!
For more information on these subjects and more you might want to check the following resources.
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com
Further Reading
Section 2.2 (pg 41–53) of Rogers and Girolami (2011)
Section 2.4 (pg 55–58) of Rogers and Girolami (2011)
Section 2.5.1 (pg 58–60) of Rogers and Girolami (2011)
Section 2.5.3 (pg 61–62) of Rogers and Girolami (2011)
Probability densities: Section 1.2.1 (Pages 17–19) of Bishop (2006)
Expectations and Covariances: Section 1.2.2 (Pages 19–20) of Bishop (2006)
The Gaussian density: Section 1.2.4 (Pages 24–28) (don’t worry about material on bias) of Bishop (2006)
For material on information theory and KL divergence try Section 1.6 & 1.6.1 (pg 48 onwards) of Bishop (2006)
Exercises
Exercise 1.7 of Bishop (2006)
Exercise 1.8 of Bishop (2006)
Exercise 1.9 of Bishop (2006)