

%pip install gpyGPy: A Gaussian Process Framework in Python
Gaussian processes are a flexible tool for non-parametric analysis with uncertainty. The GPy software was started in Sheffield to provide a easy to use interface to GPs. One which allowed the user to focus on the modelling rather than the mathematics.

Figure: GPy is a BSD licensed software code base for implementing Gaussian process models in Python. It is designed for teaching and modelling. We welcome contributions which can be made through the GitHub repository https://github.com/SheffieldML/GPy
GPy is a BSD licensed software code base for implementing Gaussian process models in python. This allows GPs to be combined with a wide variety of software libraries.
The software itself is available on GitHub and the team welcomes contributions.
The aim for GPy is to be a probabilistic-style programming language, i.e., you specify the model rather than the algorithm. As well as a large range of covariance functions the software allows for non-Gaussian likelihoods, multivariate outputs, dimensionality reduction and approximations for larger data sets.
The documentation for GPy can be found here.

Figure: In recent years, approximations for Gaussian process models haven’t been the most fashionable approach to machine learning. Image credit: Kai Arulkumaran
Inference in a Gaussian process has computational complexity of \(\mathcal{O}(n^3)\) and storage demands of \(\mathcal{O}(n^2)\). This is too large for many modern data sets.
Low rank approximations allow us to work with Gaussian processes with computational complexity of \(\mathcal{O}(nm^2)\) and storage demands of \(\mathcal{O}(nm)\), where \(m\) is a user chosen parameter.
In machine learning, low rank approximations date back to Smola and Bartlett (n.d.), Williams and Seeger (n.d.), who considered the Nyström approximation and Csató and Opper (2002);Csató (2002) who considered low rank approximations in the context of on-line learning. Selection of active points for the approximation was considered by Seeger et al. (n.d.) and Snelson and Ghahramani (n.d.) first proposed that the active set could be optimized directly. Those approaches were reviewed by Quiñonero Candela and Rasmussen (2005) under a unifying likelihood approximation perspective. General rules for deriving the maximum likelihood for these sparse approximations were given in Lawrence (n.d.).
Modern variational interpretations of these low rank approaches were first explored in Titsias (n.d.). A more modern summary which considers each of these approximations as an \(\alpha\)-divergence is given by Bui et al. (2017).
Variational Compression
Inducing variables are a compression of the real observations. The basic idea is can I create a new data set that summarizes all the information in the original data set. If this data set is smaller, I’ve compressed the information in the original data set.
Inducing variables can be thought of as pseudo-data, indeed in Snelson and Ghahramani (n.d.) they were referred to as pseudo-points.
The only requirement for inducing variables is that they are jointly distributed as a Gaussian process with the original data. This means that they can be from the space \(\mathbf{ f}\) or a space that is related through a linear operator (see e.g. Álvarez et al. (2010)). For example we could choose to store the gradient of the function at particular points or a value from the frequency spectrum of the function (Lázaro-Gredilla et al., 2010).
Variational Compression II
Inducing variables don’t only allow for the compression of the non-parameteric information into a reduced data aset but they also allow for computational scaling of the algorithms through, for example stochastic variational approaches Hensman et al. (n.d.) or parallelization Gal et al. (n.d.),Dai et al. (2014), Seeger et al. (2017).
We’ve seen how we go from parametric to non-parametric. The limit implies infinite dimensional \(\mathbf{ w}\). Gaussian processes are generally non-parametric: combine data with covariance function to get model. This representation cannot be summarized by a parameter vector of a fixed size.
Parametric models have a representation that does not respond to increasing training set size. Bayesian posterior distributions over parameters contain the information about the training data, for example if we use use Bayes’ rule from training data, \[ p\left(\mathbf{ w}|\mathbf{ y}, \mathbf{X}\right), \] to make predictions on test data \[ p\left(y_*|\mathbf{X}_*, \mathbf{ y}, \mathbf{X}\right) = \int p\left(y_*|\mathbf{ w},\mathbf{X}_*\right)p\left(\mathbf{ w}|\mathbf{ y}, \mathbf{X})\text{d}\mathbf{ w}\right) \] then \(\mathbf{ w}\) becomes a bottleneck for information about the training set to pass to the test set. The solution is to increase \(m\) so that the bottleneck is so large that it no longer presents a problem. How big is big enough for \(m\)? Non-parametrics says \(m\rightarrow \infty\).
Now no longer possible to manipulate the model through the standard parametric form. However, it is possible to express parametric as GPs: \[ k\left(\mathbf{ x}_i,\mathbf{ x}_j\right)=\phi_:\left(\mathbf{ x}_i\right)^\top\phi_:\left(\mathbf{ x}_j\right). \] These are known as degenerate covariance matrices. Their rank is at most \(m\), non-parametric models have full rank covariance matrices. Most well known is the “linear kernel”, \[ k(\mathbf{ x}_i, \mathbf{ x}_j) = \mathbf{ x}_i^\top\mathbf{ x}_j. \] For non-parametrics prediction at a new point, \(\mathbf{ f}_*\), is made by conditioning on \(\mathbf{ f}\) in the joint distribution. In GPs this involves combining the training data with the covariance function and the mean function. Parametric is a special case when conditional prediction can be summarized in a fixed number of parameters. Complexity of parametric model remains fixed regardless of the size of our training data set. For a non-parametric model the required number of parameters grows with the size of the training data.
- Everything we want to do with a GP involves marginalising \(\mathbf{ f}\)
- Predictions
- Marginal likelihood
- Estimating covariance parameters
- The posterior of \(\mathbf{ f}\) is the central object. This means inverting \(\mathbf{K}_{\mathbf{ f}\mathbf{ f}}\).

The Nystr"om approximation takes the form, \[ \mathbf{K}_{\mathbf{ f}\mathbf{ f}}\approx \mathbf{Q}_{\mathbf{ f}\mathbf{ f}}= \mathbf{K}_{\mathbf{ f}\mathbf{ u}}\mathbf{K}_{\mathbf{ u}\mathbf{ u}}^{-1}\mathbf{K}_{\mathbf{ u}\mathbf{ f}} \] The idea is that instead of inverting \(\mathbf{K}_{\mathbf{ f}\mathbf{ f}}\), we make a low rank (or Nyström) approximation, and invert \(\mathbf{K}_{\mathbf{ u}\mathbf{ u}}\) instead.
In the original Nystr"om method the columns to incorporate are sampled from the complete set of columns (without replacement). In a kernel matrix each of these columns corresponds to a data point. In the Nystr"om method these points are sometimes called landmark points.
| \[\mathbf{X},\,\mathbf{ y}\] |
|
| \[\mathbf{X},\,\mathbf{ y}\] \[{\color{blue} f(\mathbf{ x})} \sim {\mathcal GP}\] |
|
| \[\mathbf{X},\,\mathbf{ y}\] \[f(\mathbf{ x}) \sim {\mathcal GP}\]\[p({\color{blue} \mathbf{ f}}) = \mathcal{N}\left(\mathbf{0},\mathbf{K}_{\mathbf{ f}\mathbf{ f}}\right)\] |
|
| \[ \mathbf{X},\,\mathbf{ y}\] \[f(\mathbf{ x}) \sim {\mathcal GP} \] \[ p(\mathbf{ f}) = \mathcal{N}\left(\mathbf{0},\mathbf{K}_{\mathbf{ f}\mathbf{ f}}\right) \] \[p( \mathbf{ f}|\mathbf{ y},\mathbf{X}) \] |
|
Take an extra \(m\) points on the function, \(\mathbf{ u}= f(\mathbf{Z})\). \[p(\mathbf{ y},\mathbf{ f},\mathbf{ u}) = p(\mathbf{ y}|\mathbf{ f}) p(\mathbf{ f}|\mathbf{ u}) p(\mathbf{ u})\]

Take and extra \(M\) points on the function, \(\mathbf{ u}= f(\mathbf{Z})\). \[p(\mathbf{ y},\mathbf{ f},\mathbf{ u}) = p(\mathbf{ y}|\mathbf{ f}) p(\mathbf{ f}|\mathbf{ u}) p(\mathbf{ u})\] \[\begin{aligned} p(\mathbf{ y}|\mathbf{ f}) &= \mathcal{N}\left(\mathbf{ y}|\mathbf{ f},\sigma^2 \mathbf{I}\right)\\ p(\mathbf{ f}|\mathbf{ u}) &= \mathcal{N}\left(\mathbf{ f}| \mathbf{K}_{\mathbf{ f}\mathbf{ u}}\mathbf{K}_{\mathbf{ u}\mathbf{ u}}^{-1}\mathbf{ u}, \tilde{\mathbf{K}}\right)\\ p(\mathbf{ u}) &= \mathcal{N}\left(\mathbf{ u}| \mathbf{0},\mathbf{K}_{\mathbf{ u}\mathbf{ u}}\right) \end{aligned}\]
| \[\mathbf{X},\,\mathbf{ y}\] \[f(\mathbf{ x}) \sim {\mathcal GP}\] \[p(\mathbf{ f}) = \mathcal{N}\left(\mathbf{0},\mathbf{K}_{\mathbf{ f}\mathbf{ f}}\right)\] \[p(\mathbf{ f}|\mathbf{ y},\mathbf{X})\] |
|
\[ \begin{align} &\qquad\mathbf{Z}, \mathbf{ u}\\ &p({\color{red} \mathbf{ u}}) = \mathcal{N}\left(\mathbf{0},\mathbf{K}_{\mathbf{ u}\mathbf{ u}}\right)\end{align} \]
| \[\mathbf{X},\,\mathbf{ y}\] \[f(\mathbf{ x}) \sim {\mathcal GP}\] \[p(\mathbf{ f}) = \mathcal{N}\left(\mathbf{0},\mathbf{K}_{\mathbf{ f}\mathbf{ f}}\right)\] \[p(\mathbf{ f}|\mathbf{ y},\mathbf{X})\] \[p(\mathbf{ u}) = \mathcal{N}\left(\mathbf{0},\mathbf{K}_{\mathbf{ u}\mathbf{ u}}\right)\] \[\widetilde p({\color{red}\mathbf{ u}}|\mathbf{ y},\mathbf{X})\] |

|
Instead of doing \[ p(\mathbf{ f}|\mathbf{ y},\mathbf{X}) = \frac{p(\mathbf{ y}|\mathbf{ f})p(\mathbf{ f}|\mathbf{X})}{\int p(\mathbf{ y}|\mathbf{ f})p(\mathbf{ f}|\mathbf{X}){\text{d}\mathbf{ f}}} \] We’ll do \[ p(\mathbf{ u}|\mathbf{ y},\mathbf{Z}) = \frac{p(\mathbf{ y}|\mathbf{ u})p(\mathbf{ u}|\mathbf{Z})}{\int p(\mathbf{ y}|\mathbf{ u})p(\mathbf{ u}|\mathbf{Z}){\text{d}\mathbf{ u}}} \]
- Date back to {Williams and Seeger (n.d.); Smola and Bartlett (n.d.); Csató and Opper (2002); Seeger et al. (n.d.); Snelson and Ghahramani (n.d.)}. See {Quiñonero Candela and Rasmussen (2005); Bui et al. (2017)} for reviews.
- We follow variational perspective of {Titsias (n.d.)}.
- This is an augmented variable method, followed by a collapsed variational approximation {King and Lawrence (n.d.); Hensman et al. (2012)}.
Variational Bound on \(p(\mathbf{ y}|\mathbf{ u})\)
The conditional density of the data given the inducing points can be lower bounded variationally \[ \begin{aligned} \log p(\mathbf{ y}|\mathbf{ u}) & = \log \int p(\mathbf{ y}|\mathbf{ f}) p(\mathbf{ f}|\mathbf{ u}) \text{d}\mathbf{ f}\\ & = \int q(\mathbf{ f}) \log \frac{p(\mathbf{ y}|\mathbf{ f}) p(\mathbf{ f}|\mathbf{ u})}{q(\mathbf{ f})}\text{d}\mathbf{ f}+ \text{KL}\left( q(\mathbf{ f})\,\|\,p(\mathbf{ f}|\mathbf{ y}, \mathbf{ u}) \right). \end{aligned} \]
The key innovation from Titsias (n.d.) was to then make a particular choice for \(q(\mathbf{ f})\). If we set \(q(\mathbf{ f})=p(\mathbf{ f}|\mathbf{ u})\), \[ \log p(\mathbf{ y}|\mathbf{ u}) \geq \int p(\mathbf{ f}|\mathbf{ u}) \log p(\mathbf{ y}|\mathbf{ f})\text{d}\mathbf{ f}. \] \[ p(\mathbf{ y}|\mathbf{ u}) \geq \exp \int p(\mathbf{ f}|\mathbf{ u}) \log p(\mathbf{ y}|\mathbf{ f})\text{d}\mathbf{ f}. \]
Optimal Compression in Inducing Variables
Maximizing the lower bound minimizes the Kullback-Leibler divergence (or information gain) between our approximating density, \(p(\mathbf{ f}|\mathbf{ u})\) and the true posterior density, \(p(\mathbf{ f}|\mathbf{ y}, \mathbf{ u})\).
\[ \text{KL}\left( p(\mathbf{ f}|\mathbf{ u})\,\|\,p(\mathbf{ f}|\mathbf{ y}, \mathbf{ u}) \right) = \int p(\mathbf{ f}|\mathbf{ u}) \log \frac{p(\mathbf{ f}|\mathbf{ u})}{p(\mathbf{ f}|\mathbf{ y}, \mathbf{ u})}\text{d}\mathbf{ u} \]
This bound is minimized when the information stored about \(\mathbf{ y}\) is already stored in \(\mathbf{ u}\). In other words, maximizing the bound seeks an optimal compression from the information gain perspective.
For the case where \(\mathbf{ u}= \mathbf{ f}\) the bound is exact (\(\mathbf{ f}\) \(d\)-separates \(\mathbf{ y}\) from \(\mathbf{ u}\)).
Choice of Inducing Variables
The quality of the resulting bound is determined by the choice of the inducing variables. You are free to choose whichever heuristics you like for the inducing variables, as long as they are drawn jointly from a valid Gaussian process, i.e. such that \[ \begin{bmatrix} \mathbf{ f}\\ \mathbf{ u} \end{bmatrix} \sim \mathcal{N}\left(\mathbf{0},\mathbf{K}\right) \] where the kernel matrix itself can be decomposed into \[ \mathbf{K}= \begin{bmatrix} \mathbf{K}_{\mathbf{ f}\mathbf{ f}}& \mathbf{K}_{\mathbf{ f}\mathbf{ u}}\\ \mathbf{K}_{\mathbf{ u}\mathbf{ f}}& \mathbf{K}_{\mathbf{ u}\mathbf{ u}} \end{bmatrix} \] Choosing the inducing variables amounts to specifying \(\mathbf{K}_{\mathbf{ f}\mathbf{ u}}\) and \(\mathbf{K}_{\mathbf{ u}\mathbf{ u}}\) such that \(\mathbf{K}\) remains positive definite. The typical choice is to choose \(\mathbf{ u}\) in the same domain as \(\mathbf{ f}\), associating each inducing output, \(u_i\) with a corresponding input location \(\mathbf{ z}\). However, more imaginative choices are absolutely possible. In particular, if \(\mathbf{ u}\) is related to \(\mathbf{ f}\) through a linear operator (see e.g. Álvarez et al. (2010)), then valid \(\mathbf{K}_{\mathbf{ u}\mathbf{ u}}\) and \(\mathbf{K}_{\mathbf{ u}\mathbf{ f}}\) can be constructed. For example we could choose to store the gradient of the function at particular points or a value from the frequency spectrum of the function (Lázaro-Gredilla et al., 2010).
Variational Compression II
Inducing variables don’t only allow for the compression of the non-parameteric information into a reduced data set but they also allow for computational scaling of the algorithms through, for example stochastic variational approaches(Hensman et al., n.d.; Hoffman et al., 2012) or parallelization (Dai et al., 2014; Gal et al., n.d.; Seeger et al., 2017).
If the likelihood, \(p(\mathbf{ y}|\mathbf{ f})\), factorizes
<8-> Then the bound factorizes.
<10-> Now need a choice of distributions for \(\mathbf{ f}\) and \(\mathbf{ y}|\mathbf{ f}\) …
Choose to go a different way.
Introduce a set of auxiliary variables, \(\mathbf{ u}\), which are \(m\) in length.
They are like “artificial data”.
Used to induce a distribution: \(q(\mathbf{ u}|\mathbf{ y})\)
Introduce variable set which is finite dimensional. \[ p(\mathbf{ y}^*|\mathbf{ y}) \approx \int p(\mathbf{ y}^*|\mathbf{ u}) q(\mathbf{ u}|\mathbf{ y}) \text{d}\mathbf{ u} \]
But dimensionality of \(\mathbf{ u}\) can be changed to improve approximation.
Model for our data, \(\mathbf{ y}\)
\[p(\mathbf{ y})\]
Prior density over \(\mathbf{ f}\). Likelihood relates data, \(\mathbf{ y}\), to \(\mathbf{ f}\).
\[p(\mathbf{ y})=\int p(\mathbf{ y}|\mathbf{ f})p(\mathbf{ f})\text{d}\mathbf{ f}\]
Prior density over \(\mathbf{ f}\). Likelihood relates data, \(\mathbf{ y}\), to \(\mathbf{ f}\).
\[p(\mathbf{ y})=\int p(\mathbf{ y}|\mathbf{ f})p(\mathbf{ u}|\mathbf{ f})p(\mathbf{ f})\text{d}\mathbf{ f}\text{d}\mathbf{ u}\]
| \[p(\mathbf{ y})=\int \int p(\mathbf{ y}|\mathbf{ f})p(\mathbf{ f}|\mathbf{ u})\text{d}\mathbf{ f}p(\mathbf{ u})\text{d}\mathbf{ u}\] |
| \[p(\mathbf{ y})=\int \int p(\mathbf{ y}|\mathbf{ f})p(\mathbf{ f}|\mathbf{ u})\text{d}\mathbf{ f}p(\mathbf{ u})\text{d}\mathbf{ u}\] |
| \[p(\mathbf{ y}|\mathbf{ u})=\int p(\mathbf{ y}|\mathbf{ f})p(\mathbf{ f}|\mathbf{ u})\text{d}\mathbf{ f}\] |
| \[p(\mathbf{ y}|\mathbf{ u})\] |
| \[p(\mathbf{ y}|\boldsymbol{ \theta})\] |
- Replace true \(p(\mathbf{ u}|\mathbf{ y})\) with approximation \(q(\mathbf{ u}|\mathbf{ y})\).
- Minimize KL divergence between approximation and truth.
- This is similar to the Bayesian posterior distribution.
- But it’s placed over a set of ‘pseudo-observations’.
\[\mathbf{ f}, \mathbf{ u}\sim \mathcal{N}\left(\mathbf{0},\begin{bmatrix}\mathbf{K}_{\mathbf{ f}\mathbf{ f}}& \mathbf{K}_{\mathbf{ f}\mathbf{ u}}\\\mathbf{K}_{\mathbf{ u}\mathbf{ f}}& \mathbf{K}_{\mathbf{ u}\mathbf{ u}}\end{bmatrix}\right)\] \[\mathbf{ y}|\mathbf{ f}= \prod_{i} \mathcal{N}\left(f,\sigma^2\right)\]
For Gaussian likelihoods:
Define: \[q_{i, i} = \text{var}_{p(f_i|\mathbf{ u})}\left( f_i \right) = \left\langle f_i^2\right\rangle_{p(f_i|\mathbf{ u})} - \left\langle f_i\right\rangle_{p(f_i|\mathbf{ u})}^2\] We can write: \[c_i = \exp\left(-{\frac{q_{i,i}}{2\sigma^2}}\right)\] If joint distribution of \(p(\mathbf{ f}, \mathbf{ u})\) is Gaussian then: \[q_{i, i} = k_{i, i} - \mathbf{ k}_{i, \mathbf{ u}}^\top \mathbf{K}_{\mathbf{ u}, \mathbf{ u}}^{-1} \mathbf{ k}_{i, \mathbf{ u}}\]
\(c_i\) is not a function of \(\mathbf{ u}\) but is a function of \(\mathbf{X}_\mathbf{ u}\).
The sum of \(q_{i,i}\) is the total conditional variance.
If conditional density \(p(\mathbf{ f}|\mathbf{ u})\) is Gaussian then it has covariance \[\mathbf{Q} = \mathbf{K}_{\mathbf{ f}\mathbf{ f}} - \mathbf{K}_{\mathbf{ f}\mathbf{ u}}\mathbf{K}_{\mathbf{ u}\mathbf{ u}}^{-1} \mathbf{K}_{\mathbf{ u}\mathbf{ f}}\]
\(\text{tr}\left(\mathbf{Q}\right) = \sum_{i}q_{i,i}\) is known as total variance.
Because it is on conditional distribution we call it total conditional variance.
Measure the ’capacity of a density’.
Determinant of covariance represents ’volume’ of density.
log determinant is entropy: sum of log eigenvalues of covariance.
trace of covariance is total variance: sum of eigenvalues of covariance.
\(\lambda > \log \lambda\) then total conditional variance upper bounds entropy.
Exponentiated total variance bounds determinant. \[\det{\mathbf{Q}} < \exp \text{tr}\left(\mathbf{Q}\right)\] Because \[\prod_{i=1}^k \lambda_i < \prod_{i=1}^k \exp(\lambda_i)\] where \(\{\lambda_i\}_{i=1}^k\) are the positive eigenvalues of \(\mathbf{Q}\) This in turn implies \[\det{\mathbf{Q}} < \prod_{i=1}^k \exp\left(q_{i,i}\right)\]
Conditional density \(p(\mathbf{ f}|\mathbf{ u})\) can be seen as a communication channel.
Normally we have: \[\text{Transmitter} \stackrel{\mathbf{ u}}{\rightarrow} \begin{smallmatrix}p(\mathbf{ f}|\mathbf{ u}) \\ \text{Channel}\end{smallmatrix} \stackrel{\mathbf{ f}}{\rightarrow} \text{Receiver}\] and we control \(p(\mathbf{ u})\) (the source density).
Here we can also control the transmission channel \(p(\mathbf{ f}|\mathbf{ u})\).
Substitute variational bound into marginal likelihood: \[p(\mathbf{ y})\geq \prod_{i=1}^nc_i \int \mathcal{N}\left(\mathbf{ y}|\left\langle\mathbf{ f}\right\rangle,\sigma^2\mathbf{I}\right)p(\mathbf{ u}) \text{d}\mathbf{ u}\] Note that: \[\left\langle\mathbf{ f}\right\rangle_{p(\mathbf{ f}|\mathbf{ u})} = \mathbf{K}_{\mathbf{ f}, \mathbf{ u}} \mathbf{K}_{\mathbf{ u}, \mathbf{ u}}^{-1}\mathbf{ u}\] is linearly dependent on \(\mathbf{ u}\).
Making the marginalization of \(\mathbf{ u}\) straightforward. In the Gaussian case: \[p(\mathbf{ u}) = \mathcal{N}\left(\mathbf{ u}|\mathbf{0},\mathbf{K}_{\mathbf{ u},\mathbf{ u}}\right)\]
\[\log p(\mathbf{ y}|\mathbf{ u}) = \log\int p(\mathbf{ y}|\mathbf{ f})p(\mathbf{ f}|\mathbf{ u},\mathbf{X})\text{d}\mathbf{ f}\]
\[\log p(\mathbf{ y}|\mathbf{ u}) = \log \mathbb{E}_{p(\mathbf{ f}|\mathbf{ u},\mathbf{X})}\left[p(\mathbf{ y}|\mathbf{ f})\right]\] \[\log p(\mathbf{ y}|\mathbf{ u}) \geq \mathbb{E}_{p(\mathbf{ f}|\mathbf{ u},\mathbf{X})}\left[\log p(\mathbf{ y}|\mathbf{ f})\right]\triangleq \log\widetilde p(\mathbf{ y}|\mathbf{ u})\]
No inversion of \(\mathbf{K}_{\mathbf{ f}\mathbf{ f}}\) required
\[p(\mathbf{ y}|\mathbf{ u}) = \frac{p(\mathbf{ y}|\mathbf{ f})p(\mathbf{ f}|\mathbf{ u})}{p(\mathbf{ f}|\mathbf{ y}, \mathbf{ u})}\] \[\log p(\mathbf{ y}|\mathbf{ u}) = \log p(\mathbf{ y}|\mathbf{ f}) + \log \frac{p(\mathbf{ f}|\mathbf{ u})}{p(\mathbf{ f}|\mathbf{ y}, \mathbf{ u})}\] \[\log p(\mathbf{ y}|\mathbf{ u}) = \bbE_{p(\mathbf{ f}|\mathbf{ u})}\big[\log p(\mathbf{ y}|\mathbf{ f})\big] + \bbE_{p(\mathbf{ f}|\mathbf{ u})}\big[\log \frac{p(\mathbf{ f}|\mathbf{ u})}{p(\mathbf{ f}|\mathbf{ y}, \mathbf{ u})}\big]\] \[\log p(\mathbf{ y}|\mathbf{ u}) = \widetilde p(\mathbf{ y}|\mathbf{ u}) + \textsc{KL}[p(\mathbf{ f}|\mathbf{ u})||p(\mathbf{ f}|\mathbf{ y}, \mathbf{ u})]\]
No inversion of \(\mathbf{K}_{\mathbf{ f}\mathbf{ f}}\) required
\[\widetilde p(\mathbf{ y}|\mathbf{ u}) = \prod_{i=1}^n\widetilde p(y_i|\mathbf{ u})\] \[\widetilde p(y|\mathbf{ u}) = \mathcal{N}\left(y|\mathbf{ k}_{fu}\mathbf{K}_{\mathbf{ u}\mathbf{ u}}^{-1}\mathbf{ u},\sigma^2\right) \,{\color{red}\exp\left\{-\tfrac{1}{2\sigma^2}\left(k_{ff}- \mathbf{ k}_{fu}\mathbf{K}_{\mathbf{ u}\mathbf{ u}}^{-1}\mathbf{ k}_{uf}\right)\right\}}\]
A straightforward likelihood approximation, and a penalty term
\[\widetilde p(\mathbf{ u}|\mathbf{ y},\mathbf{Z}) = \frac{\widetilde p(\mathbf{ y}|\mathbf{ u})p(\mathbf{ u}|\mathbf{Z})}{\int \widetilde p(\mathbf{ y}|\mathbf{ u})p(\mathbf{ u}|\mathbf{Z})\text{d}{\mathbf{ u}}}\]
Computing the posterior costs \(\mathcal{O}(nm^2)\)
We also get a lower bound of the marginal likelihood
\[{\color{red}\sum_{i=1}^n-\tfrac{1}{2\sigma^2}\left(k_{ff}- \mathbf{ k}_{fu}\mathbf{K}_{\mathbf{ u}\mathbf{ u}}^{-1}\mathbf{ k}_{uf}\right)}\]
\[{\color{red}\sum_{i=1}^n-\tfrac{1}{2\sigma^2}\left(k_{ff}- \mathbf{ k}_{fu}\mathbf{K}_{\mathbf{ u}\mathbf{ u}}^{-1}\mathbf{ k}_{uf}\right)}\]
It’s easy to show that as \(\mathbf{Z}\to \mathbf{X}\):
\(\mathbf{ u}\to \mathbf{ f}\) (and the posterior is exact)
The penalty term is zero.
The cost returns to \(\mathcal{O}(n^3)\)
So far we:
introduced \(\mathbf{Z}, \mathbf{ u}\)
approximated the intergral over \(\mathbf{ f}\) variationally
captured the information in \(\widetilde p(\mathbf{ u}|\mathbf{ y})\)
obtained a lower bound on the marginal likeihood
saw the effect of the penalty term
prediction for new points
Omitted details:
optimization of the covariance parameters using the bound
optimization of Z (simultaneously)
the form of \(\widetilde p(\mathbf{ u}|\mathbf{ y})\)
historical approximations
Random or systematic
Set \(\mathbf{Z}\) to subset of \(\mathbf{X}\)
Set \(\mathbf{ u}\) to subset of \(\mathbf{ f}\)
Approximation to \(p(\mathbf{ y}|\mathbf{ u})\):
$ p(_i) = p(_i_i) i$
$ p(_i) = 1 i$
{Deterministic Training Conditional (DTC)}
Approximation to \(p(\mathbf{ y}|\mathbf{ u})\):
- $ p(_i) = (_i, [_i])$
As our variational formulation, but without penalty
Optimization of \(\mathbf{Z}\) is difficult
Fully Independent Training ConditionalApproximation to \(p(\mathbf{ y}|\mathbf{ u})\):
$ p() = _i p(_i) $
Optimization of \(\mathbf{Z}\) is still difficult, and there are some weird heteroscedatic effects
- GP-LVM Provides probabilistic non-linear dimensionality reduction.
- How to select the dimensionality?
- Need to estimate marginal likelihood.
- In standard GP-LVM it increases with increasing \(q\).
|
Bayesian GP-LVM
|
|
Standard Variational Approach Fails
- Standard variational bound has the form: \[ \mathcal{L}= \left\langle\log p(\mathbf{ y}|\mathbf{Z})\right\rangle_{q(\mathbf{Z})} + \text{KL}\left( q(\mathbf{Z})\,\|\,p(\mathbf{Z}) \right) \]
The standard variational approach would require the expectation of \(\log p(\mathbf{ y}|\mathbf{Z})\) under \(q(\mathbf{Z})\). \[ \begin{align} \log p(\mathbf{ y}|\mathbf{Z}) = & -\frac{1}{2}\mathbf{ y}^\top\left(\mathbf{K}_{\mathbf{ f}, \mathbf{ f}}+\sigma^2\mathbf{I}\right)^{-1}\mathbf{ y}\\ & -\frac{1}{2}\log \det{\mathbf{K}_{\mathbf{ f}, \mathbf{ f}}+\sigma^2 \mathbf{I}} -\frac{n}{2}\log 2\pi \end{align} \] But this is extremely difficult to compute because \(\mathbf{K}_{\mathbf{ f}, \mathbf{ f}}\) is dependent on \(\mathbf{Z}\) and it appears in the inverse.
Variational Bayesian GP-LVM
The alternative approach is to consider the collapsed variational bound (used for low rank (sparse is a misnomer) Gaussian process approximations. \[ p(\mathbf{ y})\geq \prod_{i=1}^nc_i \int \mathcal{N}\left(\mathbf{ y}|\left\langle\mathbf{ f}\right\rangle,\sigma^2\mathbf{I}\right)p(\mathbf{ u}) \text{d}\mathbf{ u} \] \[ p(\mathbf{ y}|\mathbf{Z})\geq \prod_{i=1}^nc_i \int \mathcal{N}\left(\mathbf{ y}|\left\langle\mathbf{ f}\right\rangle_{p(\mathbf{ f}|\mathbf{ u}, \mathbf{Z})},\sigma^2\mathbf{I}\right)p(\mathbf{ u}) \text{d}\mathbf{ u} \] \[ \int p(\mathbf{ y}|\mathbf{Z})p(\mathbf{Z}) \text{d}\mathbf{Z}\geq \int \prod_{i=1}^nc_i \mathcal{N}\left(\mathbf{ y}|\left\langle\mathbf{ f}\right\rangle_{p(\mathbf{ f}|\mathbf{ u}, \mathbf{Z})},\sigma^2\mathbf{I}\right) p(\mathbf{Z})\text{d}\mathbf{Z}p(\mathbf{ u}) \text{d}\mathbf{ u} \]
To integrate across \(\mathbf{Z}\) we apply the lower bound to the inner integral. \[ \begin{align} \int \prod_{i=1}^nc_i \mathcal{N}\left(\mathbf{ y}|\left\langle\mathbf{ f}\right\rangle_{p(\mathbf{ f}|\mathbf{ u}, \mathbf{Z})},\sigma^2\mathbf{I}\right) p(\mathbf{Z})\text{d}\mathbf{Z}\geq & \left\langle\sum_{i=1}^n\log c_i\right\rangle_{q(\mathbf{Z})}\\ & +\left\langle\log\mathcal{N}\left(\mathbf{ y}|\left\langle\mathbf{ f}\right\rangle_{p(\mathbf{ f}|\mathbf{ u}, \mathbf{Z})},\sigma^2\mathbf{I}\right)\right\rangle_{q(\mathbf{Z})}\\& + \text{KL}\left( q(\mathbf{Z})\,\|\,p(\mathbf{Z}) \right) \end{align} \] * Which is analytically tractable for Gaussian \(q(\mathbf{Z})\) and some covariance functions.
Need expectations under \(q(\mathbf{Z})\) of: \[ \log c_i = \frac{1}{2\sigma^2} \left[k_{i, i} - \mathbf{ k}_{i, \mathbf{ u}}^\top \mathbf{K}_{\mathbf{ u}, \mathbf{ u}}^{-1} \mathbf{ k}_{i, \mathbf{ u}}\right] \] and \[ \log \mathcal{N}\left(\mathbf{ y}|\left\langle\mathbf{ f}\right\rangle_{p(\mathbf{ f}|\mathbf{ u},\mathbf{Y})},\sigma^2\mathbf{I}\right) = -\frac{1}{2}\log 2\pi\sigma^2 - \frac{1}{2\sigma^2}\left(y_i - \mathbf{K}_{\mathbf{ f}, \mathbf{ u}}\mathbf{K}_{\mathbf{ u},\mathbf{ u}}^{-1}\mathbf{ u}\right)^2 \]
This requires the expectations \[ \left\langle\mathbf{K}_{\mathbf{ f},\mathbf{ u}}\right\rangle_{q(\mathbf{Z})} \] and \[ \left\langle\mathbf{K}_{\mathbf{ f},\mathbf{ u}}\mathbf{K}_{\mathbf{ u},\mathbf{ u}}^{-1}\mathbf{K}_{\mathbf{ u},\mathbf{ f}}\right\rangle_{q(\mathbf{Z})} \] which can be computed analytically for some covariance functions (Damianou et al., 2016) or through sampling (Damianou, 2015; Salimbeni and Deisenroth, 2017).
Augment each layer with inducing variables \(\mathbf{ u}_i\).
Apply variational compression, \[\begin{align} p(\mathbf{ y}, \{\mathbf{ h}_i\}_{i=1}^{\ell-1}|\{\mathbf{ u}_i\}_{i=1}^{\ell}, \mathbf{X}) \geq & \tilde p(\mathbf{ y}|\mathbf{ u}_{\ell}, \mathbf{ h}_{\ell-1})\prod_{i=2}^{\ell-1} \tilde p(\mathbf{ h}_i|\mathbf{ u}_i,\mathbf{ h}_{i-1}) \tilde p(\mathbf{ h}_1|\mathbf{ u}_i,\mathbf{X}) \nonumber \\ & \times \exp\left(\sum_{i=1}^\ell-\frac{1}{2\sigma^2_i}\text{tr}\left(\boldsymbol{ \Sigma}_{i}\right)\right) \label{eq:deep_structure} \end{align}\] where \[\tilde p(\mathbf{ h}_i|\mathbf{ u}_i,\mathbf{ h}_{i-1}) = \mathcal{N}\left(\mathbf{ h}_i|\mathbf{K}_{\mathbf{ h}_{i}\mathbf{ u}_{i}}\mathbf{K}_{\mathbf{ u}_i\mathbf{ u}_i}^{-1}\mathbf{ u}_i,\sigma^2_i\mathbf{I}\right).\]
By sustaining explicity distributions over inducing variables James Hensman has developed a nested variant of variational compression.
Exciting thing: it mathematically looks like a deep neural network, but with inducing variables in the place of basis functions.
Additional complexity control term in the objective function.
\[\begin{align} \log p(\mathbf{ y}|\mathbf{X}) \geq & % -\frac{1}{\sigma_1^2} \text{tr}\left(\boldsymbol{ \Sigma}_1\right) % -\sum_{i=2}^\ell\frac{1}{2\sigma_i^2} \left(\psi_{i} % - \text{tr}\left({\boldsymbol \Phi}_{i}\mathbf{K}_{\mathbf{ u}_{i} \mathbf{ u}_{i}}^{-1}\right)\right) \nonumber \\ % & - \sum_{i=1}^{\ell}\text{KL}\left( q(\mathbf{ u}_i)\,\|\,p(\mathbf{ u}_i) \right) \nonumber \\ % & - \sum_{i=2}^{\ell}\frac{1}{2\sigma^2_{i}}\text{tr}\left(({\boldsymbol \Phi}_i - {\boldsymbol \Psi}_i^\top{\boldsymbol \Psi}_i) \mathbf{K}_{\mathbf{ u}_{i} \mathbf{ u}_{i}}^{-1} \left\langle\mathbf{ u}_{i}\mathbf{ u}_{i}^\top\right\rangle_{q(\mathbf{ u}_{i})}\mathbf{K}_{\mathbf{ u}_{i}\mathbf{ u}_{i}}^{-1}\right) \nonumber \\ % & + {\only<2>{\color{red}}\log \mathcal{N}\left(\mathbf{ y}|{\boldsymbol \Psi}_{\ell}\mathbf{K}_{\mathbf{ u}_{\ell} \mathbf{ u}_{\ell}}^{-1}{\mathbf m}_\ell,\sigma^2_\ell\mathbf{I}\right)} \label{eq:deep_bound} \end{align}\]
\[{\only<1>{\color{red}}\log \mathcal{N}\left(\mathbf{ y}|{\only<2->{\color{blue}}{\boldsymbol \Psi}_{\ell}}\mathbf{K}_{\mathbf{ u}_{\ell} \mathbf{ u}_{\ell}}^{-1}{\mathbf m}_\ell,\sigma^2_\ell\mathbf{I}\right)}\] where
For Gaussian likelihoods:
Define: \[q_{i, i} = \text{var}_{p(f_i|\mathbf{ u})}\left( f_i \right) = \left\langle f_i^2\right\rangle_{p(f_i|\mathbf{ u})} - \left\langle f_i\right\rangle_{p(f_i|\mathbf{ u})}^2\] We can write: \[c_i = \exp\left(-{\frac{q_{i,i}}{2\sigma^2}}\right)\] If joint distribution of \(p(\mathbf{ f}, \mathbf{ u})\) is Gaussian then: \[q_{i, i} = k_{i, i} - \mathbf{ k}_{i, \mathbf{ u}}^\top \mathbf{K}_{\mathbf{ u}, \mathbf{ u}}^{-1} \mathbf{ k}_{i, \mathbf{ u}}\]
\(c_i\) is not a function of \(\mathbf{ u}\) but is a function of \(\mathbf{X}_\mathbf{ u}\).
Substitute variational bound into marginal likelihood: \[p(\mathbf{ y})\geq \prod_{i=1}^nc_i \int \mathcal{N}\left(\mathbf{ y}|\left\langle\mathbf{ f}\right\rangle,\sigma^2\mathbf{I}\right)p(\mathbf{ u}) \text{d}\mathbf{ u}\] Note that: \[\left\langle\mathbf{ f}\right\rangle_{p(\mathbf{ f}|\mathbf{ u})} = \mathbf{K}_{\mathbf{ f}, \mathbf{ u}} \mathbf{K}_{\mathbf{ u}, \mathbf{ u}}^{-1}\mathbf{ u}\] is linearly dependent on \(\mathbf{ u}\).
Making the marginalization of \(\mathbf{ u}\) straightforward. In the Gaussian case: \[p(\mathbf{ u}) = \mathcal{N}\left(\mathbf{ u}|\mathbf{0},\mathbf{K}_{\mathbf{ u},\mathbf{ u}}\right)\]
Thang and Turner paper
Joint Gaussianity is analytic, but not flexible.
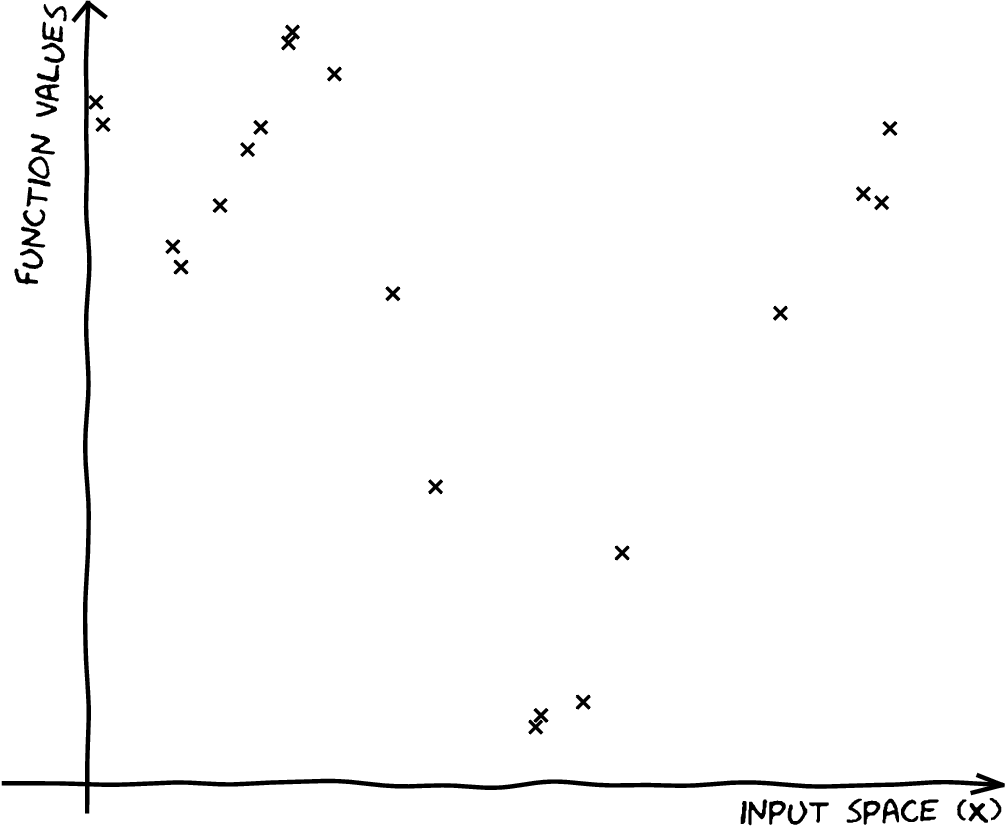
A Simple Regression Problem
Here we set up a simple one dimensional regression problem. The input locations, \(\mathbf{X}\), are in two separate clusters. The response variable, \(\mathbf{ y}\), is sampled from a Gaussian process with an exponentiated quadratic covariance.
import numpy as np
import GPynp.random.seed(101)N = 50
noise_var = 0.01
X = np.zeros((50, 1))
X[:25, :] = np.linspace(0,3,25)[:,None] # First cluster of inputs/covariates
X[25:, :] = np.linspace(7,10,25)[:,None] # Second cluster of inputs/covariates
# Sample response variables from a Gaussian process with exponentiated quadratic covariance.
k = GPy.kern.RBF(1)
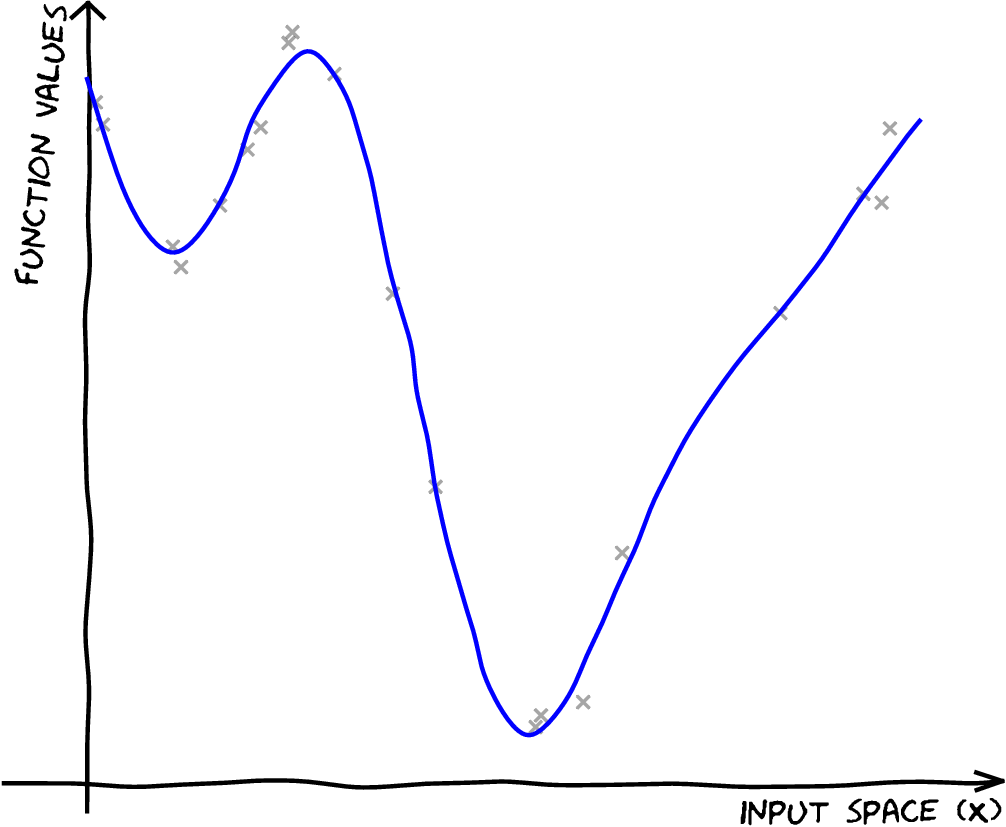
y = np.random.multivariate_normal(np.zeros(N),k.K(X)+np.eye(N)*np.sqrt(noise_var)).reshape(-1,1)First we perform a full Gaussian process regression on the data. We
create a GP model, m_full, and fit it to the data, plotting
the resulting fit.
m_full = GPy.models.GPRegression(X,y)
_ = m_full.optimize(messages=True) # Optimize parameters of covariance functionFigure: Full Gaussian process fitted to the data set.
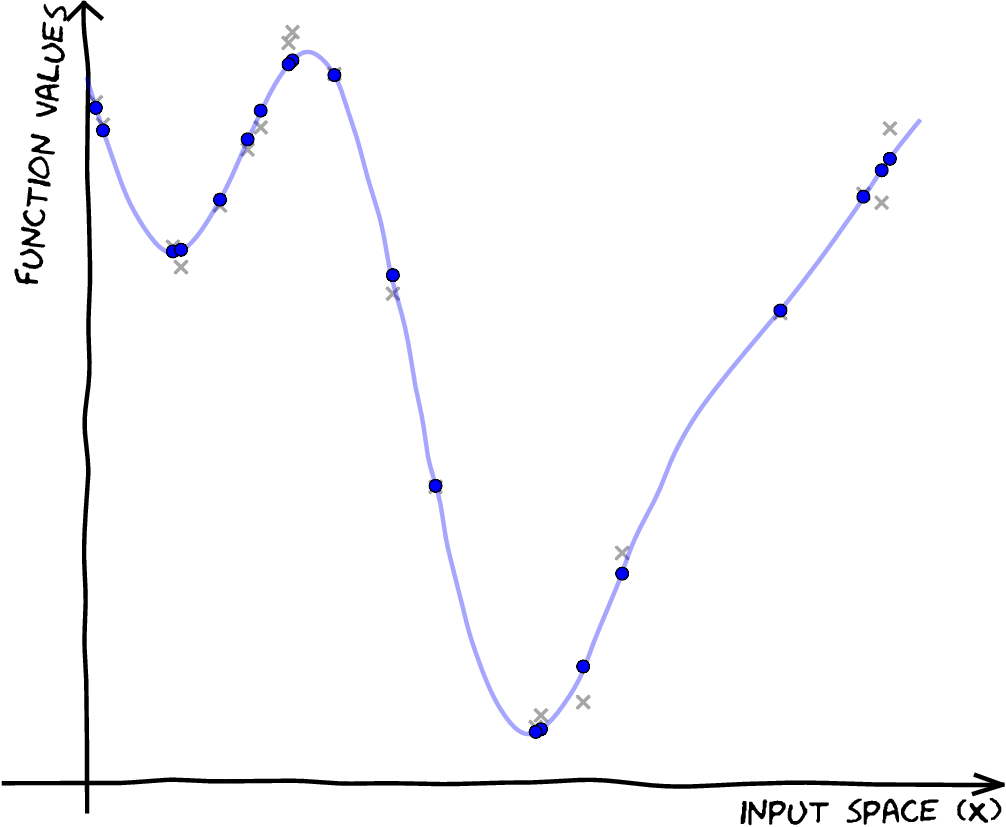
Now we set up the inducing variables, \(\mathbf{u}\). Each inducing variable has its own associated input index, \(\mathbf{Z}\), which lives in the same space as \(\mathbf{X}\). Here we are using the true covariance function parameters to generate the fit.
kern = GPy.kern.RBF(1)
Z = np.hstack(
(np.linspace(2.5,4.,3),
np.linspace(7,8.5,3)))[:,None]
m = GPy.models.SparseGPRegression(X,y,kernel=kern,Z=Z)
m.noise_var = noise_var
m.inducing_inputs.constrain_fixed()
display(m)Figure: Sparse Gaussian process fitted with six inducing variables, no optimization of parameters or inducing variables.
_ = m.optimize(messages=True)
display(m)Figure: Gaussian process fitted with inducing variables fixed and parameters optimized
m.randomize()
m.inducing_inputs.unconstrain()
_ = m.optimize(messages=True)Figure: Gaussian process fitted with location of inducing variables and parameters both optimized
Now we will vary the number of inducing points used to form the approximation.
m.num_inducing=8
m.randomize()
M = 8
m.set_Z(np.random.rand(M,1)*12)
_ = m.optimize(messages=True)Figure: Comparison of the full Gaussian process fit with a sparse Gaussian process using eight inducing varibles. Both inducing variables and parameters are optimized.
And we can compare the probability of the result to the full model.
print(m.log_likelihood(), m_full.log_likelihood())Thanks!
For more information on these subjects and more you might want to check the following resources.
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com