
Topic 7: Bias, Variance and Fairness: Stochasticity in Decision Making
Overview
In this topic we will explore the relationship between the bias-variance dilemma and real world decisions. The opening session will set the context, then we will read the following four papers.
- Neural Networks and the Bias/Variance Dilemma by Stuart Geman, Elie Bienenstock, and René Doursat (the technical material of importance is in Section 3).
- Probabilistic electrol methods, representative proability and Maximum Entropy by Roger Sewell, David MacKay and Ian McLean
- Habitual Ethics? Chapter 7 by Sylvie Delacroix
- Killing, Letting Die and the Trolley Problem by Judith Jarvis Thomson
The presentation for each paper will be in the form of an 800 word summary that captures the main message of the work and sets it against the context of the wider discussion we will set up in this first session.
Justice: What’s The Right Thing to Do?


Figure: Sandel’s book looks at how to do the right thing with a context of moreal philosophy. Sandel (2010)
In the book “Justice: What’s The Right Thing to Do?” (Sandel, 2010) Michael Sandel aims to help us answer questions about how to do the right thing by giving some context and background in moral philosophy. Sandel is a philosopher based at Harvard University who is reknowned for his popular treatments of the subject. He starts by illustrating decision making through the ‘trolley’ problem.
The Trolley Problem

Figure: The trolley problem in its original form.
The trolley problem has become a mainstay of debates around driverless cards and is often rather crudely used, but it is more subtly wielded in is introduction by Foot (1967) where it is used as part of her analysis of the doctrine of double effect where actions have results that are not intended (oblique intention).
In the world of science, utilitarianism as a philosophy maps onto what we think of as utility theory. The assumption is that the quality of any decision can be evaluated mathematically.
This gives us an approach to balancing between the sensitivity and the specificity of any decision. The basic approach is to define a utility function, which defines the worth of different outcomes.
In machine learning this utility function maps onto what we think of as the objective function (also known as the loss, the cost function or the error function).
Artificial vs Natural Systems
Let’s take a step back from artificial intelligence, and consider natural intelligence. Or even more generally, let’s consider the contrast between an artificial system and an natural system. The key difference between the two is that artificial systems are designed whereas natural systems are evolved.
Systems design is a major component of all Engineering disciplines. The details differ, but there is a single common theme: achieve your objective with the minimal use of resources to do the job. That provides efficiency. The engineering designer imagines a solution that requires the minimal set of components to achieve the result. A water pump has one route through the pump. That minimises the number of components needed. Redundancy is introduced only in safety critical systems, such as aircraft control systems. Students of biology, however, will be aware that in nature system-redundancy is everywhere. Redundancy leads to robustness. For an organism to survive in an evolving environment it must first be robust, then it can consider how to be efficient. Indeed, organisms that evolve to be too efficient at a particular task, like those that occupy a niche environment, are particularly vulnerable to extinction.
This notion is akin to the idea that only the best will survive, popularly encoded into an notion of evolution by Herbert Spencer’s quote.
Survival of the fittest
Herbet Spencer, 1864
Darwin himself never said “Survival of the Fittest” he talked about evolution by natural selection.
Non-survival of the non-fit
Evolution is better described as “non-survival of the non-fit”. You don’t have to be the fittest to survive, you just need to avoid the pitfalls of life. This is the first priority.
So it is with natural vs artificial intelligences. Any natural intelligence that was not robust to changes in its external environment would not survive, and therefore not reproduce. In contrast the artificial intelligences we produce are designed to be efficient at one specific task: control, computation, playing chess. They are fragile.
The first rule of a natural system is not be intelligent, it is “don’t be stupid”.
A mistake we make in the design of our systems is to equate fitness with the objective function, and to assume it is known and static. In practice, a real environment would have an evolving fitness function which would be unknown at any given time.
You can also read this blog post on Natural and Artificial Intelligence..
The first criterion of a natural intelligence is don’t fail, not because it has a will or intent of its own, but because if it had failed it wouldn’t have stood the test of time. It would no longer exist. In contrast, the mantra for artificial systems is to be more efficient. Our artificial systems are often given a single objective (in machine learning it is encoded in a mathematical function) and they aim to achieve that objective efficiently. These are different characteristics. Even if we wanted to incorporate don’t fail in some form, it is difficult to design for. To design for “don’t fail”, you have to consider every which way in which things can go wrong, if you miss one you fail. These cases are sometimes called corner cases. But in a real, uncontrolled environment, almost everything is a corner. It is difficult to imagine everything that can happen. This is why most of our automated systems operate in controlled environments, for example in a factory, or on a set of rails. Deploying automated systems in an uncontrolled environment requires a different approach to systems design. One that accounts for uncertainty in the environment and is robust to unforeseen circumstances.
One of the most understood aspects of evolution is the idea that evolution is survival of the fittest. It’s better described of non-survival of the non-fit, and what fit even means is highly subjective. Any utility function evolves socially andwith our environment. “Survival of the fittest”is not due to Darwin it’s associated with Herbert Spencer and closely associated with social Darwinism which has little to do with the way that evolution operates in practice.
Absolute Policies
Because of these uncertainties there’s an emergent rule:
There will be no single absolute policy that should be followed slavishly in all circumstances
George Box
Since all models are wrong the scientist must be alert to what is importantly wrong. It is inappropriate to be concerned about mice when there are tigers abroad.
George E. P. Box (Box, 1976)
Tigers and Trolleys
In the world of trolley problems this perhaps maps best to the version of the problem where to save the lives of five people you have to push a large gentleman off a bridge.
The Push and the Trolley

Figure: In the situation where you push an overweight gentleman, the decision is riddled with uncertainty. Doubt inevitably creeps in.
In Thomson (1976) a variation on Foot’s original formulation is considered which is allowing us to see the challenge from a transplant surgeon’s perspective: Thomson contrives a variation of the problem which is similar to the idea that a transplant surgeon should harvest organs to save the lives of five people.
Uncertainty: The Tyger that Burns Bright
Tyter Tyger, burning bright, In the forests of the night; What immortal hand or eye, Could frame thy fearful symmetry?
First verse of The Tyger by William Blake, 1794
A major challenge with this notion of utility is the assumption that we can describe our objectives mathematically. Once this notion is challenged some severe weaknesses in the way we do machine learning can be seen to emerge.
What is Machine Learning?
Machine learning allows us to extract knowledge from data to form a prediction.
\[\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} \text{prediction}\]
A machine learning prediction is made by combining a model with data to form the prediction. The manner in which this is done gives us the machine learning algorithm.
Machine learning models are mathematical models which make weak assumptions about data, e.g. smoothness assumptions. By combining these assumptions with the data, we observe we can interpolate between data points or, occasionally, extrapolate into the future.
Machine learning is a technology which strongly overlaps with the methodology of statistics. From a historical/philosophical view point, machine learning differs from statistics in that the focus in the machine learning community has been primarily on accuracy of prediction, whereas the focus in statistics is typically on the interpretability of a model and/or validating a hypothesis through data collection.
The rapid increase in the availability of compute and data has led to the increased prominence of machine learning. This prominence is surfacing in two different but overlapping domains: data science and artificial intelligence.
From Model to Decision
The real challenge, however, is end-to-end decision making. Taking information from the environment and using it to drive decision making to achieve goals.
Prospect Theory
Daniel Kahneman won the Nobel Memorial Prize for work on the idea of prospect theory. The theory is based on empirical studies around how humans make decisions, and suggests that not only are they sensitive to change of circumstance, rather than absolute circumstance, there is an asymmetry to the sensitivity associated with negative and positive changes.
Kahneman (2011) was a book that presented this idea but also popularised the notion of dual process cognition: where thoughts are separated into fast thinking and slow thinking. In the history of the philosophy of ethics, an ethical decision has always been associated with intentional or reflective actions. Sylvie Delacroix’s book Habitual Ethics (Delacroix, 2022) establishes the case for a theory of ethics arising from habitual (presumably fast-thinking) decisions.
Subjective Utility
Jeremy Bentham’s ideas around maximising happiness are focussed on the ide of a global utility, but natural selection suggests that there should be variation in the population, otherwise there will be no separation between effective and ineffective strategies. So in practice utilities (if they exist) must be subjective, they would vary from individual to individual.
A Cognitive Bias towards Variance
Kahneman’s book explores various ways in which humans might be considered “irrational”, for example our tendency to produce overcomplicated explanations. If prediction is of the form \[ \text{model} + \text{data} \rightarrow \text{prediction}\] then Kahneman explores the seemingly reasonable proposal that predictions from different experts should be consistent. After all, how could the predictions be correct if they are inconsistent. From a statistical perspective, simpler models tend to be more consistent. So this suggests to Kahneman that humans overcomplicate. However, once we accept that errors will be made (e.g. due to uncertainty) then we can notice that a push for consistency is a push for consistency of error.
Bias vs Variance
One way of looking at this technically in machine learning is to decompose our generalization error into two parts. The bias-variance dilemma emerges from looking at these two parts and observing that part of our error comes from oversimplification in our model (the bias error) and part of our error comes from the fact that there’s insufficient data to pin down the parameters of a more complex model (the variance error).
In Machine Learning
In the past (before the neural network revolution!) there were two principle approaches to resolving the bias-variance dilemma. Either you use over simple models, which lead to better consistency in their generalization and well determined parameters. Or you use more complex models and make use of some form of averaging to deal with the variance.
- Two approaches
- Use simpler models (better consistency and good generalization)
- Use more complex models and average to remove variance.
Bias vs Variance Error Plots
Helper function for sampling data from two different classes.
import numpy as npHelper function for plotting the decision boundary of the SVM.
import urllib.requesturllib.request.urlretrieve('https://raw.githubusercontent.com/lawrennd/talks/gh-pages/mlai.py','mlai.py')import matplotlib
font = {'family' : 'sans',
'weight' : 'bold',
'size' : 22}
matplotlib.rc('font', **font)
import matplotlib.pyplot as pltfrom sklearn import svm# Create an instance of SVM and fit the data.
C = 100.0 # SVM regularization parameter
gammas = [0.001, 0.01, 0.1, 1]
per_class=30
num_samps = 20
# Set-up 2x2 grid for plotting.
fig, ax = plt.subplots(1, 4, figsize=(10,3))
xlim=None
ylim=None
for samp in range(num_samps):
X, y=create_data(per_class)
models = []
titles = []
for gamma in gammas:
models.append(svm.SVC(kernel='rbf', gamma=gamma, C=C))
titles.append('$\gamma={}$'.format(gamma))
models = (cl.fit(X, y) for cl in models)
xlim, ylim = decision_boundary_plot(models, X, y,
axs=ax,
filename='bias-variance{samp:0>3}.svg'.format(samp=samp),
directory='./ml'
titles=titles,
xlim=xlim,
ylim=ylim)%pip install pods

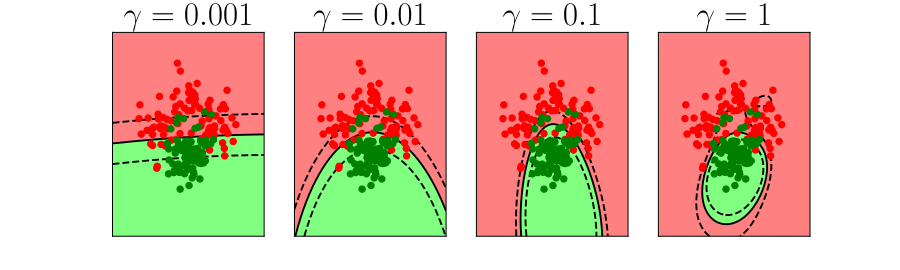
Figure: In each figure the simpler model is on the left, and the more complex model is on the right. Each fit is done to a different version of the data set. The simpler model is more consistent in its errors (bias error), whereas the more complex model is varying in its errors (variance error).
Decision Making and Bias-Variance
However in a population, where there are many decision makers, I would argue we should always err towards variance error rather than bias. This is because the averaging effects occur naturally, and we don’t have large sections of the population making consistent errors.
In practice averaging of variance errors is also prosed by Breiman and is called bagging (Breiman, 1996). (Another ensemble method that works with biased models is called boosting.
Rational Behaviour
My argument is that rational behviour requires variation. That it allows us to sustain a variety of approaches to life. That there is no single utility that we should all be optimising.
{So the observations that humans “over complicate” whether it’s in football punditry or as Meehl (1954) observes in clinical prediction, is associated with
One Correct Solution
The idea that there is one solution and that we can somehow have access to it has led to some of the horrors of science. For example, in eugenics, the notion of artificial selection (where some aspect(s) of a species is/are selected and accentuated through artifical breeding) is applied to humans. Disregarding the natural moral repulsion this engenders, it also betrays some simplistic misunderstandings of the process of evolution. What is OK for greyhounds, wheat breeds, race horses, sheep and cows is not OK for humans.
I may not agree with many people’s subjective approach to life, I may even believe it to be severely sub-optimal. But I should not presume to know better, even if prior experience shows that my own ‘way of being’ is effective.
Variation is vitally important for robustness. There may be future circumstances where my approaches fail utterly, and other ways of being are better.
If we do all have different approaches to life, then in the long run the quality of these approaches is measured by a effectiveness (which will also owe a lot to luck). From a species persistence perspective, each of these approaches is one component in our make up. The notion of a universl utility by which we are all judged is difficult (or impossible) to define.
The Real Ethical Dilemma
For driverless cars, the trolley problem is an oversimplificiation, because when people are killed it will not be through “reflective decisions” that those deaths occur, but through a consipiracy of happenstance events.
That does not mean there are no ethical dilemmas, any automation technology will have uneven effects across society. So, for example, it may be that introducing driverless cars we achieve a 90% reduction in deaths. But what if all those that now die are cyclists?
Fairness in Decision Making
As a more general example, let’s consider fairness in decision making. Computers make decisions on the basis of our data, how can we have confidence in those decisions?

Figure: The convention for the protection of individuals with regard to the processing of personal data was opened for signature on 28th January 1981. It was the first legally binding international instrument in the field of data protection.
GDPR Origins
There’s been much recent talk about GDPR, much of it implying that the recent incarnation is radically different from previous incarnations. While the most recent iteration began to be developed in 2012, but in reality, its origins are much older. It dates back to 1981, and 28th January is “Data Potection day”. The essence of the law didn’t change much in the previous iterations. The critical chance was the size of the fines that the EU stipulated may be imposed for infringements. Paul Nemitz, who was closely involved with the drafting, told me that they were initially inspired by competition law, which levies fines of 10% of international revenue. The final implementation is restricted to 5%, but it’s worth pointing out that Facebook’s fine (imposed in the US by the FTC) was $5 billion dollars. Or approximately 7% of their international revenue at the time.
So the big change is the seriousness with which regulators are taking breaches of the intent of GDPR. And indeed, this newfound will on behalf of the EU led to an amount of panic around companies who rushed to see if they were complying with this strengthened legislation.
But is it really the big bad regulator coming down hard on the poor scientist or company, just trying to do an honest day’s work? I would argue not. The stipulations of the GDPR include fairly simple things like the ‘right to an explanation’ for consequential decision-making. Or the right to deletion, to remove personal private data from a corporate data ecosystem.
Guardian article on Digital Oligarchies
While these are new stipulations, if you reverse the argument and ask a company “would it not be a good thing if you could explain why your automated decision making system is making decision X about customer Y” seems perfectly reasonable. Or “Would it not be a good thing if we knew that we were capable of deleting customer Z’s data from our systems, rather than being concerned that it may be lying unregistered in an S3 bucket somewhere?”.
Phrased in this way, you can see that GDPR perhaps would better stand for “Good Data Practice Rules”, and should really be being adopted by the scientist, the company or whoever in an effort to respect the rights of the people they aim to serve.
So how do Data Trusts fit into this landscape? Well it’s appropriate that we’ve mentioned the commons, because a current challenge is how we manage data rights within our community. And the situation is rather akin to that which one might have found in a feudal village (in the days before Houndkirk Moor was enclosed).
How the GDPR May Help
Figure: The convention for the protection of individuals with regard to the processing of personal data was opened for signature on 28th January 1981. It was the first legally binding international instrument in the field of data protection.
Early reactions to the General Data Protection Regulation by companies seem to have been fairly wary, but if we view the principles outlined in the GDPR as good practice, rather than regulation, it feels like companies can only improve their internal data ecosystems by conforming to the GDPR. For this reason, I like to think of the initials as standing for “Good Data Practice Rules” rather than General Data Protection Regulation. In particular, the term “data protection” is a misnomer, and indeed the earliest data protection directive from the EU (from 1981) refers to the protection of individuals with regard to the automatic processing of personal data, which is a much better sense of the term.
If we think of the legislation as protecting individuals, and we note that it seeks, and instead of viewing it as regulation, we view it as “Wouldn’t it be good if …”, e.g. in respect to the “right to an explanation”, we might suggest: “Wouldn’t it be good if we could explain why our automated decision making system made a particular decison”. That seems like good practice for an organization’s automated decision making systems.
Similarly, with regard to data minimization principles. Retaining the minimum amount of personal data needed to drive decisions could well lead to better decision making as it causes us to become intentional about which data is used rather than the sloppier thinking that “more is better” encourages. Particularly when we consider that to be truly useful data has to be cleaned and maintained.
If GDPR is truly reflecting the interests of individuals, then it is also reflecting the interests of consumers, patients, users etc, each of whom make use of these systems. For any company that is customer facing, or any service that prides itself on the quality of its delivery to those individuals, “good data practice” should become part of the DNA of the organization.
GDPR in Practice
Need to understand why you are processing personal data, for example see the ICO’s Lawful Basis Guidance and their Lawful Basis Guidance Tool.
For websites, if you are processing personal data you will need a privacy policy to be in place. See the ICO’s Make your own privacy notice site which also provides a template.
The GDPR gives us some indications of the aspects we might consider when judging whether or not a decision is “fair”.
But when considering fairness, it seems that there’s two forms that we might consider.
\(p\)-Fairness and \(n\)-Fairness
Figure: We seem to have two different aspects to fairness, which in practice can be in tension.
We’ve outlined \(n\)-fairness and \(p\)-fairness. By \(n\)-fairness we mean the sort of considerations that are associated with substantive equality of opportunity vs formal equality of opportunity. Formal equality of community is related to \(p\)-fairness. This is sometimes called procedural fairness and we might think of it as a performative form of fairness. It’s about clarity of rules, for example as applied in sport. \(n\)-Fairness is more nuanced. It’s a reflection of society’s normative judgment about how individuals may have been disadvantaged, e.g. due to their upbringing.
The important point here is that these forms of fairness are in tension. Good procedural fairness needs to be clear and understandable. It should be clear to everyone what the rules are, they shouldn’t be obscured by jargon or overly subtle concepts. \(p\)-Fairness should not be easily undermined by adversaries, it should be difficult to “cheat” good \(p\)-fairness. However, \(n\)-fairness requires nuance, understanding of the human condition, where we came from and how different individuals in our society have been advantaged or disadvantaged in their upbringing and their access to opportunity.
Pure \(n\)-fairness and pure \(p\)-fairness both have the feeling of dystopias. In practice, any decision making system needs to balance the two. The correct point of operation will depend on the context of the decision. Consider fair rules of a game of football, against fair distribution of social benefit. It is unlikely that there is ever an objectively correct balance between the two for any given context. Different individuals will favour \(p\) vs \(n\) according to their personal values.
Given the tension between the two forms of fairness, with \(p\) fairness requiring simple rules that are understandable by all, and \(n\) fairness requiring nuance and subtlety, how do we resolve this tension in practice?
Normally in human systems, significant decisions involve trained professionals. For example, judges, or accountants or doctors.
Training a professional involves lifting their “reflexive” response to a situation with “reflective” thinking about the consequences of their decision that rely not just on the professional’s expertise, but also their knowledge of what it is to be a human.
This marvellous resolution exploits the fact that while humans are increadibly complicated nuanced entities, other humans have an intuitive ability to understand their motivations and values. So the human is a complex entity that seems simple to other humans.
Reflexive and Reflective Intelligence
Another distinction I find helpful when thinking about intelligence is the difference between reflexive actions and reflective actions. We are much more aware of our reflections, but most actions we take are reflexive. And this can lead to an underestimate of the importance of our reflexive actions.
\[\text{reflect} \Longleftrightarrow \text{reflex}\]
It is our reflective capabilities that distinguish us from so many lower forms of intelligence. And it is also in reflective thinking that we can contextualise and justify our actions.
Reflective actions require longer timescales to deploy, often when we are in the moment it is the reflexive thinking that takes over. Naturally our biases about the world can enter in either our reflective or reflexive thinking, but biases associated with reflexive thinking are likely to be those we are unaware of.
This interaction between reflexive and reflective, where our reflective-self can place us within a wider cultural context, would seem key to better human decision making. If the reflexive-self can learn from the reflective-self to make better decisions, or if we have mechanisms of doubt that allow our reflective-self to intervene when our reflexive-decisions have consequences, then our reflexive thinking can be “lifted” to better reflect the results of our actions.
\[\text{reflect} \Longleftrightarrow \text{reflex}\]
Simplistic interpretations of utility theory are misleading about the real decisions we face, and similarly for the machines we design. These simplistic perspctives have also led to a tendency to seek proxies for a notion of “correct” decision making such as consistency. However, in practice uncertainty means that our decisions will often be incorrect. Faced with this incorrectness. Once we accept errors will be made, we can see that making consistent errors is likely to be more harmful than when those errors are inconsistent.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com