
Data Trust Pilots unveiled!
The Data Trusts Initiative is pleased to introduce our first cohort of data trust pioneers who will be leading the creation of real-world data trusts in 2022.
27 February 2023
27 February 2023
Our group has recently released a new paper surveying deployed ML systems for their compliance with the principles of Data-Oriented Architecture. Here we wanted to give a more informal summary of this paper, explain why we think DOA is particularly relevant to the AutoAI project, detail our findings, and showcase a few examples of real-life DOA systems.

The world around us becomes ever more data driven. Companies integrate AI into their products, university departments start research groups and courses focussed on ML, some ML models even become media sensations. It is important to realise though that these models could not exist without good quality data. This argument is in the center of a Data-centric AI initiative (DCAI) that came to prominence in 2021. DCAI advocates for prioritising high quality data and argues that efforts put into improving your datasets can pay off much better than equal efforts put into improving your models.
While there can be no doubt data quality is important, we believe there is another angle to data-centricity that is often overlooked. And that angle is the software systems that store, process and transform the data. As it turns out, carefully crafted data cleaning process is not worth much if the data that goes into it cannot be easily found and collected. And data management in modern software systems is a big problem, one of the major obstacles for rapid adoption of ML in industry. Modern software engineering practices, perfected by generations of engineers building big and small solutions often hinge on data encapsulation - hinding the data behind interfaces, making it secondary to the business logic. And while admittedly these practices advanced the software engineering field quite far, they might not be well equipped to answer the demans of data-driven era. The very idea of hiding data and restricting access to it is orthogonal to the demands of data-driven era around us. Data becomes difficult to find, to collect and to manage almost by design. This turns work of data scientists in industry into nightmare, as any data science related project in a reasonably sized software company starts with months of searching for bits of data throughout organization.
Data-Oriented Architecture (DOA) is an emerging paradigm that addresses precisely this problem. DOA proposes a set of high level principles that serve as general guidance for software engineers that want to build systems where data is highly available, discoverable and verifiable by design, while not sacrificing performance, cost or operational maintenance overhead. The whitepaper released by Rajive Joshi in 2007 explains this high level concept excellently, as well as discusses architectural patterns that can be used to achieve DOA in practice. Since this seminal paper was published a few more works came along, discussing general DOA-like principles or proposing concrete implementations in the field. But in general the works that explicitly claim following DOA principles are rare and far between.
This observation led us to the following idea: perhaps DOA is being adopted implicitly? Since it offers clear benefits for data-driven systems, it might have been implicitly embedded into many existing system designs. If proven true, this would show how widely DOA is adopted, but can also yield practical advice with illustrating how engineers achieved DOA-like properties. We set out to research this question. But before presenting our results it is important to discuss DOA principles themselves.
By studying existing works on DOA we were able to distil three major principles that form the basis of the paradigm.
Data as a First Class Citizen. DOA proposes to treat the data as a first class citizen, understanding data as the common denominator between components. This can be achieved by using data coupling between the components which results in an emergent shared data model. This principle makes systems data-driven by design.
Prioritise Decentralisation DOA suggests that data-driven system components should be deployed as decentralised entities that store data chunks of the shared information model. These entities perform locally, communicating with closest peers if necessary and using central servers as a fallback mechanism. Decentralisation creates a flexible ecosystem where resources from different devices can be used on-demand.
Openness. DOA proposes openness as a principle that data-driven systems should follow. Systems components should be independent, asynchronous and communicate with each other using a data exchange protocol. This principle creates open environments where the system’s components interact autonomously.
Together these principles result in a powerful paradigm that, at least in theory, should be able to address most of the challenges of ML deployment. Here is a diagram that shows a mapping between common challenge in the ML deployment workflow and the corresponding DOA principles.
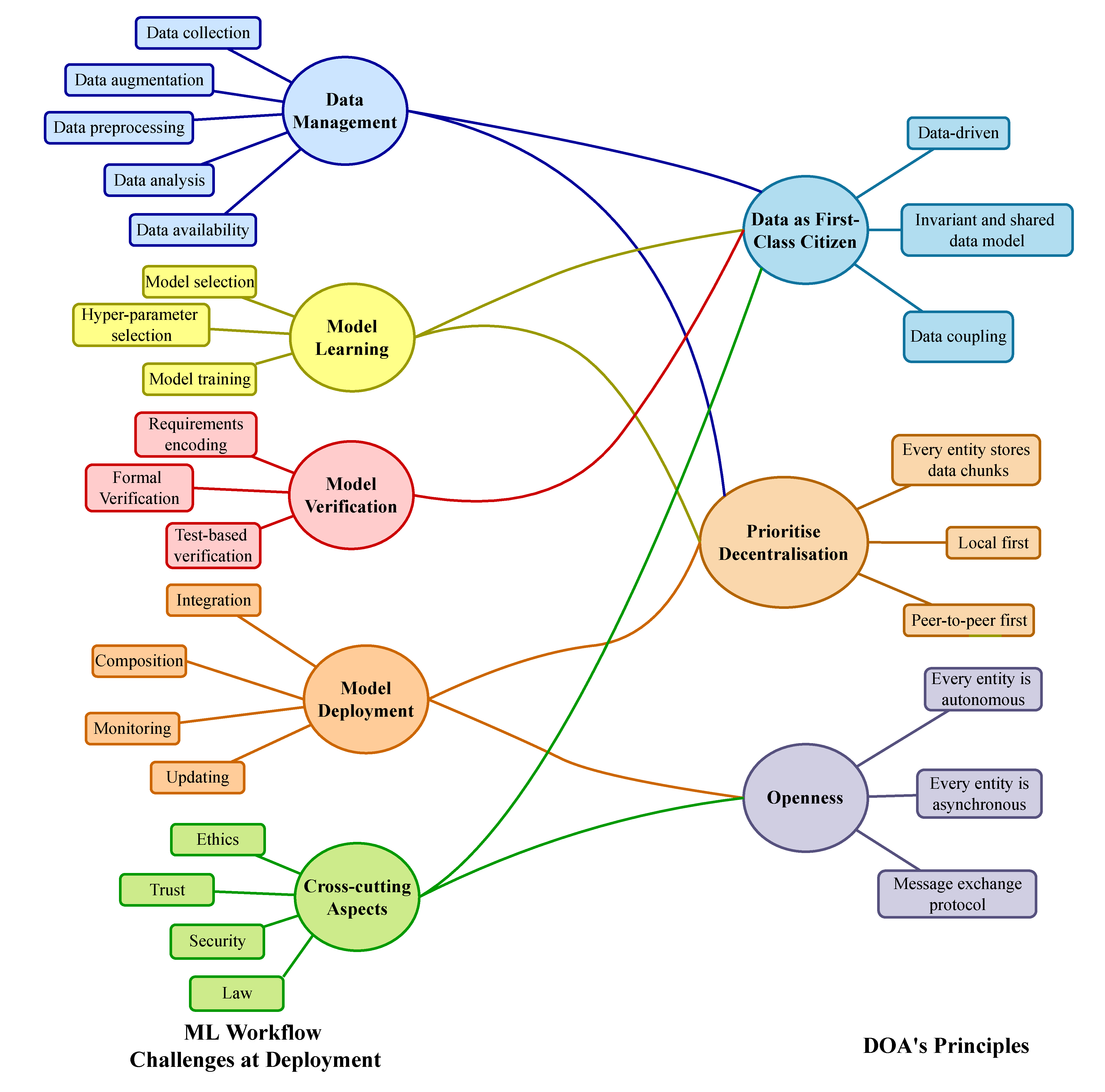
Armed with the understanding of general DOA principles we set to work investigating existing publications that describe deployed data-driven systems. The fact that the system was actually deployed and used in production was of paramount importance to us, as deployment processes often present engineers with unexpected problems, and put the quality of the system’s design through serious tests. After multiple iterations of searching and filtering we selected 46 papers to study in detail and report on. Interested readers can find all the details of our selection process, as well as quantitative results of our survey in the paper. Here we just discuss some general observations.
We found several systems that fully adopt the DOA principles, even if their authors do not refer to the paradigm. These systems had common requirements regarding big data management, real-time processing, and flexibility. Implicit adoption of DOA allowed the requirements to be satisfied.
Unsurprisingly we found the “Data as a First Class Citizen” principle to be widely adopted. A characteristic feature of systems that exhibit this principle is their use of distributed storage technologies, such as Apache Kafka, Spark Streaming, HDFS, or HBase. We therefore recommend practitioners to consider using similar data mediums as a primary interaction mechanism for components of their software.
The majority of reviewed systems show strong preference for centralisation. Further research of fully distributed technologies, such as Edge and Fog computing, is necessary to make decentralisation a feasible option. Nevertheless at least third of reviewed papers displayed some of the qualities associated with decentralisation as understood by DOA. We recommend considering distributed computing protocols, such as DHTs and BFT, for building fully decentralised data processing systems.
Systems that collect data from data-generating components, such as sensors, are usually open. Outside of data ingestion layers architectures tend to be more closed and static, although notable exceptions from this trend do occur. We observed a high correlation between data coupling and openness in the selected works. MQTT and similar communication protocols seem to be a popular choice for building open systems.
We have observed that systems that were built with such high-level architectures as dataflow and publish/subscribe turned out to be more data-oriented and followed more of the DOA principles. This is not surprising, as these patterns are described in terms of data exchange between components, and do not assume any coupling on control flow level. We thus recommend adoption of dataflow or publish/subscribe architectures for designing DOA systems.
To augment the vision of DOA principles and their practical implications, we now present two projects from our group that follow the DOA principles.
In 2022 our group started a collaboration with London-based MLOps startup Seldon who provide scalable ML inference infrastructure to their customers. Together we designed and built the second iteration of their open source ML deployment framework, Seldon Core (SCv2). Even though Seldon’s main focus is on ML inference, SCv2 can be seen as a general purpose dataflow engine with a particular focus on data centricity.
SCv2 fully adopts DOA principles. Inference graph in SCv2 is represented as decoupled components running on Docker containers that communicate via Apache Kafka topics. The evaluation process is fully decentralised, and the messages are exchanged in an industry-wide standardised protocol for ML inference, V2 Inference Protocol.
You can watch the launch announcement of SCv2 here, check out the docs and play with the code.
The Climate Ensembling project in our group aims to leverage multiple climate simulation models to improve our ability to predict rare and extreme climate-related events. Optimal selection of GCM post-processing and ensemble methods for a specific climate risk prediction application requires multiple data-intensive experiments. To support this project we are building a set of libraries, referred to as Hypervisor, that can orchestrate these experiments in a data oriented way.
Tasks that form the experiment pipeline are completely decoupled and only interact via input and output data that is stored in AWS S3 buckets. The system defines its own protocol for users to specify the tasks, which are nonetheless orchestrated in a centralized manner. Therefore the Hypervisor partially follows DOA principles.
The Hypervisor code can be found in this repository, and its application to the climate ensembling project is here.
Despite being relatively unknown, DOA contains a set of principles that can be of particular use to anyone looking to build a data-driven software application. As such, many existing ML systems have already adopted some of the DOA principles implicitly. Nevertheless, the development of DOA as a paradigm for software development is far from over. Further research efforts from the community can help advance our understanding of DOA advantages and drawbacks, as well as enable new exciting directions for systems, artificial intelligence and beyond. Some of the research directions we hope to tackle are described in our strategic research agenda.
If you would like to read the full survey paper on DOA described here, it can be found on arXiv: “Real-world Machine Learning Systems: A survey from a Data-Oriented Architecture Perspective”.

15 February 2022
The Data Trusts Initiative is pleased to introduce our first cohort of data trust pioneers who will be leading the creation of real-world data trusts in 2022.

17 May 2022
The AutoAI team will present new research on flow-based programming in the context of machine learning deployment at the first International Conference on AI Engineering.