
Week 3: Objective Functions: A Simple Example with Matrix Factorisation
[Powerpoint][jupyter][google colab][reveal]
Abstract:
In this session we introduce the notion of objective functions and show how they can be used in a simple recommender system based on matrix factorisation.
Setup
notutils
This small package is a helper package for various notebook utilities used below.
The software can be installed using
%pip install notutilsfrom the command prompt where you can access your python installation.
The code is also available on GitHub: https://github.com/lawrennd/notutils
Once notutils is installed, it can be imported in the
usual manner.
import notutilspods
In Sheffield we created a suite of software tools for ‘Open Data Science’. Open data science is an approach to sharing code, models and data that should make it easier for companies, health professionals and scientists to gain access to data science techniques.
You can also check this blog post on Open Data Science.
The software can be installed using
%pip install podsfrom the command prompt where you can access your python installation.
The code is also available on GitHub: https://github.com/lawrennd/ods
Once pods is installed, it can be imported in the usual
manner.
import podsmlai
The mlai software is a suite of helper functions for
teaching and demonstrating machine learning algorithms. It was first
used in the Machine Learning and Adaptive Intelligence course in
Sheffield in 2013.
The software can be installed using
%pip install mlaifrom the command prompt where you can access your python installation.
The code is also available on GitHub: https://github.com/lawrennd/mlai
Once mlai is installed, it can be imported in the usual
manner.
import mlaifor loss functions.
Further Reading
- Section 1.1.3 of Rogers and Girolami (2011)
In we saw how we could load in a data set to pandas and use it for some simple data processing. We computed variaous probabilities on the data and I encouraged you to think about what sort of probabilities you need for prediction. This week we are going to take a slightly different tack.
Broadly speaking there are two dominating approaches to machine learning problems. We started to consider the first approach last week: constructing models based on defining the relationship between variables using probabilities. This week we will consider the second approach: which involves defining an objective function and optimizing it. What do we mean by an objective function? An objective function could be an error function a cost function or a benefit function. In evolutionary computing they are called fitness functions. But the idea is always the same. We write down a mathematical equation which is then optimized to do the learning. The equation should be a function of the data and our model parameters. We have a choice when optimizing, either minimize or maximize. To avoid confusion, in the optimization field, we always choose to minimize the function. If we have function that we would like to maximize, we simply choose to minimize the negative of that function.
So for this lab session, we are going to ignore probabilities, but don’t worry, they will return!
This week we are going to try and build a simple movie recommender system using an objective function. To do this, the first thing I’d like you to do is to install some software we’ve written for sharing information across google documents.
Movie Body Count Example
There is a crisis in the movie industry, deaths are occuring on a massive scale. In every feature film the body count is tolling up. But what is the cause of all these deaths? Let’s try and investigate.
For our first example of data science, we take inspiration from work by researchers at NJIT. They researchers were comparing the qualities of Python with R (my brief thoughts on the subject are available in a Google+ post here: https://plus.google.com/116220678599902155344/posts/5iKyqcrNN68). They put together a data base of results from the the “Internet Movie Database” and the Movie Body Count website which will allow us to do some preliminary investigation.
We will make use of data that has already been ‘scraped’ from the Movie Body Count website. Code and the data is available at a github repository. Git is a version control system and github is a website that hosts code that can be accessed through git. By sharing the code publicly through github, the authors are licensing the code publicly and allowing you to access and edit it. As well as accessing the code via github you can also download the zip file.
For ease of use we’ve packaged this data set in the pods
library
data = pods.datasets.movie_body_count()['Y']
data.head()Once it is loaded in the data can be summarized using the
describe method in pandas.
data.describe()In jupyter and jupyter notebook it is possible to see a list of all
possible functions and attributes by typing the name of the object
followed by .<Tab> for example in the above case if
we type data.<Tab> it show the columns available
(these are attributes in pandas dataframes) such as
Body_Count, and also functions, such as .describe().
For functions we can also see the documentation about the function by following the name with a question mark. This will open a box with documentation at the bottom which can be closed with the x button.
data.describe?The film deaths data is stored in an object known as a ‘data frame’.
Data frames come from the statistical family of programming languages
based on S, the most widely used of which is R.
The data frame gives us a convenient object for manipulating data. The
describe method summarizes which columns there are in the data frame and
gives us counts, means, standard deviations and percentiles for the
values in those columns. To access a column directly we can write
print(data['Year'])
#print(data['Body_Count'])This shows the number of deaths per film across the years. We can plot the data as follows.
# this ensures the plot appears in the web browser
%matplotlib inline
import matplotlib.pyplot as plt # this imports the plotting library in pythonplt.plot(data['Year'], data['Body_Count'], 'rx')You may be curious what the arguments we give to
plt.plot are for, now is the perfect time to look at the
documentation
plt.plot?We immediately note that some films have a lot of deaths, which prevent us seeing the detail of the main body of films. First lets identify the films with the most deaths.
data[data['Body_Count']>200]Here we are using the command data['Kill_Count']>200
to index the films in the pandas data frame which have over 200 deaths.
To sort them in order we can also use the sort command. The
result of this command on its own is a data series of True
and False values. However, when it is passed to the
data data frame it returns a new data frame which contains
only those values for which the data series is True. We can
also sort the result. To sort the result by the values in the
Kill_Count column in descending order we use the
following command.
data[data['Body_Count']>200].sort_values(by='Body_Count', ascending=False)We now see that the ‘Lord of the Rings’ is a large outlier with a very large number of kills. We can try and determine how much of an outlier by histograming the data.
Plotting the Data
data['Body_Count'].hist(bins=20) # histogram the data with 20 bins.
plt.title('Histogram of Film Kill Count')Exercise 1
Read on the internet about the following python libraries:
numpy, matplotlib, scipy and
pandas. What functionality does each provide python. What
is the pylab library and how does it relate to the other
libraries?
We could try and remove these outliers, but another approach would be plot the logarithm of the counts against the year.
plt.plot(data['Year'], data['Body_Count'], 'rx')
ax = plt.gca() # obtain a handle to the current axis
ax.set_yscale('log') # use a logarithmic death scale
# give the plot some titles and labels
plt.title('Film Deaths against Year')
plt.ylabel('deaths')
plt.xlabel('year')Note a few things. We are interacting with our data. In particular, we are replotting the data according to what we have learned so far. We are using the progamming language as a scripting language to give the computer one command or another, and then the next command we enter is dependent on the result of the previous. This is a very different paradigm to classical software engineering. In classical software engineering we normally write many lines of code (entire object classes or functions) before compiling the code and running it. Our approach is more similar to the approach we take whilst debugging. Historically, researchers interacted with data using a console. A command line window which allowed command entry. The notebook format we are using is slightly different. Each of the code entry boxes acts like a separate console window. We can move up and down the notebook and run each part in a different order. The state of the program is always as we left it after running the previous part.
Exercise 2
Data ethics. If you find data available on the internet, can you simply use it without consequence? If you are given data by a fellow researcher can you publish that data on line?
Recommender Systems
A recommender system aims to make suggestions for items (films, books, other commercial products) given what it knows about users’ tastes. The recommendation engine needs to represent the taste of all the users and the characteristics of each object.
A common way for organizing objects is to place related objects spatially close together. For example in a library we try and put books that are on related topics near to each other on the shelves. One system for doing this is known as Dewey Decimal Classification. In the Dewey Decimal Classification system (which dates from 1876) each subject is given a number (in fact it’s a decimal number). For example, the field of Natural Sciences and Mathematics is given numbers which start with 500. Subjects based on Computer Science are given numbers which start 004 and works on the ‘mathematical principles’ of Computer science are given the series 004.0151 (which we might store as 4.0151 on a Computer). Whilst it’s a classification system, the books in the library are typically laid out in the same order as the numbers, so we might expect that neighbouring numbers represent books that are related in subject. That seems to be exactly what we want when also representing films. Could we somehow represent each film’s subject according to a number? In a similar way we could then imagine representing users with a list of numbers that represent things that each user is interested in.
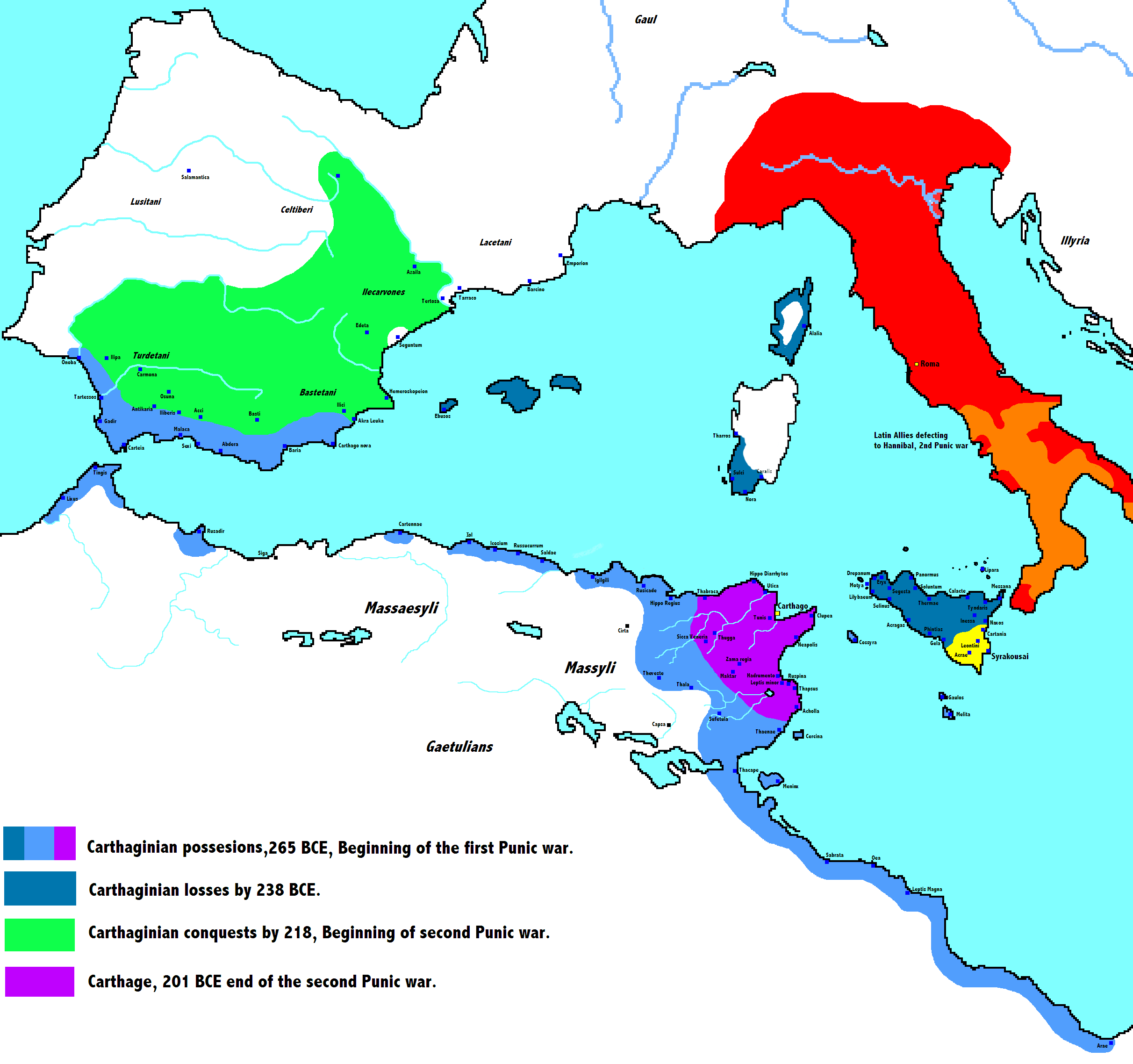
Actually a one dimensional representation of a subject can be very awkward. To see this, let’s have a look at the Dewey Decimal Classification numbers for the 900s, which is listed as ‘History and Geography’. We will focus on subjects in the 940s which can be found in this list from Nova Southeastern University. Whilst the ordering for places is somewhat sensible, it is also rather arbitrary. In the 940s we have Europe listed from 940-949, Asia listed from 950-959 and Africa listed from 960-969. Whilst it’s true that Asia borders Europe, Africa is also very close, and the history of the Roman Empire spreads into Carthage and later on Egypt. This image from Wikipedia shows a map of the Cathaginian Empire which fell after fighting with Rome.


Figure: The Carthaginian Empire at its peak.
We now need to make a decision about whether Roman Histories are European or African, ideally we’d like them to be somewhere between the two, but we can’t place them there in the Dewey Decimal system because between Europe and Africa is Asia, which has less to do with the Roman Empire than either Europe or Africa. Of course the fact that we’ve used a map provides a clue as to what to do next. Libraries are actually laid out on floors, so what if we were to use the spatial lay out to organise the sujbects of the books in two dimensions. Books on Geography could be laid out according to where in the world they are referring to.
Such complexities are very hard to encapsulate in one number, but inspired by the map examples we can start considering how we might lay out films in two dimensions. Similarly, we can consider laying out a map of people’s interests. If the two maps correspond to one another, the map of people could reflect where they might want to live in ‘subject space’. We can think of representing people’s tastes as where they might best like to sit in the library to access easily the books they are most interested in.
Inner Products for Representing Similarity
Ideas like the above are good for gaining intuitions about what we might want, but the one of the skills of data science is representing those ideas mathematically. Mathematical abstraction of a problem is one of the key ways in which we’ve been able to progress as a society. Understanding planetary motions, as well as those of the smallest molecule (to quote Laplace’s Philosophical Essay on Probabilities) needed to be done mathematically. The right mathematical model in machine learning can be slightly more elusive, because constructing it is a two stage process.
We have to determine the right intuition for the system we want to represent. Notions such as ‘subject’ and ‘interest’ are not mathematically well defined, and even when we create a new interpretation of what they might mean, each interpretation may have its own weaknesses.
Once we have our interpretation we can attempt to mathematically formalize it. In our library interpretation, that’s what we need to do next.
The Library on an Infinite Plane
Let’s imagine a library which stores all the items we are interested in, not just books, but films and shopping items too. Such a library is likely to be very large, so we’ll create it on an infinite two dimensional plane. This means we can use all the real numbers to represent the location of each item on the plane. For a two dimensional plane, we need to store the locations in a vector of numbers: we can decide that the \(j\)th item’s location in the library is given by \[ \mathbf{v}_j = \begin{bmatrix} v_{j,1} \\ v_{j,2}\end{bmatrix}, \] where \(v_{j,1}\) represents the \(j\)th item’s location in the East-West direction (or the \(x\)-axis) and \(v_{j,2}\) represents the \(j\)th item’s location in the North-South direction (or the \(y\)-axis). Now we need to specify the location where each user sits so that all the items that interest them are nearby: we can also represent the \(i\)th user’s location with a vector \[ \mathbf{u}_i = \begin{bmatrix} u_{i,1} \\ u_{i,2}\end{bmatrix}. \] Finally, we need some way of recording a given user’s affinity for a given item. This affinity might be the rating that the user gives the film. We can use \(y_{i,j}\) to represent user \(i\)’s affinity for item \(j\).
For our film example we might imagine wanting to order films in a few ways. We could imagine organising films in the North-South direction as to how romantic they are. We could place the more romantic films further North and the less romantic films further South. For the East-West direction we could imagine ordering them according to how historic they are: we can imagine placing science fiction films to the East and historical drama to the West. In this case, fans of historical romances would be based in the North-West location, whilst fans of Science Fiction Action films might be located in the South-East (if we assume that ‘Action’ is the opposite of ‘Romance’, which is not necessarily the case). How do we lay out all these films? Have we got the right axes? In machine learning the answer is to ‘let the data speak’. Use the data to try and obtain such a lay out. To do this we first need to obtain the data.
Obtaining the Data
We are using a functionality of the Open Data Science software library to obtain the data. This functionality involves some prewritten code which distributes to each of you a google spreadsheet where you can rate movies that you’ve seen. For completeness the code follows. Try and read and understand the code, but don’t run it! It has already been run centrally by me.
import pods
import pandas as pd
import numpy as np
user_data = pd.DataFrame(index=movies.index, columns=['title', 'year', 'rating', 'prediction'])
user_data['title']=movies.Film
user_data['year']=movies.Year
accumulator=pods.lab.distributor(spreadsheet_title='COM4509/6509 Movie Ratings:', user_sep='\t')
# function to apply to data before giving it to user
# Select 50 movies at random and order them according to year.
max_movies = 50
function = lambda x: x.loc[np.random.permutation(x.index)[:max_movies]].sort(columns='year')
accumulator.write(data_frame=user_data, comment='Film Ratings',
function=function)
accumulator.write_comment('Rate Movie Here (score 1-5)', row=1, column=4)
accumulator.share(share_type='writer', send_notifications=True)In your Google drive account you should be able to find a spreadsheet called ‘COM4509/6509 Movie Ratings: Your Name’. In the spreadsheet You should find a number of movies listed according to year. In the column titled ‘rating’ please place your rating using a score of 1-5 for any of the movies you’ve seen from the list.
Once you have placed your ratings we can download the data from your spreadsheets to a central file where the ratings of the whole class can be stored. We will build an algorithm on these ratings and use them to make predictions for the rest of the class. Firstly, here’s the code for reading the ratings from each of the spreadsheets.
import numpy as np
import pandas as pd
import os
accumulator = pods.lab.distributor(user_sep='\t')
data = accumulator.read(usecols=['rating'], dtype={'index':int, 'rating':np.float64}, header=2)
for user in data:
if data[user].rating.count()>0: # only add user if they rated something
# add a new field to movies with that user's ratings.
movies[user] = data[user]['rating']
# Store the csv on disk where it will be shared through dropbox.
movies.to_csv(os.path.join(pods.lab.class_dir,'movies.csv'), skiprows=1, index_label='ResponseID')Now we will convert our data structure into a form that is
appropriate for processing. We will convert the movies
object into a data base which contains the movie, the user and the score
using the following command.
import pandas as pd
import os# uncomment the line below if you are doing this task by self study.
pods.access.download_url('https://raw.githubusercontent.com/lawrennd/datasets_mirror/main/movie_recommender/movies.csv', store_directory = 'class_movie', save_name='movies.csv')
#pods.access.download_url('https://www.dropbox.com/s/s6gqvp9b383b59y/movies.csv?dl=0&raw=1', store_directory = 'class_movie', save_name='movies.csv')
movies = pd.read_csv(os.path.join('class_movie', 'movies.csv'),encoding='latin-1').set_index('index')Exercise 3
The movies data is now in a data frame which contains one column for
each user rating the movie. There are some entries that contain
NaN. What does the NaN mean in this
context?
Processing the Data
We will now prepare the data set for processing. To do this we are
going to conver the data into a new format using the melt
command.
user_names = list(set(movies.columns)-set(movies.columns[:9]))
Y = pd.melt(movies.reset_index(), id_vars=['Film', 'index'],
var_name='user', value_name='rating',
value_vars=user_names)
Y = Y.dropna(axis=0)What is a
pivot table? What does the pandas command
pd.melt do?
Measuring Similarity
We now need a measure for determining the similarity between the item and the user: how close the user is sitting to the item in the rooom if you like. We are going to use the inner product between the vector representing the item and the vector representing the user.
An inner product (or dot product) between two vectors \(\mathbf{a}\) and \(\mathbf{b}\) is written as \(\mathbf{a}\cdot\mathbf{b}\). Or in vector notation we sometimes write it as \(\mathbf{a}^\top\mathbf{b}\). An inner product is simply the sume of the products of each element of the vector, \[ \mathbf{a}^\top\mathbf{b} = \sum_{i} a_i b_i \] The inner product can be seen as a measure of similarity. The inner product gives us the cosine of the angle between the two vectors multiplied by their length. The smaller the angle between two vectors the larger the inner product. \[ \mathbf{a}^\top\mathbf{b} = |\mathbf{a}||\mathbf{b}| \cos(\theta) \] where \(\theta\) is the angle between two vectors and \(|\mathbf{a}|\) and \(|\mathbf{b}|\) are the respective lengths of the two vectors.
Since we want each user to be sitting near each item, then we want the inner product to be large for any two items which are rated highly by that user. We can do this by trying to force the inner product \(\mathbf{u}_i^\top\mathbf{v}_j\) to be similar to the rating given by the user, \(y_{i,j}\). To ensure this we will use a least squares objective function for all user ratings.
Objective Function
The error function (or objective function, or cost function) we will choose is known as ‘sum of squares’, we will aim to minimize the sum of squared squared error between the inner product of \(\mathbf{u}_i\) and \(\mathbf{v}_i\) and the observed score for the user/item pairing, given by \(y_{i, j}\).
The total objective function can be written as \[ E(\mathbf{U}, \mathbf{V}) = \sum_{i,j} s_{i,j} (y_{i,j} - \mathbf{u}_i^\top \mathbf{v}_j)^2 \] where \(s_{i,j}\) is an indicator variable that is 1 if user \(i\) has rated item \(j\) and is zero otherwise. Here \(\mathbf{U}\) is the matrix made up of all the vectors \(\mathbf{u}\), \[ \mathbf{U} = \begin{bmatrix} \mathbf{u}_1 \dots \mathbf{u}_n\end{bmatrix}^\top \] where we note that \(i\)th row of \(\mathbf{U}\) contains the vector associated with the \(i\)th user and \(n\) is the total number of users. This form of matrix is known as a design matrix. Similarly, we define the matrix \[ \mathbf{V} = \begin{bmatrix} \mathbf{v}_1 \dots \mathbf{v}_m\end{bmatrix}^\top \] where again the \(j\)th row of \(\mathbf{V}\) contains the vector associated with the \(j\)th item and \(m\) is the total number of items in the data set.
Objective Optimization
The idea is to mimimize this objective. A standard, simple, technique for minimizing an objective is gradient descent or steepest descent. In gradient descent we simply choose to update each parameter in the model by subtracting a multiple of the objective function’s gradient with respect to the parameters. So for a parameter \(u_{i,j}\) from the matrix \(\mathbf{U}\) we would have an update as follows: \[ u_{k,\ell} \leftarrow u_{k,\ell} - \eta \frac{\text{d} E(\mathbf{U}, \mathbf{V})}{\text{d}u_{k,\ell}} \] where \(\eta\) (which is pronounced eta in English) is a Greek letter representing the learning rate.
We can compute the gradient of the objective function with respect to \(u_{k,\ell}\) as \[ \frac{\text{d}E(\mathbf{U}, \mathbf{V})}{\text{d}u_{k,\ell}} = -2 \sum_j s_{k,j}v_{j,\ell}(y_{k, j} - \mathbf{u}_k^\top\mathbf{v}_{j}). \] Similarly each parameter \(v_{i,j}\) needs to be updated according to its gradient.
Exercise 4
What is the gradient of the objective function with respect to \(v_{k, \ell}\)? Write your answer in the box below, and explain which differentiation techniques you used to get there. You will be expected to justify your answer in class by oral questioning. Create a function for computing this gradient that is used in the algorithm below.
Steepest Descent Algorithm
In the steepest descent algorithm we aim to minimize the objective function by subtacting the gradient of the objective function from the parameters.
Initialisation
To start with though, we need initial values for the matrix \(\mathbf{U}\) and the matrix \(\mathbf{V}\). Let’s create them as
pandas data frames and initialise them randomly with small
values.
import numpy as npq = 2 # the dimension of our map of the 'library'
learn_rate = 0.01
U = pd.DataFrame(np.random.normal(size=(len(user_names), q))*0.001, index=user_names)
V = pd.DataFrame(np.random.normal(size=(len(movies.index), q))*0.001, index=movies.index)We also will subtract the mean from the rating before we try and predict them predictions. Have a think about why this might be a good idea (Hint: what will the gradients be if we don’t subtract the mean?).
Y['rating'] -= Y['rating'].mean()Now that we have the initial values set, we can start the optimization. First we define a function for the gradient of the objective and the objective function itself.
def objective_gradient(Y, U, V):
gU = pd.DataFrame(np.zeros((U.shape)), index=U.index)
gV = pd.DataFrame(np.zeros((V.shape)), index=V.index)
obj = 0.
for ind, series in Y.iterrows():
film = series['index']
user = series['user']
rating = series['rating']
prediction = np.dot(U.loc[user], V.loc[film]) # vTu
diff = prediction - rating # vTu - y
obj += diff*diff
gU.loc[user] += 2*diff*V.loc[film]
gV.loc[film] += 2*diff*U.loc[user]
return obj, gU, gVNow we can write our simple optimisation route. This allows us to observe the objective function as the optimization proceeds.
import sys
iterations = 100
for i in range(iterations):
obj, gU, gV = objective_gradient(Y, U, V)
print("Iteration", i, "Objective function: ", obj)
U -= learn_rate*gU
V -= learn_rate*gVExercise 5
What happens as you increase the number of iterations? What happens if you increase the learning rate?
Stochastic Gradient Descent or Robbins Monroe Algorithm
Stochastic gradient descent (Robbins and Monro, 1951) involves updating separating each gradient update according to each separate observation, rather than summing over them all. It is an approximate optimization method, but it has proven convergence under certain conditions and can be much faster in practice. It is used widely by internet companies for doing machine learning in practice. For example, Facebook’s ad ranking algorithm uses stochastic gradient descent.
Exercise 6
Create a stochastic gradient descent version of the algorithm. Monitor the objective function after every 1000 updates to ensure that it is decreasing. When you have finished, plot the movie map and the user map in two dimensions. Label the plots with the name of the movie or user.
Making Predictions
Predictions can be made from the model of the appropriate rating for a given user, \(i\), for a given film, \(j\), by simply taking the inner product between their vectors \(\mathbf{u}_i\) and \(\mathbf{v}_j\).
Is Our Map Enough? Are Our Data Enough?
Is two dimensions really enough to capture the complexity of humans and their artforms? Perhaps we need even more dimensions to capture that complexity. Extending our books analogy further, consider how we should place books that have a historical timeframe as well as some geographical location. Do we really want books from the 2nd World War to sit alongside books from the Roman Empire? Books on the American invasion of Sicily in 1943 are perhaps less related to books about Carthage than those that study the Jewish Revolt from 66-70 (in the Roman Province of Judaea). So books that relate to subjects which are closer in time should be stored together. However, a student of rebellion against empire may also be interested in the relationship between the Jewish Revolt of 66-70 and the Indian Rebellion of 1857, nearly 1800 years later. Whilst the technologies are different, the psychology of the people is shared: a rebellious nation angainst their imperial masters, triggered by misrule with a religious and cultural background. To capture such complexities we would need further dimensions in our latent representation. But are further dimensions justified by the amount of data we have? Can we really understand the facets of a film that only has at most three or four ratings?
Going Further
If you want to take this model further then you’ll need more data.
One possible source of data is the movielens
data set. They have data sets containing up to ten million movie
ratings. The few ratings we were able to collect in the class are not
enough to capture the rich structure underlying these films. Imagine if
we assume that the ratings are uniformly distributed between 1 and 5. If
you know something about information theory then you could use that to
work out the maximum number of bits of information we could
gain per rating.
Now we’ll download the movielens 100k data and see if we can extract information about these movies.
import podsd = pods.datasets.movielens100k()
Y=d['Y']Exercise 7
Use stochastic gradient descent to make a movie map for the movielens data. Plot the map of the movies when you are finished.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com