
Week : Intent, Incentives, and the Data Crisis
[jupyter][google colab][reveal]
Abstract:
We reframe “data readiness” as an executive problem: intent and incentives, attention as the bottleneck, and how scaled optimisation creates System Zero risks. We keep DRLs, but treat them as instrumentation for decision quality, escalation, and accountability.
Intent, incentives, and the data crisis
Trust, Autonomy and Embodiment
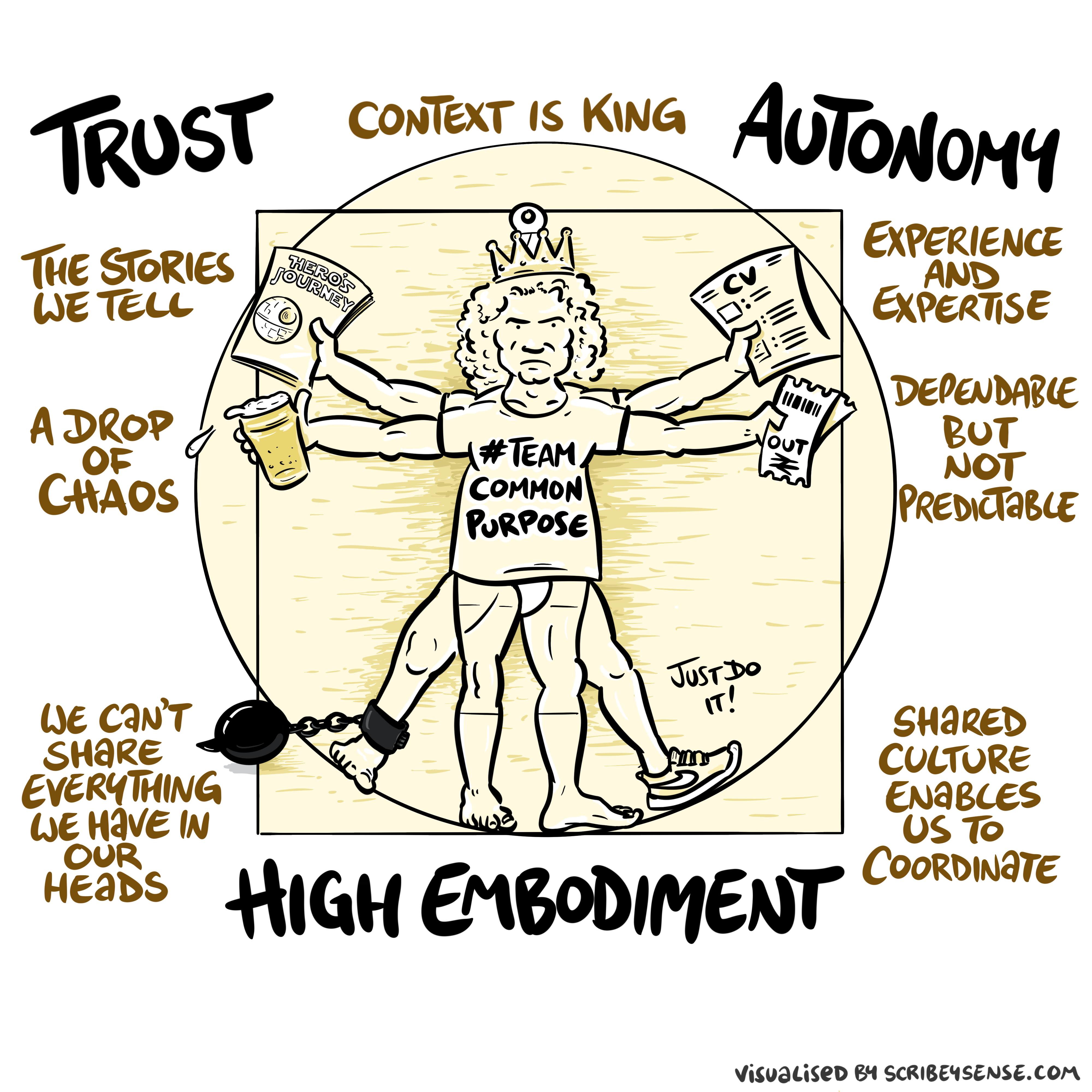

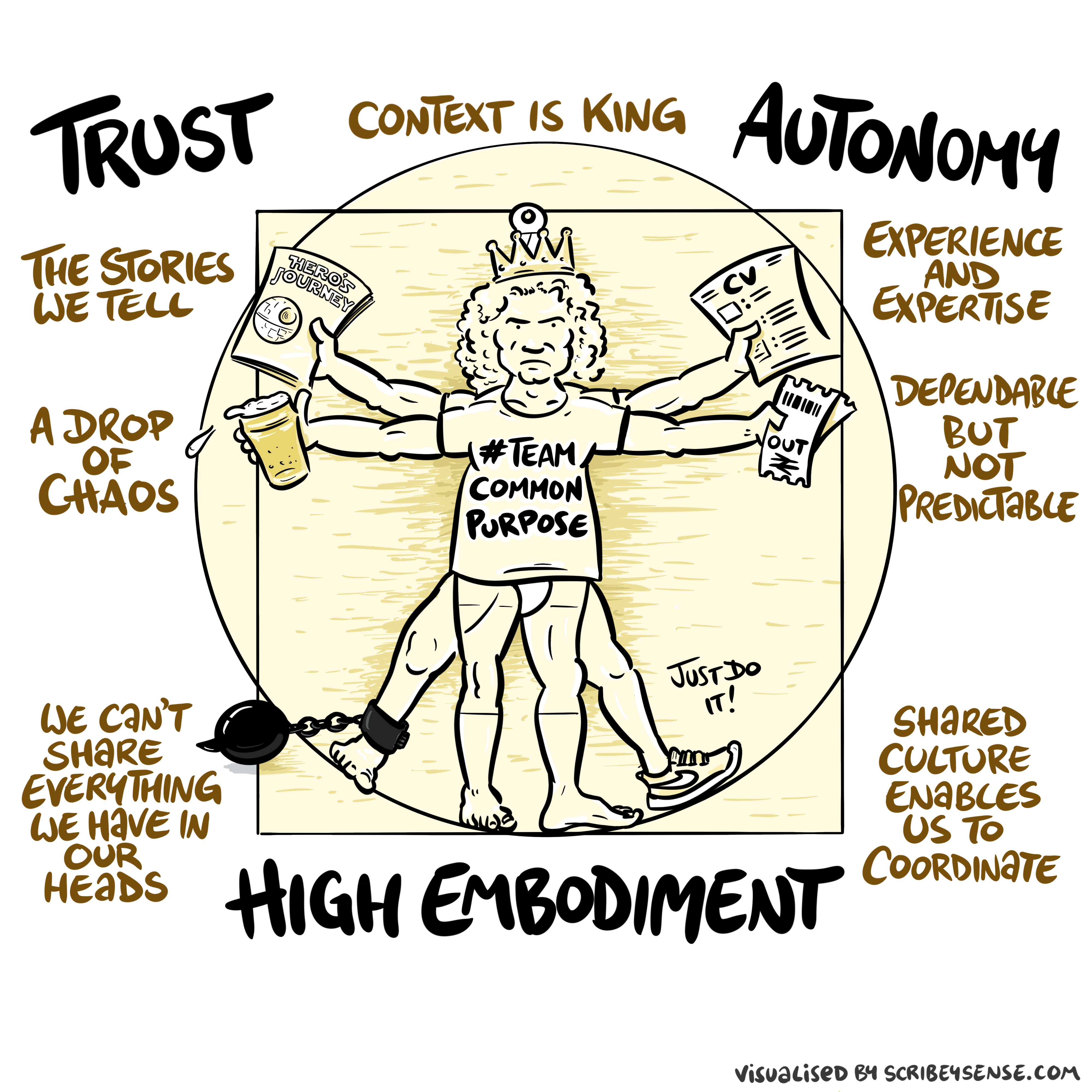
Figure: The relationships between trust, autonomy and embodiment are key to understanding how to properly deploy AI systems in a way that avoids digital autocracy. (Illustration by Dan Andrews inspired by Chapter 3 “Intent” of “The Atomic Human” Lawrence (2024))
This illustration was created by Dan Andrews after reading Chapter 3 “Intent” of “The Atomic Human” book. The chapter explores the concept of intent in AI systems and how trust, autonomy, and embodiment interact to shape our relationship with technology. Dan’s drawing captures these complex relationships and the balance needed for responsible AI deployment.
See blog post on Dan Andrews image from Chapter 3.
Trust is not a slogan; it is the infrastructure that allows autonomy to be devolved without losing control. Autonomy is always conditional: it depends on what information is available, what incentives shape behaviour, and whether escalation and accountability are real. In executive settings, the practical question is: where do we allow delegation (to people or machines), and where do we insist on human judgement and responsibility?
See Lawrence (2024) trust p. 43, 79, 100. See Lawrence (2024) embodiment factor p. 13, 29, 35, 79, 87, 105, 197, 216-217, 249, 269, 327, 353, 363, 369. See Lawrence (2024) topography, information p. 34-9, 43-8, 57, 62, 104, 115-16, 127, 140, 192, 196, 199, 291, 334, 354-5.
The key move in this session is to treat “data readiness” as an executive governance question. Data only matters because it changes decisions. Once decisions are automated or scaled, incentives and optimisation pressure reshape behaviour - and the failure modes stop looking like “bad data” and start looking like organisational blind spots.
See Lawrence (2024) objectives p. 29, 36, 83-4, 148, 149, 179. See Lawrence (2024) topography, information p. 34-9, 43-8, 57, 62, 104, 115-16, 127, 140, 192, 196, 199, 291, 334, 354-5.
The Attention Economy
Herbert Simon on Information
What information consumes is rather obvious: it consumes the attention of its recipients. Hence a wealth of information creates a poverty of attention …
Simon (1971)
The attention economy was a phenomenon described in 1971 by the American computer scientist Herbert Simon. He saw the coming information revolution and wrote that a wealth of information would create a poverty of attention. Too much information means that human attention becomes the scarce resource, the bottleneck. It becomes the gold in the attention economy.
The power associated with control of information dates back to the invention of writing. By pressing reeds into clay tablets Sumerian scribes stored information and controlled the flow of information.
These are incentive-shaped failures. If a metric becomes consequential, people (and systems) optimise against it. Once optimisation is legible, it can be gamed. And once many organisations adopt the same decision rule, small flaws become systemic. “The model said so” is not a control system: it’s a delegation without responsibility.
DRLs as instrumentation (not a checklist)
The Data Crisis
Anecdotally, talking to data modelling scientists. Most say they spend 80% of their time acquiring and cleaning data. This is precipitating what I refer to as the “data crisis”. This is an analogy with software. The “software crisis” was the phenomenon of inability to deliver software solutions due to increasing complexity of implementation. There was no single shot solution for the software crisis, it involved better practice (scrum, test orientated development, sprints, code review), improved programming paradigms (object orientated, functional) and better tools (CVS, then SVN, then git).
However, these challenges aren’t new, they are merely taking a different form. From the computer’s perspective software is data. The first wave of the data crisis was known as the software crisis.
The Software Crisis
In the late sixties early software programmers made note of the increasing costs of software development and termed the challenges associated with it as the “Software Crisis”. Edsger Dijkstra referred to the crisis in his 1972 Turing Award winner’s address.
The major cause of the software crisis is that the machines have become several orders of magnitude more powerful! To put it quite bluntly: as long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a mild problem, and now we have gigantic computers, programming has become an equally gigantic problem.
Edsger Dijkstra (1930-2002), The Humble Programmer
The major cause of the data crisis is that machines have become more interconnected than ever before. Data access is therefore cheap, but data quality is often poor. What we need is cheap high-quality data. That implies that we develop processes for improving and verifying data quality that are efficient.
There would seem to be two ways for improving efficiency. Firstly, we should not duplicate work. Secondly, where possible we should automate work.
What I term “The Data Crisis” is the modern equivalent of this problem. The quantity of modern data, and the lack of attention paid to data as it is initially “laid down” and the costs of data cleaning are bringing about a crisis in data-driven decision making. This crisis is at the core of the challenge of technical debt in machine learning (Sculley et al., 2015).
Just as with software, the crisis is most correctly addressed by ‘scaling’ the manner in which we process our data. Duplication of work occurs because the value of data cleaning is not correctly recognised in management decision making processes. Automation of work is increasingly possible through techniques in “artificial intelligence”, but this will also require better management of the data science pipeline so that data about data science (meta-data science) can be correctly assimilated and processed. The Alan Turing institute has a program focussed on this area, AI for Data Analytics.
Lies and Damned Lies
There are three types of lies: lies, damned lies and statistics
Arthur Balfour 1848-1930
Arthur Balfour was quoting the lawyer James Munro1 when he said that there three types of lies: lies, damned lies and statistics in 1892. This is 20 years before the first academic department of applied statistics was founded at UCL.
If Balfour were alive today, it is likely that he’d rephrase his quote:
There are three types of lies, lies damned lies and big data.
Why? Because the challenges of understanding and interpreting big data today are similar to those that Balfour (who was a Conservative politician and statesman and would later become Prime Minister) faced in governing an empire through statistics in the latter part of the 19th century.
The quote lies, damned lies and statistics was also credited to Benjamin Disraeli by Mark Twain in Twain’s autobiography.2 It characterizes the idea that statistic can be made to prove anything. But Disraeli died in 1881 and Mark Twain died in 1910. The important breakthrough in overcoming our tendency to over-interpet data came with the formalization of the field through the development of mathematical statistics.
Data has an elusive quality, it promises so much but can deliver little, it can mislead and misrepresent. To harness it, it must be tamed. In Balfour and Disraeli’s time during the second half of the 19th century, numbers and data were being accumulated, the social sciences were being developed. There was a large-scale collection of data for the purposes of government.
The modern ‘big data era’ is on the verge of delivering the same sense of frustration that Balfour experienced, the early promise of big data as a panacea is evolving to demands for delivery. For me, personally, peak-hype coincided with an email I received inviting collaboration on a project to deploy “Big Data and Internet of Things in an Industry 4.0 environment”. Further questioning revealed that the actual project was optimization of the efficiency of a manufacturing production line, a far more tangible and realizable goal.
The antidote to this verbiage is found in increasing awareness. When dealing with data the first trap to avoid is the games of buzzword bingo that we are wont to play. The first goal is to quantify what challenges can be addressed and what techniques are required. Behind the hype fundamentals are changing. The phenomenon is about the increasing access we have to data. The way customers’ information is recorded and processes are codified and digitized with little overhead. Internet of things is about the increasing number of cheap sensors that can be easily interconnected through our modern network structures. But businesses are about making money, and these phenomena need to be recast in those terms before their value can be realized.
For more thoughts on the challenges that statistics brings see Chapter 8 of Lawrence (2024).
Mathematical Statistics
Karl Pearson (1857-1936), Ronald Fisher (1890-1962) and others considered the question of what conclusions can truly be drawn from data. Their mathematical studies act as a restraint on our tendency to over-interpret and see patterns where there are none. They introduced concepts such as randomized control trials that form a mainstay of our decision making today, from government, to clinicians to large scale A/B testing that determines the nature of the web interfaces we interact with on social media and shopping.

Figure: Karl Pearson (1857-1936), one of the founders of Mathematical Statistics.
Their movement did the most to put statistics to rights, to eradicate the ‘damned lies’. It was known as ‘mathematical statistics’. Today I believe we should look to the emerging field of data science to provide the same role. Data science is an amalgam of statistics, data mining, computer systems, databases, computation, machine learning and artificial intelligence. Spread across these fields are the tools we need to realize data’s potential. For many businesses this might be thought of as the challenge of ‘converting bits into atoms’. Bits: the data stored on computer, atoms: the physical manifestation of what we do; the transfer of goods, the delivery of service. From fungible to tangible. When solving a challenge through data there are a series of obstacles that need to be addressed.
Firstly, data awareness: what data you have and where its stored. Sometimes this includes changing your conception of what data is and how it can be obtained. From automated production lines to apps on employee smart phones. Often data is locked away: manual logbooks, confidential data, personal data. For increasing awareness an internal audit can help. The website data.gov.uk hosts data made available by the UK government. To create this website the government’s departments went through an audit of what data they each hold and what data they could make available. Similarly, within private businesses this type of audit could be useful for understanding their internal digital landscape: after all the key to any successful campaign is a good map.
Secondly, availability. How well are the data sources interconnected? How well curated are they? The curse of Disraeli was associated with unreliable data and unreliable statistics. The misrepresentations this leads to are worse than the absence of data as they give a false sense of confidence to decision making. Understanding how to avoid these pitfalls involves an improved sense of data and its value, one that needs to permeate the organization.
The final challenge is analysis, the accumulation of the necessary expertise to digest what the data tells us. Data requires interpretation, and interpretation requires experience. Analysis is providing a bottleneck due to a skill shortage, a skill shortage made more acute by the fact that, ideally, analysis should be carried out by individuals not only skilled in data science but also equipped with the domain knowledge to understand the implications in a given application, and to see opportunities for improvements in efficiency.
‘Mathematical Data Science’
As a term ‘big data’ promises much and delivers little, to get true value from data, it needs to be curated and evaluated. The three stages of awareness, availability and analysis provide a broad framework through which organizations should be assessing the potential in the data they hold. Hand waving about big data solutions will not do, it will only lead to self-deception. The castles we build on our data landscapes must be based on firm foundations, process and scientific analysis. If we do things right, those are the foundations that will be provided by the new field of data science.
Today the statement “There are three types of lies: lies, damned lies and ‘big data’” may be more apt. We are revisiting many of the mistakes made in interpreting data from the 19th century. Big data is laid down by happenstance, rather than actively collected with a particular question in mind. That means it needs to be treated with care when conclusions are being drawn. For data science to succeed it needs the same form of rigor that Pearson and Fisher brought to statistics, a “mathematical data science” is needed.
You can also check my blog post on Lies, Damned Lies and Big Data.
Quantifying the Value of Data
The situation is reminiscent of a thirsty castaway, set adrift. There is a sea of data, but it is not fit to drink. We need some form of data desalination before it can be consumed. But like real desalination, this is a non-trivial process, particularly if we want to achieve it at scale.
There’s a sea of data, but most of it is undrinkable.

Figure: The abundance of uncurated data is reminiscent of the abundance of undrinkable water for those cast adrift at sea.
We require data-desalination before it can be consumed!
I spoke about the challenges in data science at the NIPS 2016 Workshop on Machine Learning for Health. NIPS mainly focuses on machine learning methodologies, and many of the speakers were doing so. But before my talk, I listened to some of the other speakers talk about the challenges they had with data preparation.
- 90% of our time is spent on validation and integration (Leo Anthony Celi)
- “The Dirty Work We Don’t Want to Think About” (Eric Xing)
- “Voodoo to get it decompressed” (Francisco Giminez)
A further challenge in healthcare is that the data is collected by clinicians, often at great inconvenience to both themselves and the patient, but the control of the data is sometimes used to steer the direction of research.
The fact that we put so much effort into processing the data, but so little into allocating credit for this work is a major challenge for realizing the benefit in the data we have.
This type of work is somewhat thankless, with the exception of the clinicians’ control of the data, which probably takes things too far, those that collate and correct data sets gain little credit. In the domain of reinforcement learning the aim is to take a series of actions to achieve a stated goal and gain a reward. The credit assignment problem is the challenge in the learning algorithm of distributing credit to each of the actions which brought about the reward. We also experience this problem in society, we use proxies such as monetary reward to incentivise intermediate steps in our economy. Modern society functions because we agree to make basic expenditure on infrastructure, such as roads, which we all make use of. Our data-society is not sufficiently mature to be correctly crediting and rewarding those that undertake this work.
This situation is no better in industry than in academia. Many companies have been persuaded to accumulate all their data centrally in a so-called “data lake”. This attractive idea is problematic, because data is added to the “lake” without thought to its quality. As a result, a better name for these resources would be data swamps. Because the quality of data in them is often dubious. Data scientists when working with these sources often need to develop their own processes for checking the quality of the data before it is used. Unfortunately, the quality improvements they make are rarely fed back into the ecosystem, meaning the same purification work needs to be done repeatedly.
We need to properly incentivize the sharing and production of clean data sets, we need to correctly quantify the value in the contribution of each actor, otherwise there won’t be enough clean data to satiate the thirst of our decision-making processes.
Figure: Partially observable Markov decision process observing reward as actions are taken in different states
The value of shared data infrastructures in computational biology was recognized by the 2010 joint statement from the Wellcome Trust and other funders of research at the “Foggy Bottom” meeting. They recognised three key benefits to sharing of health data:
- faster progress in improving health
- better value for money
- higher quality science
But incentivising sharing requires incentivising collection and collation of data, and the associated credit allocation models.
Data Readiness Levels
Data Readiness Levels
Data Readiness Levels (Lawrence, 2017) are an attempt to develop a language around data quality that can bridge the gap between technical solutions and decision makers such as managers and project planners. They are inspired by Technology Readiness Levels which attempt to quantify the readiness of technologies for deployment.
See this blog post on Data Readiness Levels.
Three Grades of Data Readiness
Data-readiness describes, at its coarsest level, three separate stages of data graduation.
- Grade C - accessibility
- Transition: data becomes electronically available
- Grade B - validity
- Transition: pose a question to the data.
- Grade A - usability
The important definitions are at the transition. The move from Grade C data to Grade B data is delimited by the electronic availability of the data. The move from Grade B to Grade A data is delimited by posing a question or task to the data (Lawrence, 2017).
Accessibility: Grade C
The first grade refers to the accessibility of data. Most data science practitioners will be used to working with data-providers who, perhaps having had little experience of data-science before, state that they “have the data”. More often than not, they have not verified this. A convenient term for this is “Hearsay Data”, someone has heard that they have the data so they say they have it. This is the lowest grade of data readiness.
Progressing through Grade C involves ensuring that this data is accessible. Not just in terms of digital accessiblity, but also for regulatory, ethical and intellectual property reasons.
Validity: Grade B
Data transits from Grade C to Grade B once we can begin digital analysis on the computer. Once the challenges of access to the data have been resolved, we can make the data available either via API, or for direct loading into analysis software (such as Python, R, Matlab, Mathematica or SPSS). Once this has occured the data is at B4 level. Grade B involves the validity of the data. Does the data really represent what it purports to? There are challenges such as missing values, outliers, record duplication. Each of these needs to be investigated.
Grade B and C are important as if the work done in these grades is documented well, it can be reused in other projects. Reuse of this labour is key to reducing the costs of data-driven automated decision making. There is a strong overlap between the work required in this grade and the statistical field of exploratory data analysis (Tukey, 1977).
The need for Grade B emerges due to the fundamental change in the availability of data. Classically, the scientific question came first, and the data came later. This is still the approach in a randomized control trial, e.g. in A/B testing or clinical trials for drugs. Today data is being laid down by happenstance, and the question we wish to ask about the data often comes after the data has been created. The Grade B of data readiness ensures thought can be put into data quality before the question is defined. It is this work that is reusable across multiple teams. It is these processes that the team which is standing up the data must deliver.
Usability: Grade A
Once the validity of the data is determined, the data set can be considered for use in a particular task. This stage of data readiness is more akin to what machine learning scientists are used to doing in universities. Bringing an algorithm to bear on a well understood data set.
In Grade A we are concerned about the utility of the data given a particular task. Grade A may involve additional data collection (experimental design in statistics) to ensure that the task is fulfilled.
This is the stage where the data and the model are brought together, so expertise in learning algorithms and their application is key. Further ethical considerations, such as the fairness of the resulting predictions are required at this stage. At the end of this stage a prototype model is ready for deployment.
Deployment and maintenance of machine learning models in production is another important issue which Data Readiness Levels are only a part of the solution for.
Recursive Effects
To find out more, or to contribute ideas go to http://data-readiness.org
Throughout the data preparation pipeline, it is important to have close interaction between data scientists and application domain experts. Decisions on data preparation taken outside the context of application have dangerous downstream consequences. This provides an additional burden on the data scientist as they are required for each project, but it should also be seen as a learning and familiarization exercise for the domain expert. Long term, just as biologists have found it necessary to assimilate the skills of the bioinformatician to be effective in their science, most domains will also require a familiarity with the nature of data driven decision making and its application. Working closely with data-scientists on data preparation is one way to begin this sharing of best practice.
The processes involved in Grade C and B are often badly taught in courses on data science. Perhaps not due to a lack of interest in the areas, but maybe more due to a lack of access to real world examples where data quality is poor.
These stages of data science are also ridden with ambiguity. In the long term they could do with more formalization, and automation, but best practice needs to be understood by a wider community before that can happen.
Assessing the Organizations Readiness
Assessing the readiness of data for analysis is one action that can be taken, but assessing teams that need to assimilate the information in the data is the other side of the coin. With this in mind both Damon Civin and Nick Elprin have independently proposed the idea of a “Data Joel Test”. A “Joel Test” is a short questionnaire to establish the ability of a team to handle software engineering tasks. It is designed as a rough and ready capability assessment. A “Data Joel Test” is similar, but for assessing the capability of a team in performing data science.
Data Science as Debugging
One challenge for existing information technology professionals is realizing the extent to which a software ecosystem based on data differs from a classical ecosystem. In particular, by ingesting data we bring unknowns/uncontrollables into our decision-making system. This presents opportunity for adversarial exploitation and unforeseen operation.
blog post on Data Science as Debugging.
Starting with the analysis of a data set, the nature of data science is somewhat difference from classical software engineering.
One analogy I find helpful for understanding the depth of change we need is the following. Imagine as a software engineer, you find a USB stick on the ground. And for some reason you know that on that USB stick is a particular API call that will enable you to make a significant positive difference on a business problem. You don’t know which of the many library functions on the USB stick are the ones that will help. And it could be that some of those library functions will hinder, perhaps because they are just inappropriate or perhaps because they have been placed there maliciously. The most secure thing to do would be to not introduce this code into your production system at all. But what if your manager told you to do so, how would you go about incorporating this code base?
The answer is very carefully. You would have to engage in a process more akin to debugging than regular software engineering. As you understood the code base, for your work to be reproducible, you should be documenting it, not just what you discovered, but how you discovered it. In the end, you typically find a single API call that is the one that most benefits your system. But more thought has been placed into this line of code than any line of code you have written before.
An enormous amount of debugging would be required. As the nature of the code base is understood, software tests to verify it also need to be constructed. At the end of all your work, the lines of software you write to interact with the software on the USB stick are likely to be minimal. But more thought would be put into those lines than perhaps any other lines of code in the system.
Even then, when your API code is introduced into your production system, it needs to be deployed in an environment that monitors it. We cannot rely on an individual’s decision making to ensure the quality of all our systems. We need to create an environment that includes quality controls, checks, and bounds, tests, all designed to ensure that assumptions made about this foreign code base are remaining valid.
This situation is akin to what we are doing when we incorporate data in our production systems. When we are consuming data from others, we cannot assume that it has been produced in alignment with our goals for our own systems. Worst case, it may have been adversarially produced. A further challenge is that data is dynamic. So, in effect, the code on the USB stick is evolving over time.
It might see that this process is easy to formalize now, we simply need to check what the formal software engineering process is for debugging, because that is the current software engineering activity that data science is closest to. But when we look for a formalization of debugging, we find that there is none. Indeed, modern software engineering mainly focusses on ensuring that code is written without bugs in the first place.
Lessons
When you begin a data analysis approach it with the mindset of a debugger: write test code continuously as you go through your analysis, ensure that the tests are documented and accessible to those who need to review or build upon your work.
Take time to thouroughly understand the context of your data before diving in. Expore multiple approaches and continually revisit your initial assumptions. Maintain a healtky skepticism about your results through the process and proactively explore potential issues or inconsistencies in the data.
Leverage the best tools available and develop a deep understanding of how they work. Don’t just treat the tools as black boxes, develop your understanding of tehri strengths, limmitations and appropriate use. Share challenges you are facing and progress you are making with colleagues. Seek regular views from business stakholders, software engineers, fellow data scientists and managers. Bringing in their different perspectives can help identify potential issues early.
Don’t rush to implementing your end-solution. Just as you wouldn’t immediately write an API call for unknown code you’ve found on a discarded USB code, you shouldn’t jump straght into running complex classsification algorithms before gaining an intuition for your data through some basic visualisation and ohter tests. The documentation of the analysis process should be such that if issues do arise in production the documentation can be used to support tracing back to where the problems have originated and rapidly rectifying them.
Always remember that the data science process differs fundamentally from standard software development, so traditional agile development pipelines may not be appropriate. You have to adapt your processes to handle inherrent uncertainty and accomidate the iterative and recursive nature of data science work. Think carefully about how you will handle not just individual bugs but systematic issues that may emerge from your data.
Don’t work in isolation, the complexity of data work means that close collaboration with domain experts, software engineers and other data scientists is essention. The collaboration serves multiple purposes: it provides you with the necessary technical support, helps maintain realistic expectations among stakeholders in terms of both outcome and delivery time lines. And it ensures that the solutions developed actually address the underlying business problem.
Recommendation: Anecdotally, resolving a machine learning challenge requires 80% of the resource to be focused on the data and perhaps 20% to be focused on the model. But many companies are too keen to employ machine learning engineers who focus on the models, not the data. We should change our hiring priorities and training. Universities cannot provide the understanding of how to data-wrangle. Companies must fill this gap.
Use Access/Assess/Address as the vocabulary that makes DRLs actionable. It separates what can be made reusable (assess) from what must remain decision-specific (address). This is the executive-friendly version of “instrumentation”: it tells you what work reduces future cost, and what work must be governed tightly because it encodes intent.
System Zero and executive controls

Figure: This is the drawing Dan was inspired to create for Chapter 8. It captures the notion of Syztem Zero. The idea of System Zero is that the machine’s access to information is so much greater than ours that it can manipulate us in ways that exploit our cognitive foibles, interacting directly with our reflexive selves and undermining our reflective selves.
See blog post on A Retrospective on System Zero..
System Zero is when the machine’s access to our information is so much greater than ours it understands us in ways that we don’t understand each other.
System Zero is the reminder that influence can operate below conscious awareness: the system can steer behaviour without an explicit “decision point”. That’s why auditability, recourse, and escalation aren’t compliance theatre - they’re control surfaces.
See Lawrence (2024) System Zero p. 242-7, 306, 309, 329, 350, 355, 359, 361, 363, 364. See Lawrence (2024) Gas Light (play)/gaslighting p. 302-3. See Lawrence (2024) social media p. 15, 80, 81, 86, 108, 226, 243, 244, 245, 247, 359, 360, 362, 364.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- company: Trent AI
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com