
Week : The New World
Abstract:
This session introduces the challenges behind data, machine learning and artificial intelligence.
Evolved Relationship with Information
The high bandwidth of computers has resulted in a close relationship between the computer and data. Large amounts of information can flow between the two. The degree to which the computer is mediating our relationship with data means that we should consider it an intermediary.
Originally our low bandwidth relationship with data was affected by two characteristics. Firstly, our tendency to over-interpret driven by our need to extract as much knowledge from our low bandwidth information channel as possible. Secondly, by our improved understanding of the domain of mathematical statistics and how our cognitive biases can mislead us.
With this new set up there is a potential for assimilating far more information via the computer, but the computer can present this to us in various ways. If its motives are not aligned with ours then it can misrepresent the information. This needn’t be nefarious it can be simply because of the computer pursuing a different objective from us. For example, if the computer is aiming to maximize our interaction time that may be a different objective from ours which may be to summarize information in a representative manner in the shortest possible length of time.
For example, for me, it was a common experience to pick up my telephone with the intention of checking when my next appointment was, but to soon find myself distracted by another application on the phone and end up reading something on the internet. By the time I’d finished reading, I would often have forgotten the reason I picked up my phone in the first place.
There are great benefits to be had from the huge amount of information we can unlock from this evolved relationship between us and data. In biology, large scale data sharing has been driven by a revolution in genomic, transcriptomic and epigenomic measurement. The improved inferences that can be drawn through summarizing data by computer have fundamentally changed the nature of biological science, now this phenomenon is also influencing us in our daily lives as data measured by happenstance is increasingly used to characterize us.
Better mediation of this flow requires a better understanding of human-computer interaction. This in turn involves understanding our own intelligence better, what its cognitive biases are and how these might mislead us.
For further thoughts see Guardian article on marketing in the internet era from 2015.
You can also check my blog post on System Zero. This was also written in 2015.
New Flow of Information
Classically the field of statistics focused on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.

Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarize what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data but must also deal with the possibility that the machine has either inadvertently or maliciously misrepresented the underlying data.
Embodiment Factors
| bits/min | billions | 2,000 |
|
billion calculations/s |
~100 | a billion |
| embodiment | 20 minutes | 5 billion years |
Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, it is a matter of thousands of millions of years. See also “Living Together: Mind and Machine Intelligence” Lawrence (2017)
There is a fundamental limit placed on our intelligence based on our ability to communicate. Claude Shannon founded the field of information theory. The clever part of this theory is it allows us to separate our measurement of information from what the information pertains to.1
Shannon measured information in bits. One bit of information is the amount of information I pass to you when I give you the result of a coin toss. Shannon was also interested in the amount of information in the English language. He estimated that on average a word in the English language contains 12 bits of information.
Given typical speaking rates, that gives us an estimate of our ability to communicate of around 100 bits per second (Reed and Durlach, 1998). Computers on the other hand can communicate much more rapidly. Current wired network speeds are around a billion bits per second, ten million times faster.
When it comes to compute though, our best estimates indicate our computers are slower. A typical modern computer can process make around 100 billion floating-point operations per second, each floating-point operation involves a 64 bit number. So the computer is processing around 6,400 billion bits per second.
It’s difficult to get similar estimates for humans, but by some estimates the amount of compute we would require to simulate a human brain is equivalent to that in the UK’s fastest computer (Ananthanarayanan et al., 2009), the MET office machine in Exeter, which in 2018 ranked as the 11th fastest computer in the world. That machine simulates the world’s weather each morning, and then simulates the world’s climate in the afternoon. It is a 16-petaflop machine, processing around 1,000 trillion bits per second.

Figure: The Lotus 49, view from the rear. The Lotus 49 was one of the last Formula One cars before the introduction of aerodynamic aids.
So, when it comes to our ability to compute we are extraordinary, not compute in our conscious mind, but the underlying neuron firings that underpin both our consciousness, our subconsciousness as well as our motor control etc.
If we think of ourselves as vehicles, then we are massively overpowered. Our ability to generate derived information from raw fuel is extraordinary. Intellectually we have formula one engines.
But in terms of our ability to deploy that computation in actual use, to share the results of what we have inferred, we are very limited. So, when you imagine the F1 car that represents a psyche, think of an F1 car with bicycle wheels.

Figure: Marcel Renault races a Renault 40 cv during the Paris-Madrid race, an early Grand Prix, in 1903. Marcel died later in the race after missing a warning flag for a sharp corner at Couhé Vérac, likely due to dust reducing visibility.
Just think of the control a driver would have to have to deploy such power through such a narrow channel of traction. That is the beauty and the skill of the human mind.
In contrast, our computers are more like go-karts. Underpowered, but with well-matched tires. They can communicate far more fluidly. They are more efficient, but somehow less extraordinary, less beautiful.

Figure: Caleb McDuff driving for WIX Silence Racing.
For humans, that means much of our computation should be dedicated to considering what we should compute. To do that efficiently we need to model the world around us. The most complex thing in the world around us is other humans. So, it is no surprise that we model them. We second guess what their intentions are, and our communication is only necessary when they are departing from how we model them. Naturally, for this to work well, we need to understand those we work closely with. It is no surprise that social communication, social bonding, forms so much of a part of our use of our limited bandwidth.
There is a second effect here, our need to anthropomorphize objects around us. Our tendency to model our fellow humans extends to when we interact with other entities in our environment. To our pets as well as inanimate objects around us, such as computers or even our cars. This tendency to over interpret could be a consequence of our limited ability to communicate.2
For more details see this paper “Living Together: Mind and Machine Intelligence”, and this TEDx talk and Chapter 1 in Lawrence (2024).
The Centrifugal Governor

Figure: Centrifugal governor as held by “Science” on Holborn Viaduct
Boulton and Watt’s Steam Engine
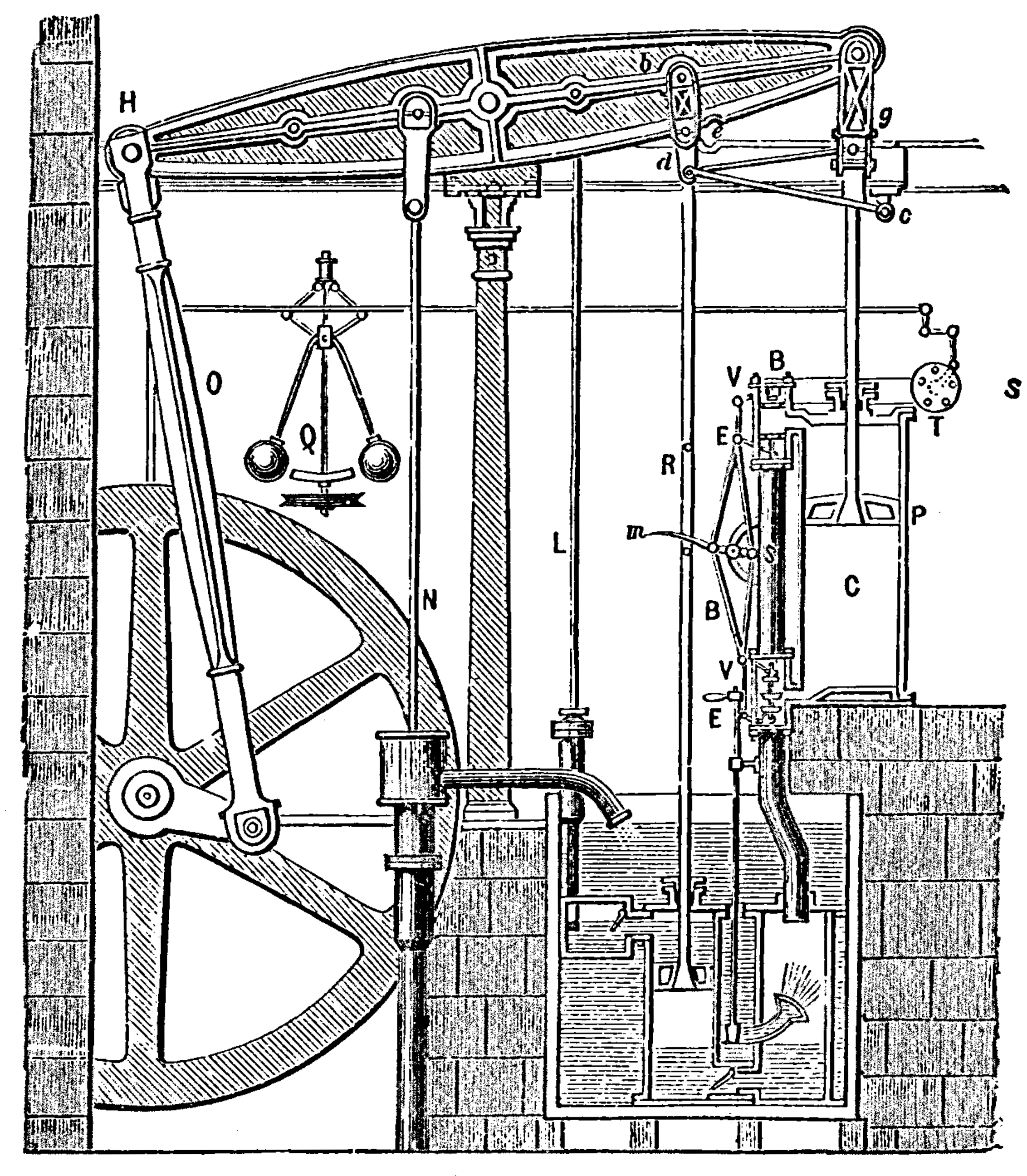
Figure: Watt’s Steam Engine which made Steam Power Efficient and Practical.
James Watt’s steam engine contained an early machine learning device. In the same way that modern systems are component based, his engine was composed of components. One of which is a speed regulator sometimes known as Watt’s governor. The two balls in the center of the image, when spun fast, rise, and through a linkage mechanism.
The centrifugal governor was made famous by Boulton and Watt when it was deployed in the steam engine. Studying stability in the governor is the main subject of James Clerk Maxwell’s paper on the theoretical analysis of governors (Maxwell, 1867). This paper is a founding paper of control theory. In an acknowledgment of its influence, Wiener used the name cybernetics to describe the field of control and communication in animals and the machine (Wiener, 1948). Cybernetics is the Greek word for governor, which comes from the latin for helmsman.
A governor is one of the simplest artificial intelligence systems. It senses the speed of an engine and acts to change the position of the valve on the engine to slow it down.
Although it’s a mechanical system a governor can be seen as automating a role that a human would have traditionally played. It is an early example of artificial intelligence.
The centrifugal governor has several parameters, the weight of the balls used, the length of the linkages and the limits on the balls’ movement.
Two principal differences exist between the centrifugal governor and artificial intelligence systems of today.
- The centrifugal governor is a physical system, and it is an integral part of a wider physical system that it regulates (the engine).
- The parameters of the governor were set by hand, our modern artificial intelligence systems have their parameters set by data.
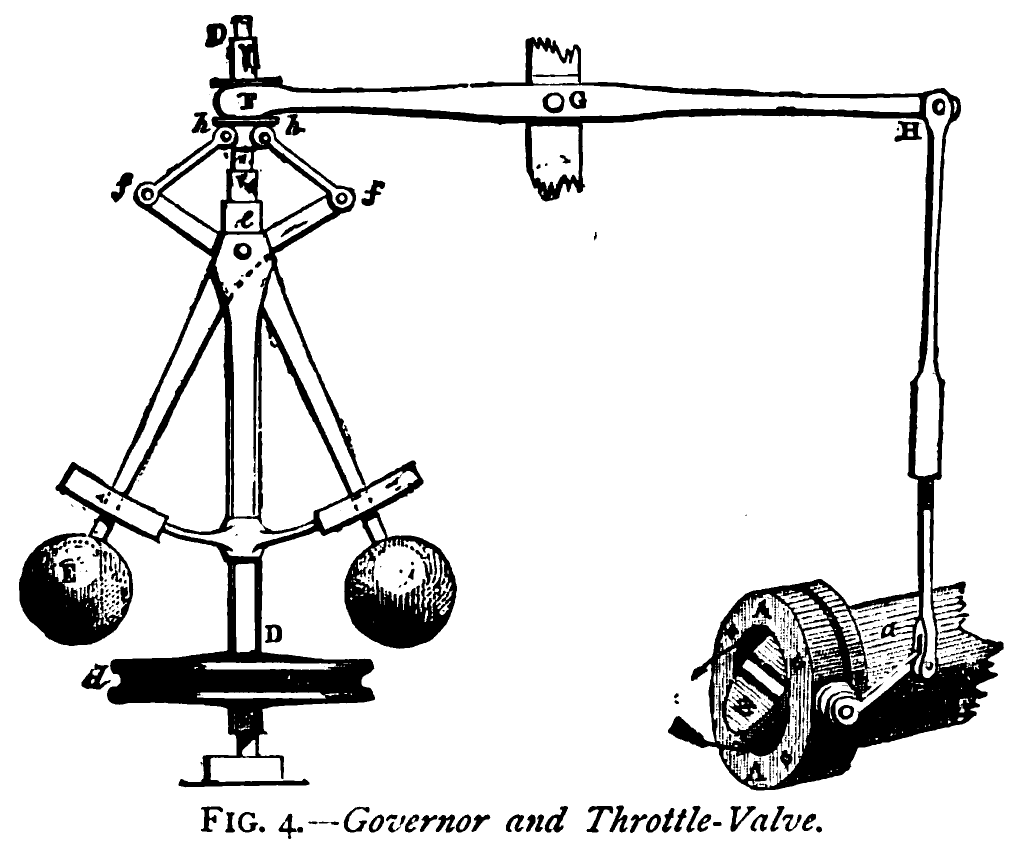
Figure: The centrifugal governor, an early example of a decision-making system. The parameters of the governor include the lengths of the linkages (which effect how far the throttle opens in response to movement in the balls), the weight of the balls (which effects inertia) and the limits of to which the balls can rise.
This has the basic components of sense and act that we expect in an intelligent system, and this system saved the need for a human operator to manually adjust the system in the case of overspeed. Overspeed has the potential to destroy an engine, so the governor operates as a safety device.
The first wave of automation did bring about sabotage as a worker’s response. But if machinery was sabotaged, for example, if the linkage between sensor (the spinning balls) and action (the valve closure) was broken, this would be obvious to the engine operator at start up time. The machine could be repaired before operation.
What is Machine Learning?
Machine learning allows us to extract knowledge from data to form a prediction.
\[\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} \text{prediction}\]
A machine learning prediction is made by combining a model with data to form the prediction. The manner in which this is done gives us the machine learning algorithm.
Machine learning models are mathematical models which make weak assumptions about data, e.g. smoothness assumptions. By combining these assumptions with the data, we observe we can interpolate between data points or, occasionally, extrapolate into the future.
Machine learning is a technology which strongly overlaps with the methodology of statistics. From a historical/philosophical view point, machine learning differs from statistics in that the focus in the machine learning community has been primarily on accuracy of prediction, whereas the focus in statistics is typically on the interpretability of a model and/or validating a hypothesis through data collection.
The rapid increase in the availability of compute and data has led to the increased prominence of machine learning. This prominence is surfacing in two different but overlapping domains: data science and artificial intelligence.
From Model to Decision
The real challenge, however, is end-to-end decision making. Taking information from the environment and using it to drive decision making to achieve goals.
Artificial Intelligence and Data Science
Artificial intelligence has the objective of endowing computers with human-like intelligent capabilities. For example, understanding an image (computer vision) or the contents of some speech (speech recognition), the meaning of a sentence (natural language processing) or the translation of a sentence (machine translation).
Supervised Learning for AI
The machine learning approach to artificial intelligence is to collect and annotate a large data set from humans. The problem is characterized by input data (e.g. a particular image) and a label (e.g. is there a car in the image yes/no). The machine learning algorithm fits a mathematical function (I call this the prediction function) to map from the input image to the label. The parameters of the prediction function are set by minimizing an error between the function’s predictions and the true data. This mathematical function that encapsulates this error is known as the objective function.
This approach to machine learning is known as supervised learning. Various approaches to supervised learning use different prediction functions, objective functions or different optimization algorithms to fit them.
For example, deep learning makes use of neural networks to form the predictions. A neural network is a particular type of mathematical function that allows the algorithm designer to introduce invariances into the function.
An invariance is an important way of including prior understanding in a machine learning model. For example, in an image, a car is still a car regardless of whether it’s in the upper left or lower right corner of the image. This is known as translation invariance. A neural network encodes translation invariance in convolutional layers. Convolutional neural networks are widely used in image recognition tasks.
An alternative structure is known as a recurrent neural network (RNN). RNNs neural networks encode temporal structure. They use auto regressive connections in their hidden layers, they can be seen as time series models which have non-linear auto-regressive basis functions. They are widely used in speech recognition and machine translation.
Machine learning has been deployed in Speech Recognition (e.g. Alexa, deep neural networks, convolutional neural networks for speech recognition), in computer vision (e.g. Amazon Go, convolutional neural networks for person recognition and pose detection).
The field of data science is related to AI, but philosophically different. It arises because we are increasingly creating large amounts of data through happenstance rather than active collection. In the modern era data is laid down by almost all our activities. The objective of data science is to extract insights from this data.
Classically, in the field of statistics, data analysis proceeds by assuming that the question (or scientific hypothesis) comes before the data is created. E.g., if I want to determine the effectiveness of a particular drug, I perform a design for my data collection. I use foundational approaches such as randomization to account for confounders. This made a lot of sense in an era where data had to be actively collected. The reduction in cost of data collection and storage now means that many data sets are available which weren’t collected with a particular question in mind. This is a challenge because bias in the way data was acquired can corrupt the insights we derive. We can perform randomized control trials (or A/B tests) to verify our conclusions, but the opportunity is to use data science techniques to better guide our question selection or even answer a question without the expense of a full randomized control trial (referred to as A/B testing in modern internet parlance).
Deep Learning
DeepFace

Figure: The DeepFace architecture (Taigman et al., 2014), visualized through colors to represent the functional mappings at each layer. There are 120 million parameters in the model.
The DeepFace architecture (Taigman et al., 2014) consists of layers that deal with translation invariances, known as convolutional layers. These layers are followed by three locally-connected layers and two fully-connected layers. Color illustrates feature maps produced at each layer. The neural network includes more than 120 million parameters, where more than 95% come from the local and fully connected layers.
Deep Learning as Pinball

Figure: Deep learning models are composition of simple functions. We can think of a pinball machine as an analogy. Each layer of pins corresponds to one of the layers of functions in the model. Input data is represented by the location of the ball from left to right when it is dropped in from the top. Output class comes from the position of the ball as it leaves the pins at the bottom.
Sometimes deep learning models are described as being like the brain, or too complex to understand, but one analogy I find useful to help the gist of these models is to think of them as being similar to early pin ball machines.
In a deep neural network, we input a number (or numbers), whereas in pinball, we input a ball.
Think of the location of the ball on the left-right axis as a single number. Our simple pinball machine can only take one number at a time. As the ball falls through the machine, each layer of pins can be thought of as a different layer of ‘neurons’. Each layer acts to move the ball from left to right.
In a pinball machine, when the ball gets to the bottom it might fall into a hole defining a score, in a neural network, that is equivalent to the decision: a classification of the input object.
An image has more than one number associated with it, so it is like playing pinball in a hyper-space.
Figure: At initialization, the pins, which represent the parameters of the function, aren’t in the right place to bring the balls to the correct decisions.
Figure: After learning the pins are now in the right place to bring the balls to the correct decisions.
Learning involves moving all the pins to be in the correct position, so that the ball ends up in the right place when it’s fallen through the machine. But moving all these pins in hyperspace can be difficult.
In a hyper-space you have to put a lot of data through the machine for to explore the positions of all the pins. Even when you feed many millions of data points through the machine, there are likely to be regions in the hyper-space where no ball has passed. When future test data passes through the machine in a new route unusual things can happen.
Adversarial examples exploit this high dimensional space. If you have access to the pinball machine, you can use gradient methods to find a position for the ball in the hyper space where the image looks like one thing, but will be classified as another.
Probabilistic methods explore more of the space by considering a range of possible paths for the ball through the machine. This helps to make them more data efficient and gives some robustness to adversarial examples.
Figure: The mechanism by which data moves is changing, it is now mediated by the computer.
Societal Effects
We have already seen the effects of this changed dynamic in biology and computational biology. Improved sensorics have led to the new domains of transcriptomics, epigenomics, and ‘rich phenomics’ as well as considerably augmenting our capabilities in genomics.
Biologists have had to become data-savvy, they require a rich understanding of the available data resources and need to assimilate existing data sets in their hypothesis generation as well as their experimental design. Modern biology has become a far more quantitative science, but the quantitativeness has required new methods developed in the domains of computational biology and bioinformatics.
There is also great promise for personalized health, but in health the wide data-sharing that has underpinned success in the computational biology community is much harder to carry out.
We can expect to see these phenomena reflected in wider society. Particularly as we make use of more automated decision making based only on data. This is leading to a requirement to better understand our own subjective biases to ensure that the human to computer interface allows domain experts to assimilate data driven conclusions in a well calibrated manner. This is particularly important where medical treatments are being prescribed. It also offers potential for different kinds of medical intervention. More subtle interventions are possible when the digital environment is able to respond to users in an bespoke manner. This has particular implications for treatment of mental health conditions.
The main phenomenon we see across the board is the shift in dynamic from the direct pathway between human and data, as traditionally mediated by classical statistics, to a new flow of information via the computer. This change of dynamics gives us the modern and emerging domain of data science, where the interactions between human and data are mediated by the machine.
Human Communication
For human conversation to work, we require an internal model of who we are speaking to. We model each other, and combine our sense of who they are, who they think we are, and what has been said. This is our approach to dealing with the limited bandwidth connection we have. Empathy and understanding of intent. Mental dispositional concepts are used to augment our limited communication bandwidth.
Fritz Heider referred to the important point of a conversation as being that they are happenings that are “psychologically represented in each of the participants” (his emphasis) (Heider, 1958).
Bandwidth Constrained Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Embodiment factors imply that, in our communication between humans, what is not said is, perhaps, more important than what is said. To communicate with each other we need to have a model of who each of us are.
To aid this, in society, we are required to perform roles. Whether as a parent, a teacher, an employee or a boss. Each of these roles requires that we conform to certain standards of behaviour to facilitate communication between ourselves.
Control of self is vitally important to these communications.
The high availability of data available to humans undermines human-to-human communication channels by providing new routes to undermining our control of self.
A Six Word Novel

Figure: Consider the six-word novel, apocryphally credited to Ernest Hemingway, “For sale: baby shoes, never worn”. To understand what that means to a human, you need a great deal of additional context. Context that is not directly accessible to a machine that has not got both the evolved and contextual understanding of our own condition to realize both the implication of the advert and what that implication means emotionally to the previous owner.
But this is a very different kind of intelligence than ours. A computer cannot understand the depth of the Ernest Hemingway’s apocryphal six-word novel: “For Sale, Baby Shoes, Never worn”, because it isn’t equipped with that ability to model the complexity of humanity that underlies that statement.
Heider and Simmel (1944)
Figure: Fritz Heider and Marianne Simmel’s video of shapes from Heider and Simmel (1944).
Fritz Heider and Marianne Simmel’s experiments with animated shapes from 1944 (Heider and Simmel, 1944). Our interpretation of these objects as showing motives and even emotion is a combination of our desire for narrative, a need for understanding of each other, and our ability to empathize. At one level, these are crudely drawn objects, but in another way, the animator has communicated a story through simple facets such as their relative motions, their sizes and their actions. We apply our psychological representations to these faceless shapes to interpret their actions.
See also a recent review paper on Human Cooperation by Henrich and Muthukrishna (2021).
Computer Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Similarly, we find it difficult to comprehend how computers are making decisions. Because they do so with more data than we can possibly imagine.
In many respects, this is not a problem, it’s a good thing. Computers and us are good at different things. But when we interact with a computer, when it acts in a different way to us, we need to remember why.
Just as the first step to getting along with other humans is understanding other humans, so it needs to be with getting along with our computers.
Embodiment factors explain why, at the same time, computers are so impressive in simulating our weather, but so poor at predicting our moods. Our complexity is greater than that of our weather, and each of us is tuned to read and respond to one another.
Their intelligence is different. It is based on very large quantities of data that we cannot absorb. Our computers don’t have a complex internal model of who we are. They don’t understand the human condition. They are not tuned to respond to us as we are to each other.
Embodiment factors encapsulate a profound thing about the nature of humans. Our locked in intelligence means that we are striving to communicate, so we put a lot of thought into what we’re communicating with. And if we’re communicating with something complex, we naturally anthropomorphize them.
We give our dogs, our cats, and our cars human motivations. We do the same with our computers. We anthropomorphize them. We assume that they have the same objectives as us and the same constraints. They don’t.
This means, that when we worry about artificial intelligence, we worry about the wrong things. We fear computers that behave like more powerful versions of ourselves that will struggle to outcompete us.
In reality, the challenge is that our computers cannot be human enough. They cannot understand us with the depth we understand one another. They drop below our cognitive radar and operate outside our mental models.
The real danger is that computers don’t anthropomorphize. They’ll make decisions in isolation from us without our supervision because they can’t communicate truly and deeply with us.
Challenges
The field of data science is rapidly evolving. Different practitioners from different domains have their own perspectives. We identify three broad challenges that are emerging. Challenges which have not been addressed in the traditional sub-domains of data science. The challenges have social implications but require technological advance for their solutions.
- Paradoxes of the Data Society
- Quantifying the Value of Data
- Privacy, loss of control, marginalization
Thanks!
For more information on these subjects and more you might want to check the following resources.
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com
Further Reading
Chapter 8 of Lawrence (2024)
Chapter 1 of Lawrence (2024)