
Abstract
In this lab session we look at setting up a SQL server, creating and populating a database, and making joins between different tables.
The check Session for this Practical is 7th November 2024.
- This practical should prepare you for the course assessment. Ensure that you have a solid understanding of the material, with particular emphasis on the AWS database setup. You should be able to use the same database that you set up here for the final assessment.
- In that assessment, you will work with datasets that require initial setup processes. Start your work on dataset access and database setup early to avoid being blocked from work on subsequent stages later.
- Some tasks will require you to develop skills for searching for multiple solutions and experimenting with different approaches, which lecture content may not cover. This environment closely resembles real-world data science and software engineering challenges, where there might not be a unique correct solution.
Brief History of the Cloud
In the early days of the internet, companies could make use of open source software, such as the Apache web server and the MySQL database for providing on line stores, or other capabilities. But as part of that, they normally had to provide their own server farms. For example, the earliest server for running PageRank from 1996 was hosted on custom made hardware built in a case of Mega Blocks (see Figure \(\ref{the-first-google-computer-at-stanford}\)).


Figure: The web search engine was hosted on custom built hardware. Photo credit Christian Heilmann on Flickr.
By September 2000, Google operated 5000 PCs for searching and web crawling, using the LINUX operating system.1
Cloud computing gives you access to computing at a similar scale, but on an as-needed basis. AWS launched S3 cloud storage in March 2006 and the Elastic Compute Cloud followed in August 2006. These services were inspired by the challenges they had scaling their own web service (known as Obidos) for running the world’s largest e-commerce site. Recent market share estimates indicate that AWS still retains around a third of the cloud infrastructure market.2
UK Housing Datasets
The UK Price Paid data for housing in dates back to 1995 and contains millions of transactions. This database is available at the gov.uk site. The total data is over 4 gigabytes in size and it is available in a single file or in multiple files splitted by years and semester. For example, the first part of the data for 2018 is stored at http://prod.publicdata.landregistry.gov.uk.s3-website-eu-west-1.amazonaws.com/pp-2018-part1.csv. By applying the divide and conquer principle, we will download the splitted data because these files is less than 100MB each which makes them easier to manage.
Let’s download first the two files that contain the price paid data for the transactions that took place in the year 1995:
import requests# Base URL where the dataset is stored
base_url = "http://prod.publicdata.landregistry.gov.uk.s3-website-eu-west-1.amazonaws.com"
# Downloading part 1 from 1995
file_name_part_1 = "/pp-1995-part1.csv"
url = base_url + file_name_part_1
response = requests.get(url)
if response.status_code == 200:
with open("." + file_name_part_1, "wb") as file:
file.write(response.content)
# Downloading part 2 from 1995
file_name_part_2 = "/pp-1995-part2.csv"
url = base_url + file_name_part_2
response = requests.get(url)
if response.status_code == 200:
with open("." + file_name_part_2, "wb") as file:
file.write(response.content)The data is downloaded as CSV files in the files explorer of this notebook. You can see that the two pieces of code that download the data are quite similar. It makes sense to use a for loop to automate the way we access the dataset for the different years. The following code will download the data from 1996 to 2010.
# Base URL where the dataset is stored
base_url = "http://prod.publicdata.landregistry.gov.uk.s3-website-eu-west-1.amazonaws.com"
# File name with placeholders
file_name = "/pp-<year>-part<part>.csv"
for year in range(1996,2011):
print ("Downloading data for year: " + str(year))
for part in range(1,3):
url = base_url + file_name.replace("<year>", str(year)).replace("<part>", str(part))
response = requests.get(url)
if response.status_code == 200:
with open("." + file_name.replace("<year>", str(year)).replace("<part>", str(part)), "wb") as file:
file.write(response.content)If we think of reusability, it would be good to create a function that can be called from anywhere in your code.
import requestsNow we can call the function to download the data between two given years. For example, let’s download the data from 2011 to 2020 by calling the defined function.
download_price_paid_data(2011, 2020)Exercise 1
Add this function to your fynesse library and download the data from 2021 to 2024 using your library.
Cloud Hosted Database
The size of the data makes it unwieldy to manipulate directly in
python frameworks such as pandas. As a result we will host
and access the data in a relational database.
Using the following ideas: 1. A cloud hosted database (such as MariaDB hosted on the AWS RDS service). 2. SQL code wrapped in appropriately structured python functions. 3. Joining databases tables. You will construct a database containing tables that contain all house prices, latitudes and longitudes from the UK house price data base since 1995.
Important Notes
You will manipulate large datasets along this practical and the final assessment. If your database is blocked or is not responsive after any operation, have a look at the databases dashboard to see if it is using too much CPU. Reboot the database if that is the case. If you encounter problems with the online notebook (e.g., interrupted connections with the AWS server), you can use a local IDE to work in your machine.
SQL Database Server
A typical machine learning installation might have you running a
database from a cloud service (such as AWS, Azure or Google Cloud
Platform). That cloud service would host the database for you, and you
would pay according to the number of queries made. Popular SQL server
software includes [MariaDB] https://mariadb.org/) which is
open source, or Microsoft’s
SQL Server.
Many start-up companies were formed on the back of a
MySQL server hosted on top of AWS. Although since MySQL was
sold to Sun, and then passed on to Oracle, the open source community has
turned its attention to MariaDB, here’s the AWS
instructions on how to set up MariaDB.
If you were designing your own ride hailing app, or any other major commercial software you would want to investigate whether you would need to set up a central SQL server in one of these frameworks.
Creating a MariaDB Server on AWS
In this section, we’ll review the setup required to create a MariaDB
server on AWS. The earliest AWS services of S3 and EC2 gave storage and
compute. Together these could be combined to host a database service.
Today cloud providers also provide machines that are already set up to
provide a database service. We will make use of AWS’s Relational
Database Service to provide our MariaDB server.
- Log in to your AWS account and go to the AWS RDS console here.
- Make sure the region is set to Europe (London) which is denoted as eu-west-2.
- Scroll down to “Create Database”. Do not create an Aurora database instance.
Standard Createshould be selected. In the box below, which is titledEngine Optionsyou should selectMariaDB. You can leave theVersionas it’s set.
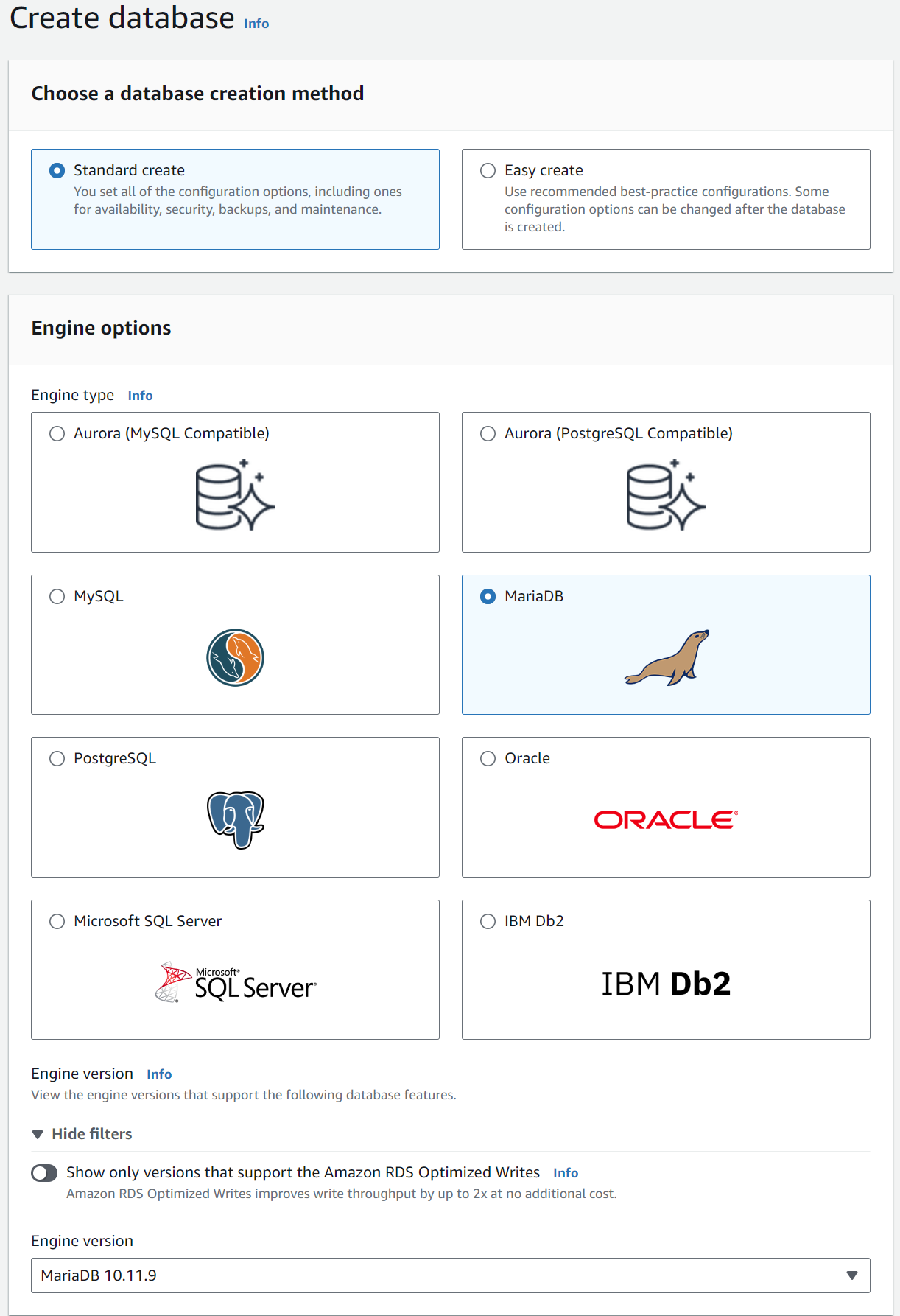
Figure: The AWS console box for selecting the MariaDB
engine.
- In the box below that, make sure you select
Free tier.
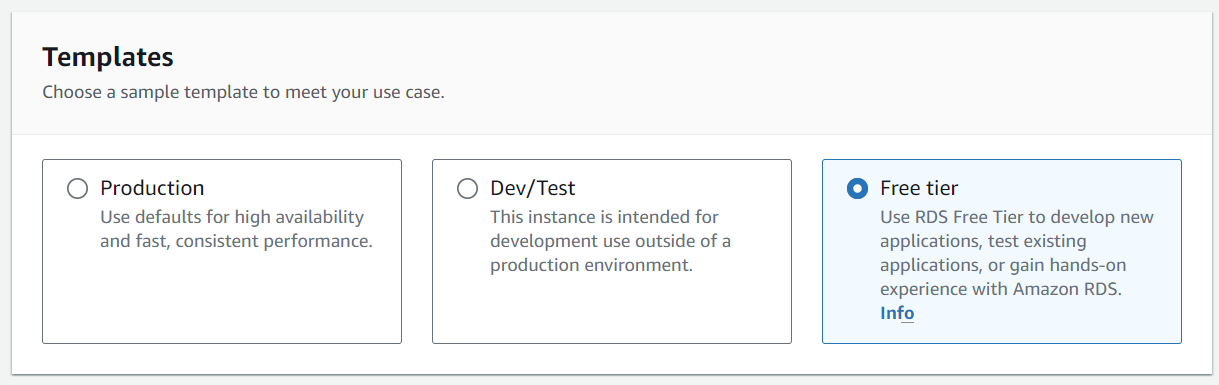
Figure: Make sure you select the free tier option for your database server.
- Name your database server. For your setup we suggest you use
database-ads-<CRSid>for the name.<CRSid>corresponds to your CRSid. So, every student has an independent database. - Set a master password for accessing the database server as admin.
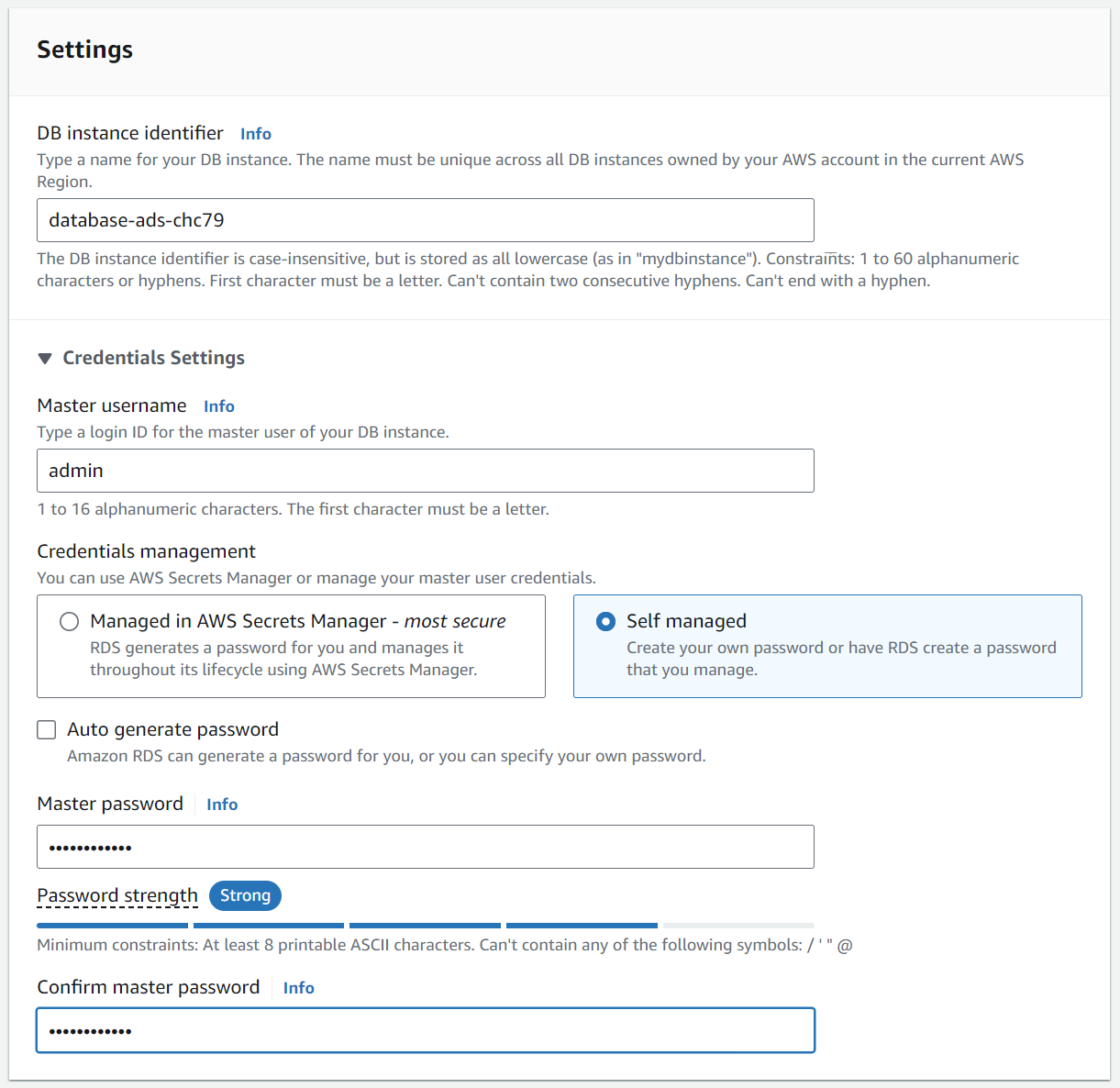
Figure: Set the password and username for the database server access.
- Leave the
DB instance classas it is. - Leave the
DB instance sizeat the default setting. Leave the storage type and allocated storage at the default settings ofGeneral Purpose(SSD) and20. - Disable autoscaling in the
Storage Autoscalingoption. - In the connectivity leave the VPC selection as
Default VPCand enablePublicly accessibleso that you’ll have an IP address for your database. - In
VPC security groupselectCreate newto create a new security group for the instance. - Write
ADSMariaDBas the group name for the VPC security group. - Leave the rest as it is and select
Create databaseat the bottom to launch the database server.
Your database server will take a few minutes to launch.
While it’s launching you can check the access rules for the database server here.
- Select the
Defaultsecurity group. - The source of the active inbound rule must be set to
0.0.0.0/0. It means you can connect from any source using IPv4.
A wrong inbound rule can cause you fail connecting to the database from this notebook.
Note: by setting the inbound rule to 0.0.0.0/0
we have opened up access to any IP address. If this were
production code you wouldn’t do this, you would specify a range of
addresses or the specific address of the compute server that needed to
access the system. Because we’re using Google colab or another notebook
client to access, and we can’t control the IP address of that access,
for simplicity we’ve set it up so that any IP address can access the
database, but that is not good practice for production
systems.
Connecting to your Database Server
Before you start, you’re going to need the username and password you
set-up above for accessing the database server. You will need to make
use of it when your client connects to the server. It’s good practice to
never expose passwords in your code directly. So to protect your
passowrd, we’re going to create a credentials.yaml file
locally that will store your username and password so that the client
can access the server without ever showing your password in the
notebook. This file will also score the URL and port of your database.
You can get these details from your database connectivity and security
details.
import yaml
from ipywidgets import interact_manual, Text, PasswordIf you click Run Interact then the credentials you’ve
selected will be saved in the yaml file.
Then, we can read the server credentials using:
with open("credentials.yaml") as file:
credentials = yaml.safe_load(file)
username = credentials["username"]
password = credentials["password"]
url = credentials["url"]
port = credentials["port"]SQL Commands
We have all the required data to interact with our database server. There are mainly two ways how we can do that. The first one is using magic SQL commands. For this option, we need to install pymysql and load the sql extension:
%pip install pymysql%load_ext sqlWe can now test our first database server connection using magic SQL. The first line establishes the connection and the second one list the databases. For now, you should see the databases that the engine has installed by default.
%sql mariadb+pymysql://$username:$password@$url?local_infile=1
%sql SHOW databasesThis connection also enables the uploading of local files as part of
the connection (i.e., local_infile=1). We will use this
property later.
Database Schema
As a first step after establishing a connection, we should create our own database in the server. We will use this relational database to store, structure, and access the different datasets we will manipulate during this course. We will use SQL code for this and once again magic commands:
%%sql
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
CREATE DATABASE IF NOT EXISTS `ads_2024` DEFAULT CHARACTER SET utf8 COLLATE utf8_bin;%sql SHOW databasesAfter the database is created in our server, we must tell it which database we will use. You will need to run this command after you create a new connection:
%%sql
USE `ads_2024`;A database is composed of tables where data records are stored in
rows. The attributes of each record are the columns. We must define an
schema to create a table in a database. The
schema tells the database and the server what to expect in
the columns of the table (i.e., names and data types of the
columns).
The schema is defined by the data we want to store. If
we want to store the UK Price Paid data, we should have a look at its
description first. Also, we should a look at the data. Let’s do that
for the second semester of 2021.
import pandas as pdfile_name = "./pp-2021-part2.csv"
data = pd.read_csv(file_name)
data.info(verbose=True)Based on the columns of the dataframe, we should define now the
equivalent schema of the table in the SQL database. We will
use once more SQL magic commands to create a table with the equivalent
schema:
# WARNING: If you run this command after you have uploaded data to the table (in the steps below), you will delete the uploaded data as this command first drops the table if exists (DROP TABLE IF EXISTS `pp_data`;).
%%sql
--
-- Table structure for table `pp_data`
--
USE `ads_2024`;
DROP TABLE IF EXISTS `pp_data`;
CREATE TABLE IF NOT EXISTS `pp_data` (
`transaction_unique_identifier` tinytext COLLATE utf8_bin NOT NULL,
`price` int(10) unsigned NOT NULL,
`date_of_transfer` date NOT NULL,
`postcode` varchar(8) COLLATE utf8_bin NOT NULL,
`property_type` varchar(1) COLLATE utf8_bin NOT NULL,
`new_build_flag` varchar(1) COLLATE utf8_bin NOT NULL,
`tenure_type` varchar(1) COLLATE utf8_bin NOT NULL,
`primary_addressable_object_name` tinytext COLLATE utf8_bin NOT NULL,
`secondary_addressable_object_name` tinytext COLLATE utf8_bin NOT NULL,
`street` tinytext COLLATE utf8_bin NOT NULL,
`locality` tinytext COLLATE utf8_bin NOT NULL,
`town_city` tinytext COLLATE utf8_bin NOT NULL,
`district` tinytext COLLATE utf8_bin NOT NULL,
`county` tinytext COLLATE utf8_bin NOT NULL,
`ppd_category_type` varchar(2) COLLATE utf8_bin NOT NULL,
`record_status` varchar(2) COLLATE utf8_bin NOT NULL,
`db_id` bigint(20) unsigned NOT NULL
) DEFAULT CHARSET=utf8 COLLATE=utf8_bin AUTO_INCREMENT=1 ;The schema defines an id field in the table (i.e.,
db_id), which must be unique and will play the role of primary
key, which is a crucial concept in relational databases. The
following code sets up the primary key for our table and makes it auto
increment when a new row (i.e., record) is insterted into the table.
%%sql
--
-- Primary key for table `pp_data`
--
ALTER TABLE `pp_data`
ADD PRIMARY KEY (`db_id`);
ALTER TABLE `pp_data`
MODIFY db_id bigint(20) unsigned NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=1;We’ve created our first table in the database with its respective
primary key. Now we need to populate it. There are different methods to
do that. Some
of them more efficient than others. In our case, given the size of
our data set, we will take advantage of the csv files we downloaded in
the first part of this lab. The command
LOAD DATA LOCAL INFILE allows uploading data to the table
from a CSV file. We must specify the name of the local file, the name of
the table, and the format of the CSV file we want to use (i.e.,
separators, enclosers, termination line characters, etc.)
The following command uploads the data of the transactions that took place in 1995.
%sql USE `ads_2024`;
%sql LOAD DATA LOCAL INFILE "./pp-1995-part1.csv" INTO TABLE `pp_data` FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED by '"' LINES STARTING BY '' TERMINATED BY '\n';
%sql LOAD DATA LOCAL INFILE "./pp-1995-part2.csv" INTO TABLE `pp_data` FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED by '"' LINES STARTING BY '' TERMINATED BY '\n';If we want to upload the data for all the years, we will need a command for each CSV in our dataset. Alternatively, we can use Python code together with SQL magic commands as follows:
# WARNING: This code will take a long time to finish (i.e., more than 30 minutes) given our dataset's size. The print informs the uploading progress by year.
for year in range(1996,2025):
print ("Uploading data for year: " + str(year))
for part in range(1,3):
file_name = "./pp-" + str(year) + "-part" + str(part) + ".csv"
%sql LOAD DATA LOCAL INFILE "$file_name" INTO TABLE `pp_data` FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED by '"' LINES STARTING BY '' TERMINATED BY '\n';Now that we uploaded the data, we can retrieve it from the table. We
can select the first 5 elements in the pp_data using this
command:
%%sql
USE `ads_2024`;
SELECT * FROM `pp_data` LIMIT 5;We can also count the number of rows in our table. It can take more than 5 minutes to finish. There are almost 30 million of records in the dataset.
%sql select count(*) from `pp_data`;Postal Codes Dataset
The UK Price Paid dataset is now available in our database. This dataset provides useful information about the housing transactions in the UK. More complete analysis can be enabled if we join it with additional datasets. That is the goal of the rest of this practical. The Open Postcode Geo provides additional information about the houses. It is a dataset of British postcodes with easting, northing, latitude, and longitude and with additional fields for geospace applications, including postcode area, postcode district, postcode sector, incode, and outcode.
Your task now is to make this dataset available and accessible in our database. The data you need can be found at this url: https://www.getthedata.com/downloads/open_postcode_geo.csv.zip. It will need to be unzipped before use.
You may find the following schema useful for the postcode data (developed by Christian and Neil)
%%sql
--
-- Table structure for table `postcode_data`
--
DROP TABLE IF EXISTS `postcode_data`;
CREATE TABLE IF NOT EXISTS `postcode_data` (
`postcode` varchar(8) COLLATE utf8_bin NOT NULL,
`status` enum('live','terminated') NOT NULL,
`usertype` enum('small', 'large') NOT NULL,
`easting` int unsigned,
`northing` int unsigned,
`positional_quality_indicator` int NOT NULL,
`country` enum('England', 'Wales', 'Scotland', 'Northern Ireland', 'Channel Islands', 'Isle of Man') NOT NULL,
`latitude` decimal(11,8) NOT NULL,
`longitude` decimal(10,8) NOT NULL,
`postcode_no_space` tinytext COLLATE utf8_bin NOT NULL,
`postcode_fixed_width_seven` varchar(7) COLLATE utf8_bin NOT NULL,
`postcode_fixed_width_eight` varchar(8) COLLATE utf8_bin NOT NULL,
`postcode_area` varchar(2) COLLATE utf8_bin NOT NULL,
`postcode_district` varchar(4) COLLATE utf8_bin NOT NULL,
`postcode_sector` varchar(6) COLLATE utf8_bin NOT NULL,
`outcode` varchar(4) COLLATE utf8_bin NOT NULL,
`incode` varchar(3) COLLATE utf8_bin NOT NULL,
`db_id` bigint(20) unsigned NOT NULL
) DEFAULT CHARSET=utf8 COLLATE=utf8_bin;And again you’ll want to set up a primary key for the new table.
%%sql
ALTER TABLE `postcode_data`
ADD PRIMARY KEY (`db_id`);
ALTER TABLE `postcode_data`;
MODIFY `db_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,AUTO_INCREMENT=1;Exercise 2
Upload the postcode dataset to your database using the LOAD DATA LOCAL INFILE command.
Joining Tables
When we have two tables with data tha describe the same object, then
it makes sense to join the tables together to enrich our knowledge about
the object. For example, while the pp_data tell us about
the transactions a house have been involved, the
postcode_data tell us details about the location of the
house. By joining both, we could answer more interesting questions like
what are the coordinates of the most expensive house in 2024?
The join of the tables must be done by matching the columns the
tables share. In this case, the pp_data and the
postcode_data tables share the column
postcode. This operation can take long time because the
number of records in each database is huge.
You will find the issue of operations taking too long when handling
large data sets in different scenarios. An appropriate strategy to
overcome such issues is to index the tables. Indexing is a way to
organise the data so the queries are more efficient time-wise. Now the
task is to select the right columns to create the index. This decision
depends on the columns we are using in the SQL operations. In the join
case, we are selecting and matching records in each table using the
postcode column. It makes sense then to create an index for
these columns. The following code indexes the table pp_data
by postcode.
# WARNING: Giving the size of the table, this operation takes around 8 minutes.
# If your database is not responsive, check the status of your database on the AWS dashboard. You can restart the database from the dashboard.
%%sql
USE `ads_2024`;
CREATE INDEX idx_pp_postcode ON pp_data(postcode);Let’s try our join the tables for year 2024 now:
%%sql
USE `ads_2024`;
select * from pp_data as pp inner join postcode_data as po on pp.postcode = po.postcode where pp.date_of_transfer BETWEEN '2024-01-01' AND '2024-12-31' limit 5;Exercise 3
The index made a difference in the time the join operation took to
finish. Write the code to index the table postcode_data by
postcode.
And, let’s try the join again:
%%sql
USE `ads_2024`;
select * from pp_data as pp inner join postcode_data as po on pp.postcode = po.postcode where pp.date_of_transfer BETWEEN '2024-01-01' AND '2024-12-31' limit 5;Exercise 4
Do you see any difference after adding the new index? Why?
Database Python Client
Now let’s focus on the second way of interacting with the database server. We can use Python code to create a client that communicates with our database server. For this, we need to install the following libraries.
%pip install ipython-sql%pip install PyMySQLLet’s create a method in Python to establish a database connection wherever we like. It should look like the following code:
import pymysqlPlease add the code above to your fynesse library. We can now call this function to get a connection:
#Write your code to establish a connection using your fynesee libraryNow let’s define a Python method that uploads to a table the data
product of the join operation between the tables pp_data
and postcode_data. For this, we first need to create the
table that will store this data.
%%sql
USE `ads_2024`;
--
-- Table structure for table `prices_coordinates_data`
--
DROP TABLE IF EXISTS `prices_coordinates_data`;
CREATE TABLE IF NOT EXISTS `prices_coordinates_data` (
`price` int(10) unsigned NOT NULL,
`date_of_transfer` date NOT NULL,
`postcode` varchar(8) COLLATE utf8_bin NOT NULL,
`property_type` varchar(1) COLLATE utf8_bin NOT NULL,
`new_build_flag` varchar(1) COLLATE utf8_bin NOT NULL,
`tenure_type` varchar(1) COLLATE utf8_bin NOT NULL,
`locality` tinytext COLLATE utf8_bin NOT NULL,
`town_city` tinytext COLLATE utf8_bin NOT NULL,
`district` tinytext COLLATE utf8_bin NOT NULL,
`county` tinytext COLLATE utf8_bin NOT NULL,
`country` enum('England', 'Wales', 'Scotland', 'Northern Ireland', 'Channel Islands', 'Isle of Man') NOT NULL,
`latitude` decimal(11,8) NOT NULL,
`longitude` decimal(10,8) NOT NULL,
`db_id` bigint(20) unsigned NOT NULL
) DEFAULT CHARSET=utf8 COLLATE=utf8_bin AUTO_INCREMENT=1 ;We should define the primary key for this table too.
%%sql
ALTER TABLE `prices_coordinates_data`
ADD PRIMARY KEY (`db_id`);
ALTER TABLE `prices_coordinates_data`
MODIFY `db_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,AUTO_INCREMENT=1;Indexing the table pp_data by date will be useful for
populating the prices_coordinates_data. This index can take
around 8 minutes to finish.
%%sql
USE `ads_2024`;
CREATE INDEX idx_pp_date_transfer ON pp_data(date_of_transfer);Now that the table exists in our database, let’s create a method for uploading the join data. This method will upload the data for a given year and will use the logic we have used before but in Python code.
import csvimport timeNow, lets upload the joined data for 2024. This upload is going to take long time given the size of our datasets:
housing_upload_join_data(conn, 2024)Exercise 5
Add the housing_upload_join_data function to your
fynesse library and write the code to upload the joined data for
2023.
To finalise this lab, let’s have a look at the structure of your database running the following code:
tables = %sql SHOW TABLES;
for row in tables:
table_name = row[0]
print(f"\nTable: {table_name}")
table_status = %sql SHOW TABLE STATUS LIKE '{table_name}';
approx_row_count = table_status[0][4] if table_status else 'Unable to fetch row count'
print("\nApprox Row Count:", approx_row_count//100000/10, "M")
first_5_rows = %sql SELECT * FROM `{table_name}` LIMIT 5;
print(first_5_rows)
indices = %sql SHOW INDEX FROM `{table_name}`;
if indices:
print("\nIndices:")
for index in indices:
print(f" - {index[2]} ({index[10]}): Column {index[4]}")
else:
print("\nNo indices set on this table.")Exercise 6
Write the output of the above code:
Summary
In this practical, we have explored how to persist a couple of
datasets in a relational database to facilitate future access. We
configured a Cloud-hosted database server and had a look at two ways to
interact with it. Then, we explored how to join tables using SQL and the
benefits of indexing. The tables you created in this practical will be
used along the course and we expect you use them for your final
assignment. In the following practical, you will assess
this data using different methods from visualisations to statistical
analysis.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com